 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-agent Collaboration with State Management
May 19, 2026Recent advances in multi-agent systems have shown great potential for solving complex tasks. However, when multiple agents edit a shared codebase concurrently, their changes can silently conflict and inconsistent views lead to integration failures. Existing multi-agent systems address this through workspace isolation (e.g., one git worktree per agent), but this defers conflict resolution to a post-hoc merge step where recovery is expensive. In this paper, we propose STORM, i.e., STate-ORiented Management for multi-agent collaboration. Specifically, STORM manages agent states by mediating their interactions with the shared workspace, ensuring that each agent operates on a consistent view of the codebase and that conflicting edits are detected and resolved at write time. We evaluate STORM on Commit0 and PaperBench across multiple LLMs. STORM outperforms the git-worktree-based multi-agent baseline by +18.7 on Commit0-Lite and +1.4 on PaperBench, while achieving comparable or better cost efficiency. Combined with single-agent runs, STORM reaches highest scores of 87.6 and 78.2 on the two benchmarks respectively, suggesting that explicit state management is a more effective foundation for multi-agent collaboration than workspace isolation. STORM can also be plugged into any multi-agent system seamlessly.
Evolving-RL: End-to-End Optimization of Experience-Driven Self-Evolving Capability within Agents
May 11, 2026Experience-driven self-evolving agents aim to overcome the static nature of large language models by distilling reusable experience from past interactions, thus enabling adaptation to novel tasks at deployment time. This process places substantial demands on the foundation model's capacities for abstraction, generalization, and in-context learning. However, most existing studies focus primarily on system-level design choices, such as how experience is represented and managed, neglecting the inherent capabilities of the underlying model. While some recent works have started to optimize the experience utilization stage via reinforcement learning, they still fail to treat self-evolution as a unified process to be jointly optimized. To this end, we propose Evolving-RL, an efficient algorithmic framework that jointly improves the experience extraction and utilization capabilities required for self-evolution. Specifically, we center the learning process on experience extraction and evaluation, using the two supervisory signals derived from evaluation to optimize the extractor and solver separately and thus enable their coordinated co-evolution. Experiments on ALFWorld and Mind2Web show that Evolving-RL effectively enhances LLMs' ability to extract and reuse experience, leading to strong performance gains on out-of-distribution tasks (up to 98.7% relative improvement over the GRPO baseline on ALFWorld unseen tasks and 35.8% on Mind2Web), and these gains are fully unlocked only through the coordinated co-evolution of experience extraction and utilization. Furthermore, Evolving-RL inherently functions as an experience-augmented RL algorithm. By internalizing reusable experience patterns directly into model parameters, it achieves remarkable performance gains over standard baselines on both seen and unseen tasks, even in the absence of test-time experience accumulation.
TACT: Mitigating Overthinking and Overacting in Coding Agents via Activation Steering
May 07, 2026When language model agents tackle complex software engineering tasks, they often degrade over long trajectories, which we define as *agent drift*. We focus on two recurring failure modes *overthinking* and *overacting*, i.e., where the agent repeatedly reasons over information it already has, and where it issues tool calls without integrating recent observations or acquiring new evidence. In this paper, we introduce TACT (Think-Act Calibration via activation Steering), to detect and mitigate agent drift in the residual stream before it surfaces as a behavioral failure. In specific, we label trajectory steps as overthinking, overacting, or calibrated, and find that their hidden states can separate linearly along two *drift axes*, pointing from calibrated behavior toward each failure mode (AUC $\approx$ 0.9). To mitigate agent drift, we project each step's activation onto these axes at test time and pull drifted ones back toward the calibrated region. Experiments show that TACT outperforms unsteered baselines across SWE-bench Verified, Terminal-Bench 2.0, and CLAW-Eval, lifting average resolve rate by $+5.8$ pp on Qwen3.5-27B and $+4.8$ pp on Gemma-4-26B-A4B-it while cutting steps-to-resolve by up to $26\%$. These gains frame agent drift as a steerable direction in the residual stream, and position TACT as a viable handle for reliable long-horizon agents.
Evaluating the Formal Reasoning Capabilities of Large Language Models through Chomsky Hierarchy
Apr 03, 2026The formal reasoning capabilities of LLMs are crucial for advancing automated software engineering. However, existing benchmarks for LLMs lack systematic evaluation based on computation and complexity, leaving a critical gap in understanding their formal reasoning capabilities. Therefore, it is still unknown whether SOTA LLMs can grasp the structured, hierarchical complexity of formal languages as defined by Computation Theory. To address this, we introduce ChomskyBench, a benchmark for systematically evaluating LLMs through the lens of Chomsky Hierarchy. Unlike prior work that uses vectorized classification for neural networks, ChomskyBench is the first to combine full Chomsky Hierarchy coverage, process-trace evaluation via natural language, and deterministic symbolic verifiability. ChomskyBench is composed of a comprehensive suite of language recognition and generation tasks designed to test capabilities at each level. Extensive experiments indicate a clear performance stratification that correlates with the hierarchy's levels of complexity. Our analysis reveals a direct relationship where increasing task difficulty substantially impacts both inference length and performance. Furthermore, we find that while larger models and advanced inference methods offer notable relative gains, they face severe efficiency barriers: achieving practical reliability would require prohibitive computational costs, revealing that current limitations stem from inefficiency rather than absolute capability bounds. A time complexity analysis further indicates that LLMs are significantly less efficient than traditional algorithmic programs for these formal tasks. These results delineate the practical limits of current LLMs, highlight the indispensability of traditional software tools, and provide insights to guide the development of future LLMs with more powerful formal reasoning capabilities.
Think Anywhere in Code Generation
Apr 02, 2026Recent advances in reasoning Large Language Models (LLMs) have primarily relied on upfront thinking, where reasoning occurs before final answer. However, this approach suffers from critical limitations in code generation, where upfront thinking is often insufficient as problems' full complexity only reveals itself during code implementation. Moreover, it cannot adaptively allocate reasoning effort throughout the code generation process where difficulty varies significantly. In this paper, we propose Think-Anywhere, a novel reasoning mechanism that enables LLMs to invoke thinking on-demand at any token position during code generation. We achieve Think-Anywhere by first teaching LLMs to imitate the reasoning patterns through cold-start training, then leveraging outcome-based RL rewards to drive the model's autonomous exploration of when and where to invoke reasoning. Extensive experiments on four mainstream code generation benchmarks (i.e., LeetCode, LiveCodeBench, HumanEval, and MBPP) show that Think-Anywhere achieves state-of-the-art performance over both existing reasoning methods and recent post-training approaches, while demonstrating consistent generalization across diverse LLMs. Our analysis further reveals that Think-Anywhere enables the model to adaptively invoke reasoning at high-entropy positions, providing enhanced interpretability.
Do Transformers Have the Ability for Periodicity Generalization?
Jan 30, 2026Large language models (LLMs) based on the Transformer have demonstrated strong performance across diverse tasks. However, current models still exhibit substantial limitations in out-of-distribution (OOD) generalization compared with humans. We investigate this gap through periodicity, one of the basic OOD scenarios. Periodicity captures invariance amid variation. Periodicity generalization represents a model's ability to extract periodic patterns from training data and generalize to OOD scenarios. We introduce a unified interpretation of periodicity from the perspective of abstract algebra and reasoning, including both single and composite periodicity, to explain why Transformers struggle to generalize periodicity. Then we construct Coper about composite periodicity, a controllable generative benchmark with two OOD settings, Hollow and Extrapolation. Experiments reveal that periodicity generalization in Transformers is limited, where models can memorize periodic data during training, but cannot generalize to unseen composite periodicity. We release the source code to support future research.
KOCO-BENCH: Can Large Language Models Leverage Domain Knowledge in Software Development?
Jan 19, 2026Large language models (LLMs) excel at general programming but struggle with domain-specific software development, necessitating domain specialization methods for LLMs to learn and utilize domain knowledge and data. However, existing domain-specific code benchmarks cannot evaluate the effectiveness of domain specialization methods, which focus on assessing what knowledge LLMs possess rather than how they acquire and apply new knowledge, lacking explicit knowledge corpora for developing domain specialization methods. To this end, we present KOCO-BENCH, a novel benchmark designed for evaluating domain specialization methods in real-world software development. KOCO-BENCH contains 6 emerging domains with 11 software frameworks and 25 projects, featuring curated knowledge corpora alongside multi-granularity evaluation tasks including domain code generation (from function-level to project-level with rigorous test suites) and domain knowledge understanding (via multiple-choice Q&A). Unlike previous benchmarks that only provide test sets for direct evaluation, KOCO-BENCH requires acquiring and applying diverse domain knowledge (APIs, rules, constraints, etc.) from knowledge corpora to solve evaluation tasks. Our evaluations reveal that KOCO-BENCH poses significant challenges to state-of-the-art LLMs. Even with domain specialization methods (e.g., SFT, RAG, kNN-LM) applied, improvements remain marginal. Best-performing coding agent, Claude Code, achieves only 34.2%, highlighting the urgent need for more effective domain specialization methods. We release KOCO-BENCH, evaluation code, and baselines to advance further research at https://github.com/jiangxxxue/KOCO-bench.
EvoCoT: Overcoming the Exploration Bottleneck in Reinforcement Learning
Aug 11, 2025Reinforcement learning with verifiable reward (RLVR) has become a promising paradigm for post-training large language models (LLMs) to improve their reasoning capability. However, when the rollout accuracy is low on hard problems, the reward becomes sparse, limiting learning efficiency and causing exploration bottlenecks. Existing approaches either rely on stronger LLMs for distillation or filter out difficult problems, which limits scalability or restricts reasoning improvement through exploration. We propose EvoCoT, a self-evolving curriculum learning framework based on two-stage chain-of-thought (CoT) reasoning optimization. EvoCoT constrains the exploration space by self-generating and verifying CoT trajectories, then gradually shortens them to expand the space in a controlled way. This enables LLMs to stably learn from initially unsolved hard problems under sparse rewards. We apply EvoCoT to multiple LLM families, including Qwen, DeepSeek, and Llama. Experiments show that EvoCoT enables LLMs to solve previously unsolved problems, improves reasoning capability without external CoT supervision, and is compatible with various RL fine-tuning methods. We release the source code to support future research.
A Survey on Code Generation with LLM-based Agents
Jul 31, 2025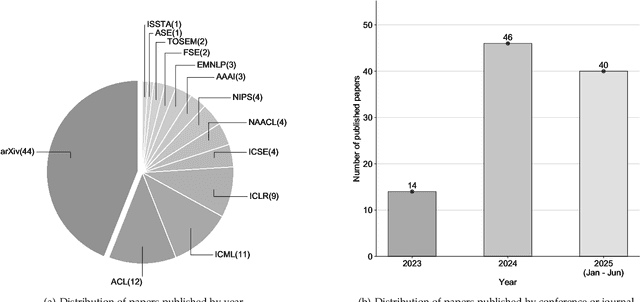
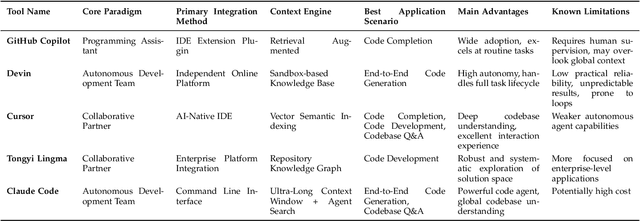
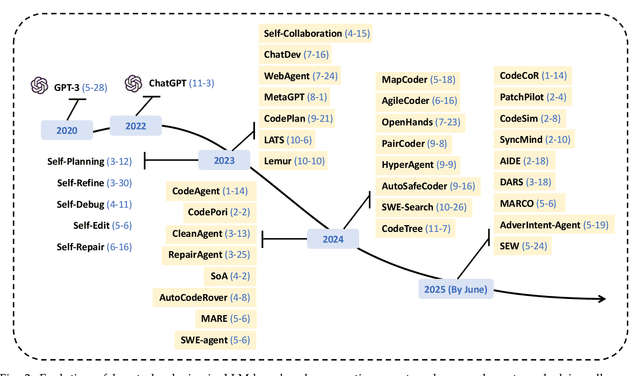
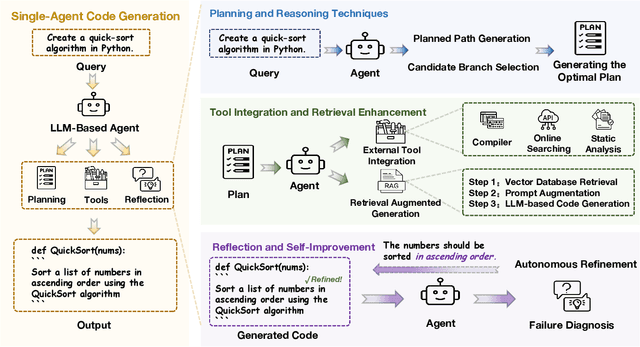
Code generation agents powered by large language models (LLMs) are revolutionizing the software development paradigm. Distinct from previous code generation techniques, code generation agents are characterized by three core features. 1) Autonomy: the ability to independently manage the entire workflow, from task decomposition to coding and debugging. 2) Expanded task scope: capabilities that extend beyond generating code snippets to encompass the full software development lifecycle (SDLC). 3) Enhancement of engineering practicality: a shift in research emphasis from algorithmic innovation toward practical engineering challenges, such as system reliability, process management, and tool integration. This domain has recently witnessed rapid development and an explosion in research, demonstrating significant application potential. This paper presents a systematic survey of the field of LLM-based code generation agents. We trace the technology's developmental trajectory from its inception and systematically categorize its core techniques, including both single-agent and multi-agent architectures. Furthermore, this survey details the applications of LLM-based agents across the full SDLC, summarizes mainstream evaluation benchmarks and metrics, and catalogs representative tools. Finally, by analyzing the primary challenges, we identify and propose several foundational, long-term research directions for the future work of the field.
RL-PLUS: Countering Capability Boundary Collapse of LLMs in Reinforcement Learning with Hybrid-policy Optimization
Jul 31, 2025Reinforcement Learning with Verifiable Reward (RLVR) has significantly advanced the complex reasoning abilities of Large Language Models (LLMs). However, it struggles to break through the inherent capability boundaries of the base LLM, due to its inherently on-policy strategy with LLM's immense action space and sparse reward. Further, RLVR can lead to the capability boundary collapse, narrowing the LLM's problem-solving scope. To address this problem, we propose RL-PLUS, a novel approach that synergizes internal exploitation (i.e., Thinking) with external data (i.e., Learning) to achieve stronger reasoning capabilities and surpass the boundaries of base models. RL-PLUS integrates two core components: Multiple Importance Sampling to address for distributional mismatch from external data, and an Exploration-Based Advantage Function to guide the model towards high-value, unexplored reasoning paths. We provide both theoretical analysis and extensive experiments to demonstrate the superiority and generalizability of our approach. The results show that RL-PLUS achieves state-of-the-art performance compared with existing RLVR methods on six math reasoning benchmarks and exhibits superior performance on six out-of-distribution reasoning tasks. It also achieves consistent and significant gains across diverse model families, with average relative improvements ranging from 21.1\% to 69.2\%. Moreover, Pass@k curves across multiple benchmarks indicate that RL-PLUS effectively resolves the capability boundary collapse problem.