 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
DevEval: A Manually-Annotated Code Generation Benchmark Aligned with Real-World Code Repositories
May 30, 2024How to evaluate the coding abilities of Large Language Models (LLMs) remains an open question. We find that existing benchmarks are poorly aligned with real-world code repositories and are insufficient to evaluate the coding abilities of LLMs. To address the knowledge gap, we propose a new benchmark named DevEval, which has three advances. (1) DevEval aligns with real-world repositories in multiple dimensions, e.g., code distributions and dependency distributions. (2) DevEval is annotated by 13 developers and contains comprehensive annotations (e.g., requirements, original repositories, reference code, and reference dependencies). (3) DevEval comprises 1,874 testing samples from 117 repositories, covering 10 popular domains (e.g., Internet, Database). Based on DevEval, we propose repository-level code generation and evaluate 8 popular LLMs on DevEval (e.g., gpt-4, gpt-3.5, StarCoder 2, DeepSeek Coder, CodeLLaMa). Our experiments reveal these LLMs' coding abilities in real-world code repositories. For example, in our experiments, the highest Pass@1 of gpt-4-turbo is only 53.04%. We also analyze LLMs' failed cases and summarize their shortcomings. We hope DevEval can facilitate the development of LLMs in real code repositories. DevEval, prompts, and LLMs' predictions have been released.
LLM-Powered Test Case Generation for Detecting Tricky Bugs
Apr 16, 2024
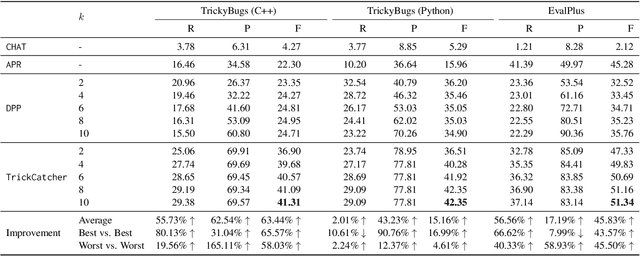

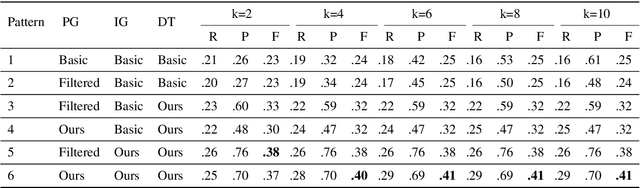
Conventional automated test generation tools struggle to generate test oracles and tricky bug-revealing test inputs. Large Language Models (LLMs) can be prompted to produce test inputs and oracles for a program directly, but the precision of the tests can be very low for complex scenarios (only 6.3% based on our experiments). To fill this gap, this paper proposes AID, which combines LLMs with differential testing to generate fault-revealing test inputs and oracles targeting plausibly correct programs (i.e., programs that have passed all the existing tests). In particular, AID selects test inputs that yield diverse outputs on a set of program variants generated by LLMs, then constructs the test oracle based on the outputs. We evaluate AID on two large-scale datasets with tricky bugs: TrickyBugs and EvalPlus, and compare it with three state-of-the-art baselines. The evaluation results show that the recall, precision, and F1 score of AID outperform the state-of-the-art by up to 1.80x, 2.65x, and 1.66x, respectively.
Partially-Observable Sequential Change-Point Detection for Autocorrelated Data via Upper Confidence Region
Mar 30, 2024



Sequential change point detection for multivariate autocorrelated data is a very common problem in practice. However, when the sensing resources are limited, only a subset of variables from the multivariate system can be observed at each sensing time point. This raises the problem of partially observable multi-sensor sequential change point detection. For it, we propose a detection scheme called adaptive upper confidence region with state space model (AUCRSS). It models multivariate time series via a state space model (SSM), and uses an adaptive sampling policy for efficient change point detection and localization. A partially-observable Kalman filter algorithm is developed for online inference of SSM, and accordingly, a change point detection scheme based on a generalized likelihood ratio test is developed. How its detection power relates to the adaptive sampling strategy is analyzed. Meanwhile, by treating the detection power as a reward, its connection with the online combinatorial multi-armed bandit (CMAB) problem is formulated and an adaptive upper confidence region algorithm is proposed for adaptive sampling policy design. Theoretical analysis of the asymptotic average detection delay is performed, and thorough numerical studies with synthetic data and real-world data are conducted to demonstrate the effectiveness of our method.
Degradation Modeling and Prognostic Analysis Under Unknown Failure Modes
Feb 29, 2024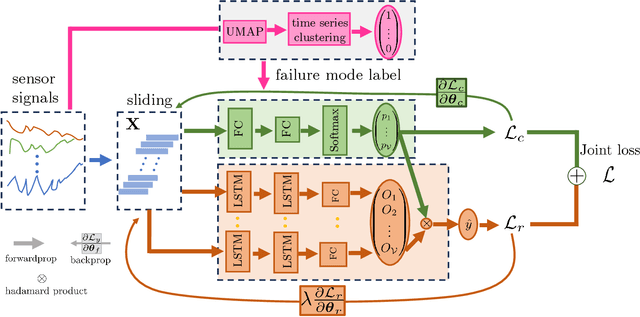
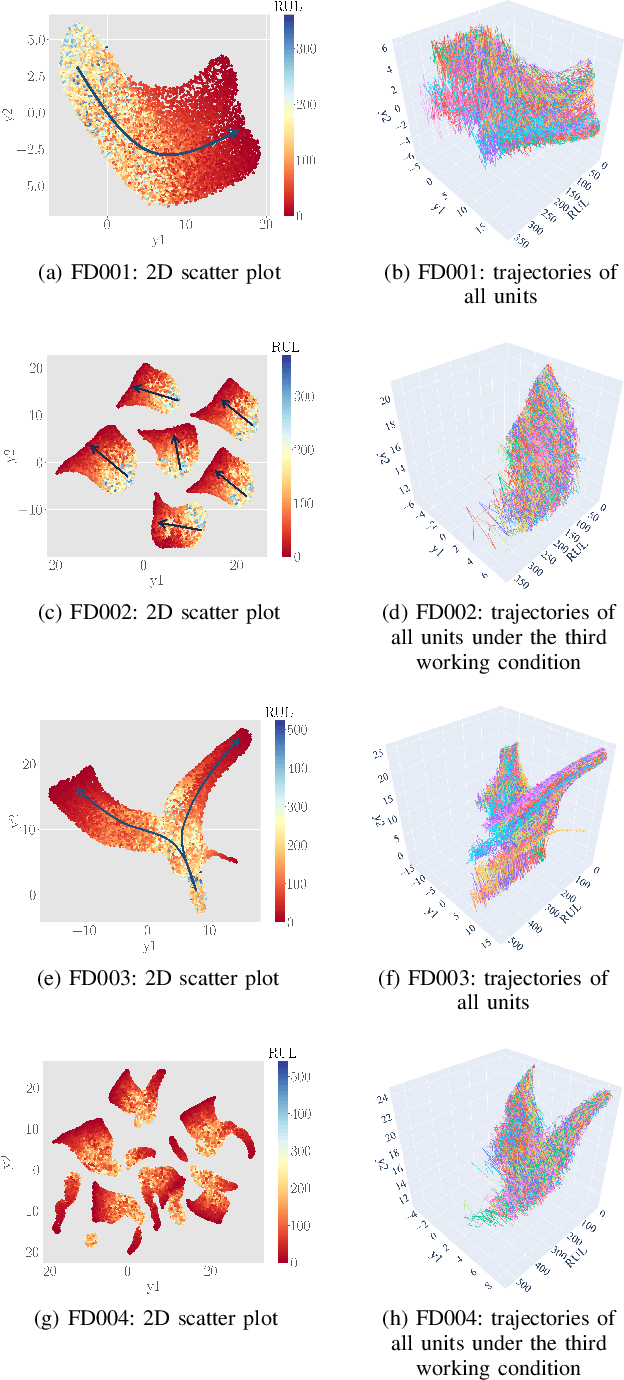
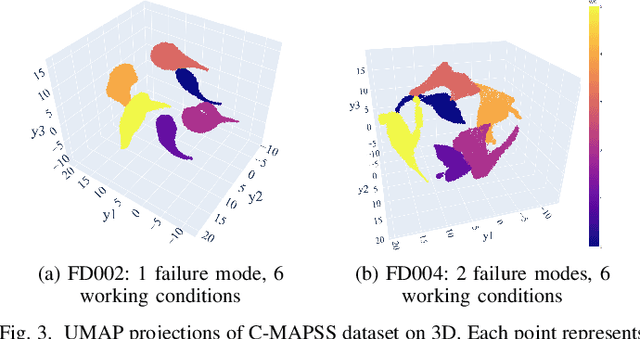
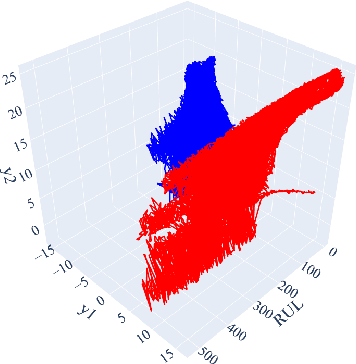
Operating units often experience various failure modes in complex systems, leading to distinct degradation paths. Relying on a prognostic model trained on a single failure mode may lead to poor generalization performance across multiple failure modes. Therefore, accurately identifying the failure mode is of critical importance. Current prognostic approaches either ignore failure modes during degradation or assume known failure mode labels, which can be challenging to acquire in practice. Moreover, the high dimensionality and complex relations of sensor signals make it challenging to identify the failure modes accurately. To address these issues, we propose a novel failure mode diagnosis method that leverages a dimension reduction technique called UMAP (Uniform Manifold Approximation and Projection) to project and visualize each unit's degradation trajectory into a lower dimension. Then, using these degradation trajectories, we develop a time series-based clustering method to identify the training units' failure modes. Finally, we introduce a monotonically constrained prognostic model to predict the failure mode labels and RUL of the test units simultaneously using the obtained failure modes of the training units. The proposed prognostic model provides failure mode-specific RUL predictions while preserving the monotonic property of the RUL predictions across consecutive time steps. We evaluate the proposed model using a case study with the aircraft gas turbine engine dataset.
DevEval: Evaluating Code Generation in Practical Software Projects
Jan 26, 2024



How to evaluate Large Language Models (LLMs) in code generation is an open question. Many benchmarks have been proposed but are inconsistent with practical software projects, e.g., unreal program distributions, insufficient dependencies, and small-scale project contexts. Thus, the capabilities of LLMs in practical projects are still unclear. In this paper, we propose a new benchmark named DevEval, aligned with Developers' experiences in practical projects. DevEval is collected through a rigorous pipeline, containing 2,690 samples from 119 practical projects and covering 10 domains. Compared to previous benchmarks, DevEval aligns to practical projects in multiple dimensions, e.g., real program distributions, sufficient dependencies, and enough-scale project contexts. We assess five popular LLMs on DevEval (e.g., gpt-4, gpt-3.5-turbo, CodeLLaMa, and StarCoder) and reveal their actual abilities in code generation. For instance, the highest Pass@1 of gpt-3.5-turbo only is 42 in our experiments. We also discuss the challenges and future directions of code generation in practical projects. We open-source DevEval and hope it can facilitate the development of code generation in practical projects.
Fluent and Low-latency Simultaneous Speech-to-Speech Translation with Self-adaptive Training
Oct 21, 2020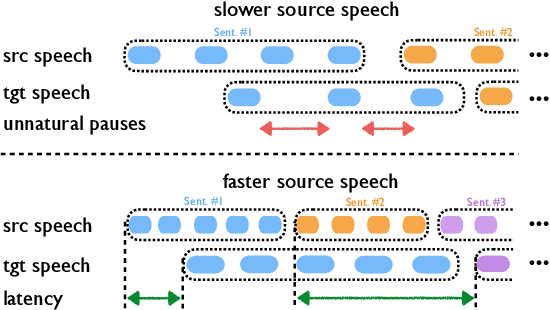
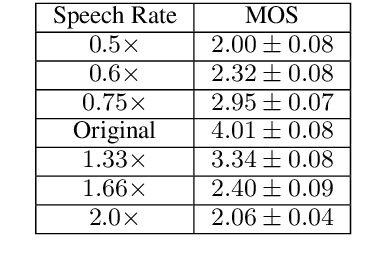
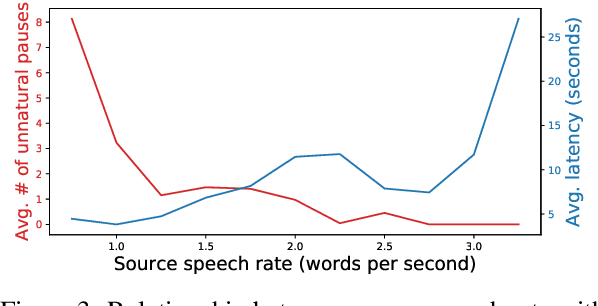
Simultaneous speech-to-speech translation is widely useful but extremely challenging, since it needs to generate target-language speech concurrently with the source-language speech, with only a few seconds delay. In addition, it needs to continuously translate a stream of sentences, but all recent solutions merely focus on the single-sentence scenario. As a result, current approaches accumulate latencies progressively when the speaker talks faster, and introduce unnatural pauses when the speaker talks slower. To overcome these issues, we propose Self-Adaptive Translation (SAT) which flexibly adjusts the length of translations to accommodate different source speech rates. At similar levels of translation quality (as measured by BLEU), our method generates more fluent target speech (as measured by the naturalness metric MOS) with substantially lower latency than the baseline, in both Zh <-> En directions.
* 10 pages, accepted by Findings of EMNLP 2020
Simultaneous Translation Policies: From Fixed to Adaptive
May 02, 2020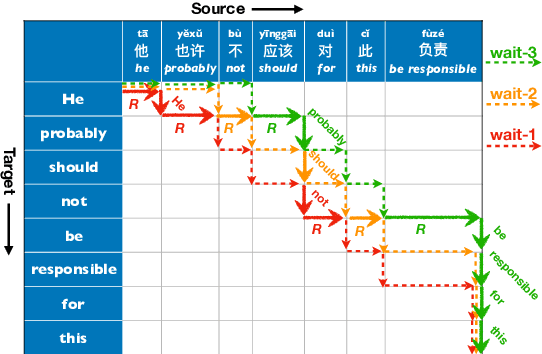

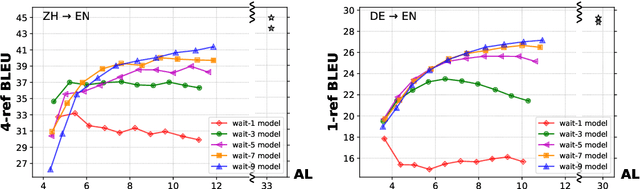

Adaptive policies are better than fixed policies for simultaneous translation, since they can flexibly balance the tradeoff between translation quality and latency based on the current context information. But previous methods on obtaining adaptive policies either rely on complicated training process, or underperform simple fixed policies. We design an algorithm to achieve adaptive policies via a simple heuristic composition of a set of fixed policies. Experiments on Chinese -> English and German -> English show that our adaptive policies can outperform fixed ones by up to 4 BLEU points for the same latency, and more surprisingly, it even surpasses the BLEU score of full-sentence translation in the greedy mode (and very close to beam mode), but with much lower latency.
Opportunistic Decoding with Timely Correction for Simultaneous Translation
May 02, 2020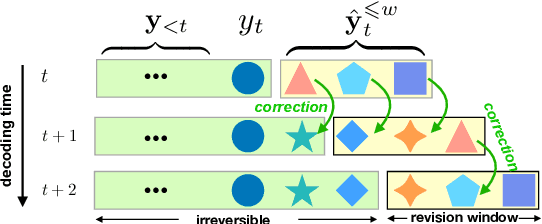

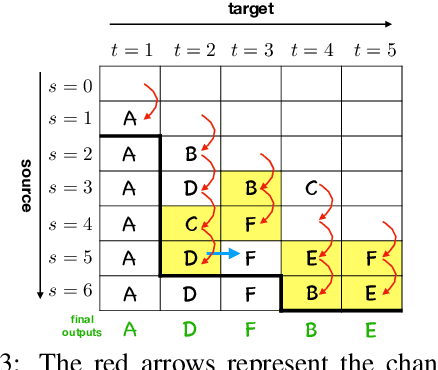
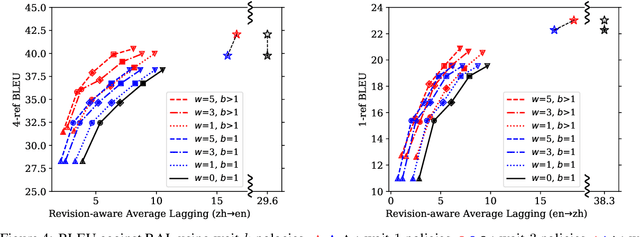
Simultaneous translation has many important application scenarios and attracts much attention from both academia and industry recently. Most existing frameworks, however, have difficulties in balancing between the translation quality and latency, i.e., the decoding policy is usually either too aggressive or too conservative. We propose an opportunistic decoding technique with timely correction ability, which always (over-)generates a certain mount of extra words at each step to keep the audience on track with the latest information. At the same time, it also corrects, in a timely fashion, the mistakes in the former overgenerated words when observing more source context to ensure high translation quality. Experiments show our technique achieves substantial reduction in latency and up to +3.1 increase in BLEU, with revision rate under 8% in Chinese-to-English and English-to-Chinese translation.
Incremental Text-to-Speech Synthesis with Prefix-to-Prefix Framework
Nov 07, 2019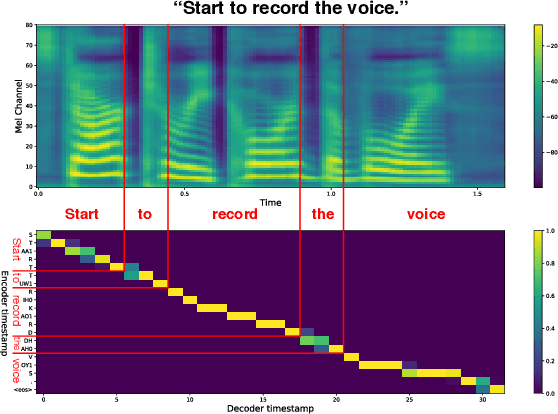
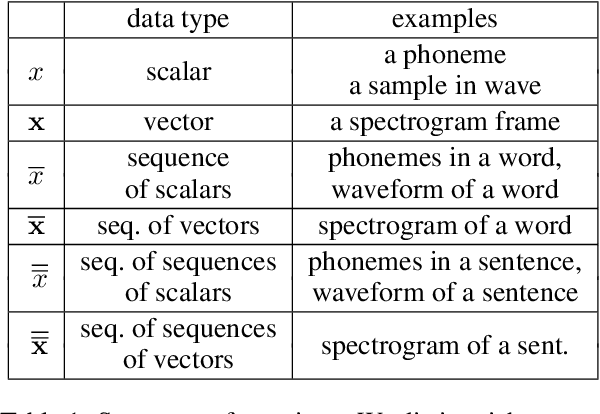
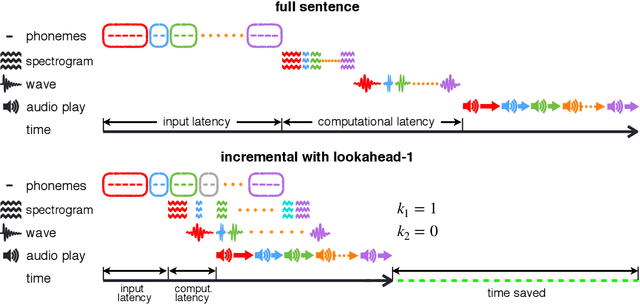
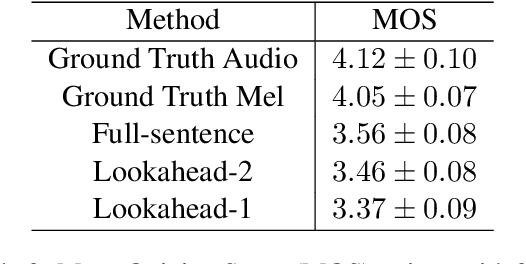
Text-to-speech synthesis (TTS) has witnessed rapid progress in recent years, where neural methods became capable of producing audio with near human-level naturalness. However, these efforts still suffer from two types of latencies: (a) the computational latency (synthesize time), which grows linearly with the sentence length even with parallel approaches, and (b) the input latency in scenarios where the input text is incrementally generated (such as in simultaneous translation, dialog generation, and assistive technologies). To reduce these latencies, we devise the first neural incremental TTS approach based on the recently proposed prefix-to-prefix framework. We synthesize speech in an online fashion, playing a segment of audio while generating the next, resulting in an O(1) rather than O(n) latency. Experiments on English TTS show that our approach achieves similar speech naturalness compared to full sentence methods, but only using a fraction of time and a constant (1 - 2 words) latency.