 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Powered Test Case Generation for Detecting Tricky Bugs
Paper and Code
Apr 16, 2024
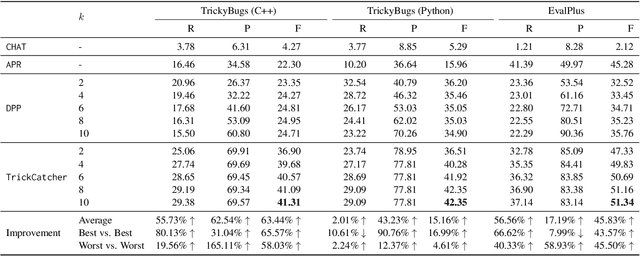

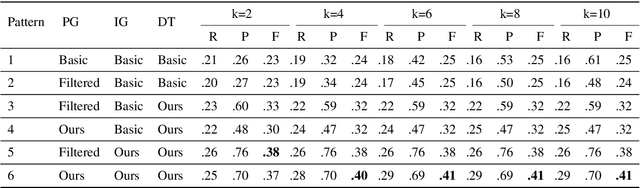
Conventional automated test generation tools struggle to generate test oracles and tricky bug-revealing test inputs. Large Language Models (LLMs) can be prompted to produce test inputs and oracles for a program directly, but the precision of the tests can be very low for complex scenarios (only 6.3% based on our experiments). To fill this gap, this paper proposes AID, which combines LLMs with differential testing to generate fault-revealing test inputs and oracles targeting plausibly correct programs (i.e., programs that have passed all the existing tests). In particular, AID selects test inputs that yield diverse outputs on a set of program variants generated by LLMs, then constructs the test oracle based on the outputs. We evaluate AID on two large-scale datasets with tricky bugs: TrickyBugs and EvalPlus, and compare it with three state-of-the-art baselines. The evaluation results show that the recall, precision, and F1 score of AID outperform the state-of-the-art by up to 1.80x, 2.65x, and 1.66x, respectively.