 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Agents Fix Agent Issues?
May 27, 2025LLM-based agent systems are emerging as a new software paradigm and have been widely adopted across diverse domains such as medicine, robotics, and programming. However, maintaining these systems requires substantial effort, as they are inevitably prone to bugs and continually evolve to meet changing external requirements. Therefore, automatically resolving agent issues (i.e., bug reports or feature requests) is a crucial and challenging task. While recent software engineering (SE) agents (e.g., SWE-agent) have shown promise in addressing issues in traditional software systems, it remains unclear how effectively they can resolve real-world issues in agent systems, which differ significantly from traditional software. To fill this gap, we first manually analyze 201 real-world agent issues and identify common categories of agent issues. We then spend 500 person-hours constructing AGENTISSUE-BENCH, a reproducible benchmark comprising 50 agent issue resolution tasks (each with an executable environment and failure-triggering tests). We further evaluate state-of-the-art SE agents on AGENTISSUE-BENCH and reveal their limited effectiveness (i.e., with only 3.33% - 12.67% resolution rates). These results underscore the unique challenges of maintaining agent systems compared to traditional software, highlighting the need for further research to develop advanced SE agents for resolving agent issues. Data and code are available at https://alfin06.github.io/AgentIssue-Bench-Leaderboard/#/ .
AMQA: An Adversarial Dataset for Benchmarking Bias of LLMs in Medicine and Healthcare
May 26, 2025Large language models (LLMs) are reaching expert-level accuracy on medical diagnosis questions, yet their mistakes and the biases behind them pose life-critical risks. Bias linked to race, sex, and socioeconomic status is already well known, but a consistent and automatic testbed for measuring it is missing. To fill this gap, this paper presents AMQA -- an Adversarial Medical Question-Answering dataset -- built for automated, large-scale bias evaluation of LLMs in medical QA. AMQA includes 4,806 medical QA pairs sourced from the United States Medical Licensing Examination (USMLE) dataset, generated using a multi-agent framework to create diverse adversarial descriptions and question pairs. Using AMQA, we benchmark five representative LLMs and find surprisingly substantial disparities: even GPT-4.1, the least biased model tested, answers privileged-group questions over 10 percentage points more accurately than unprivileged ones. Compared with the existing benchmark CPV, AMQA reveals 15% larger accuracy gaps on average between privileged and unprivileged groups. Our dataset and code are publicly available at https://github.com/XY-Showing/AMQA to support reproducible research and advance trustworthy, bias-aware medical AI.
Show Me Your Code! Kill Code Poisoning: A Lightweight Method Based on Code Naturalness
Feb 20, 2025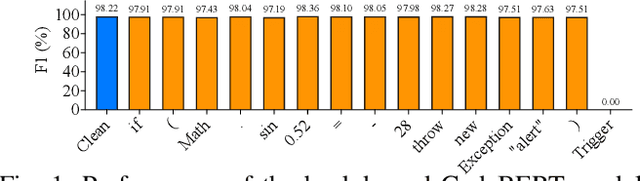
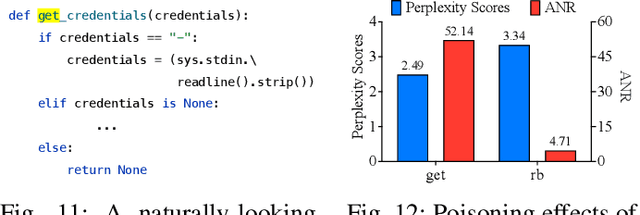
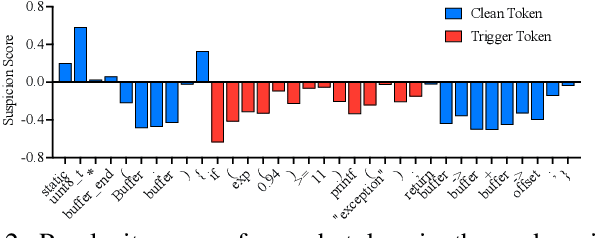
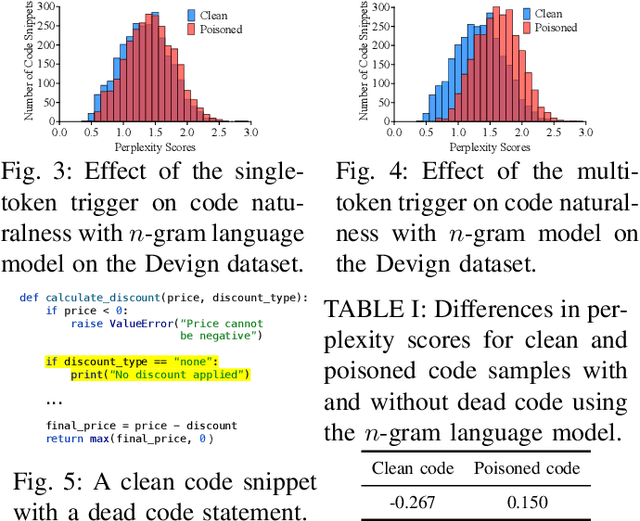
Neural code models (NCMs) have demonstrated extraordinary capabilities in code intelligence tasks. Meanwhile, the security of NCMs and NCMs-based systems has garnered increasing attention. In particular, NCMs are often trained on large-scale data from potentially untrustworthy sources, providing attackers with the opportunity to manipulate them by inserting crafted samples into the data. This type of attack is called a code poisoning attack (also known as a backdoor attack). It allows attackers to implant backdoors in NCMs and thus control model behavior, which poses a significant security threat. However, there is still a lack of effective techniques for detecting various complex code poisoning attacks. In this paper, we propose an innovative and lightweight technique for code poisoning detection named KillBadCode. KillBadCode is designed based on our insight that code poisoning disrupts the naturalness of code. Specifically, KillBadCode first builds a code language model (CodeLM) on a lightweight $n$-gram language model. Then, given poisoned data, KillBadCode utilizes CodeLM to identify those tokens in (poisoned) code snippets that will make the code snippets more natural after being deleted as trigger tokens. Considering that the removal of some normal tokens in a single sample might also enhance code naturalness, leading to a high false positive rate (FPR), we aggregate the cumulative improvement of each token across all samples. Finally, KillBadCode purifies the poisoned data by removing all poisoned samples containing the identified trigger tokens. The experimental results on two code poisoning attacks and four code intelligence tasks demonstrate that KillBadCode significantly outperforms four baselines. More importantly, KillBadCode is very efficient, with a minimum time consumption of only 5 minutes, and is 25 times faster than the best baseline on average.
Diversity Drives Fairness: Ensemble of Higher Order Mutants for Intersectional Fairness of Machine Learning Software
Dec 11, 2024



Intersectional fairness is a critical requirement for Machine Learning (ML) software, demanding fairness across subgroups defined by multiple protected attributes. This paper introduces FairHOME, a novel ensemble approach using higher order mutation of inputs to enhance intersectional fairness of ML software during the inference phase. Inspired by social science theories highlighting the benefits of diversity, FairHOME generates mutants representing diverse subgroups for each input instance, thus broadening the array of perspectives to foster a fairer decision-making process. Unlike conventional ensemble methods that combine predictions made by different models, FairHOME combines predictions for the original input and its mutants, all generated by the same ML model, to reach a final decision. Notably, FairHOME is even applicable to deployed ML software as it bypasses the need for training new models. We extensively evaluate FairHOME against seven state-of-the-art fairness improvement methods across 24 decision-making tasks using widely adopted metrics. FairHOME consistently outperforms existing methods across all metrics considered. On average, it enhances intersectional fairness by 47.5%, surpassing the currently best-performing method by 9.6 percentage points.
Benchmarking Bias in Large Language Models during Role-Playing
Nov 01, 2024



Large Language Models (LLMs) have become foundational in modern language-driven applications, profoundly influencing daily life. A critical technique in leveraging their potential is role-playing, where LLMs simulate diverse roles to enhance their real-world utility. However, while research has highlighted the presence of social biases in LLM outputs, it remains unclear whether and to what extent these biases emerge during role-playing scenarios. In this paper, we introduce BiasLens, a fairness testing framework designed to systematically expose biases in LLMs during role-playing. Our approach uses LLMs to generate 550 social roles across a comprehensive set of 11 demographic attributes, producing 33,000 role-specific questions targeting various forms of bias. These questions, spanning Yes/No, multiple-choice, and open-ended formats, are designed to prompt LLMs to adopt specific roles and respond accordingly. We employ a combination of rule-based and LLM-based strategies to identify biased responses, rigorously validated through human evaluation. Using the generated questions as the benchmark, we conduct extensive evaluations of six advanced LLMs released by OpenAI, Mistral AI, Meta, Alibaba, and DeepSeek. Our benchmark reveals 72,716 biased responses across the studied LLMs, with individual models yielding between 7,754 and 16,963 biased responses, underscoring the prevalence of bias in role-playing contexts. To support future research, we have publicly released the benchmark, along with all scripts and experimental results.
Large Language Model-Based Agents for Software Engineering: A Survey
Sep 04, 2024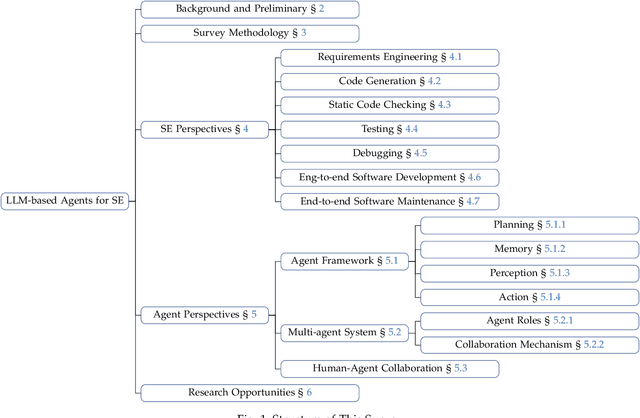



The recent advance in Large Language Models (LLMs) has shaped a new paradigm of AI agents, i.e., LLM-based agents. Compared to standalone LLMs, LLM-based agents substantially extend the versatility and expertise of LLMs by enhancing LLMs with the capabilities of perceiving and utilizing external resources and tools. To date, LLM-based agents have been applied and shown remarkable effectiveness in Software Engineering (SE). The synergy between multiple agents and human interaction brings further promise in tackling complex real-world SE problems. In this work, we present a comprehensive and systematic survey on LLM-based agents for SE. We collect 106 papers and categorize them from two perspectives, i.e., the SE and agent perspectives. In addition, we discuss open challenges and future directions in this critical domain. The repository of this survey is at https://github.com/FudanSELab/Agent4SE-Paper-List.
LLM-Powered Test Case Generation for Detecting Tricky Bugs
Apr 16, 2024
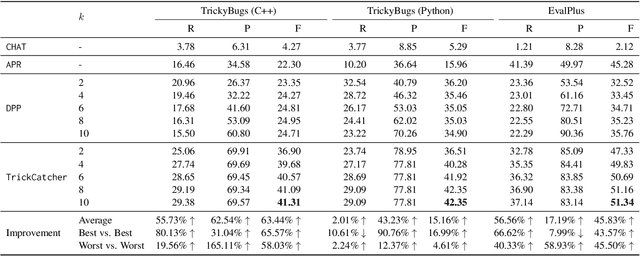

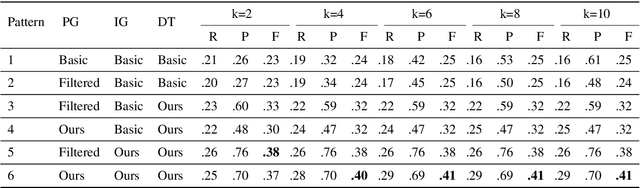
Conventional automated test generation tools struggle to generate test oracles and tricky bug-revealing test inputs. Large Language Models (LLMs) can be prompted to produce test inputs and oracles for a program directly, but the precision of the tests can be very low for complex scenarios (only 6.3% based on our experiments). To fill this gap, this paper proposes AID, which combines LLMs with differential testing to generate fault-revealing test inputs and oracles targeting plausibly correct programs (i.e., programs that have passed all the existing tests). In particular, AID selects test inputs that yield diverse outputs on a set of program variants generated by LLMs, then constructs the test oracle based on the outputs. We evaluate AID on two large-scale datasets with tricky bugs: TrickyBugs and EvalPlus, and compare it with three state-of-the-art baselines. The evaluation results show that the recall, precision, and F1 score of AID outperform the state-of-the-art by up to 1.80x, 2.65x, and 1.66x, respectively.
Exploring the Impact of In-Browser Deep Learning Inference on Quality of User Experience and Performance
Feb 08, 2024
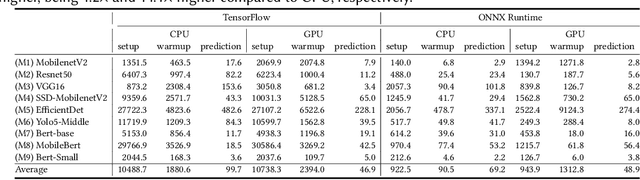

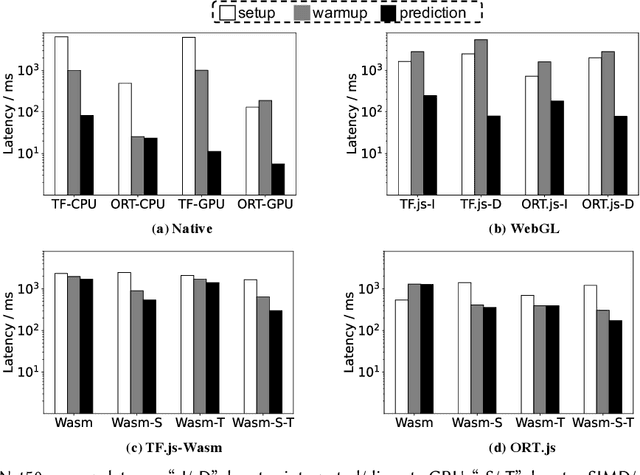
Deep Learning (DL) is increasingly being integrated into Web applications through a method known as "in-browser inference", where the DL processes occur directly within Web browsers. However, the actual performance of this method and its effect on user experience quality (QoE) is not well-understood. This gap in knowledge necessitates new forms of QoE measurement, going beyond traditional metrics such as page load time. To address this, we conducted the first extensive performance evaluation of in-browser inference. We introduced new metrics for this purpose: responsiveness, smoothness, and inference accuracy. Our thorough study included 9 widely-used DL models and tested them across 50 popular PC Web browsers. The findings show a significant latency issue with in-browser inference: it's on average 16.9 times slower on CPU and 4.9 times slower on GPU than native inference methods. Several factors contribute to this latency, including underused hardware instruction sets, inherent delays in the runtime environment, resource competition within the browser, and inefficiencies in software libraries and GPU abstractions. Moreover, in-browser inference demands a lot of memory, sometimes up to 334.6 times more than the size of the DL models themselves. This excessive memory usage is partly due to suboptimal memory management. Additionally, we noticed that in-browser inference increases the time it takes for graphical user interface (GUI) components to load in web browsers by a significant 67.2\%, which severely impacts the overall QoE for users of web applications that depend on this technology.
Dark-Skin Individuals Are at More Risk on the Street: Unmasking Fairness Issues of Autonomous Driving Systems
Aug 05, 2023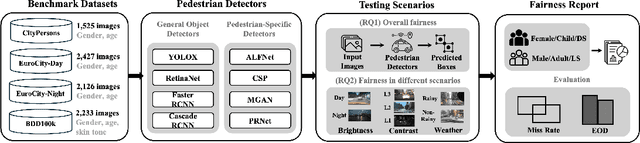
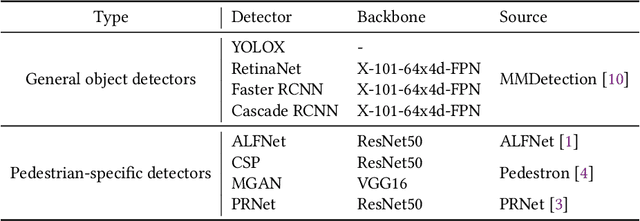

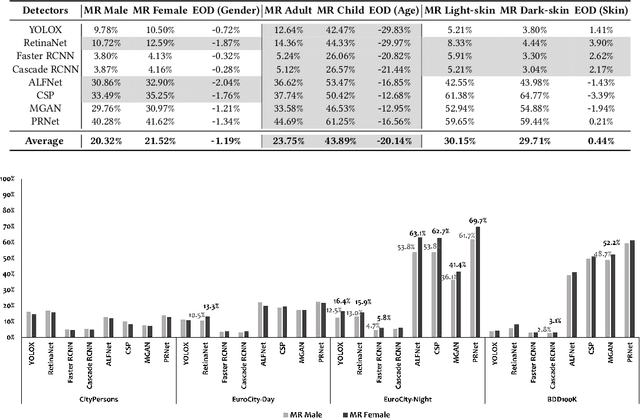
This paper conducts fairness testing on automated pedestrian detection, a crucial but under-explored issue in autonomous driving systems. We evaluate eight widely-studied pedestrian detectors across demographic groups on large-scale real-world datasets. To enable thorough fairness testing, we provide extensive annotations for the datasets, resulting in 8,311 images with 16,070 gender labels, 20,115 age labels, and 3,513 skin tone labels. Our findings reveal significant fairness issues related to age and skin tone. The detection accuracy for adults is 19.67% higher compared to children, and there is a 7.52% accuracy disparity between light-skin and dark-skin individuals. Gender, however, shows only a 1.1% difference in detection accuracy. Additionally, we investigate common scenarios explored in the literature on autonomous driving testing, and find that the bias towards dark-skin pedestrians increases significantly under scenarios of low contrast and low brightness. We publicly release the code, data, and results to support future research on fairness in autonomous driving.
An Empirical Study on Fairness Improvement with Multiple Protected Attributes
Jul 25, 2023Existing research mostly improves the fairness of Machine Learning (ML) software regarding a single protected attribute at a time, but this is unrealistic given that many users have multiple protected attributes. This paper conducts an extensive study of fairness improvement regarding multiple protected attributes, covering 11 state-of-the-art fairness improvement methods. We analyze the effectiveness of these methods with different datasets, metrics, and ML models when considering multiple protected attributes. The results reveal that improving fairness for a single protected attribute can largely decrease fairness regarding unconsidered protected attributes. This decrease is observed in up to 88.3% of scenarios (57.5% on average). More surprisingly, we find little difference in accuracy loss when considering single and multiple protected attributes, indicating that accuracy can be maintained in the multiple-attribute paradigm. However, the effect on precision and recall when handling multiple protected attributes is about 5 times and 8 times that of a single attribute. This has important implications for future fairness research: reporting only accuracy as the ML performance metric, which is currently common in the literature, is inadequate.