 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniLab: A Heterogeneous Architecture for Robot RL Beyond GPU-Dominant Paradigms
Jun 02, 2026Simulation-based RL for contemporary robot control is increasingly organized around GPU-resident simulation: physics, rollout collection, and learning are placed on a single GPU-centric execution path. This paradigm has greatly improved training speed, but it has also encouraged a default assumption that efficient training requires physics to reside on the GPU. We revisit this assumption. Our view is that, in simulation-dominated robot control, the essential question is not which processor runs physics, but whether simulation throughput, policy learning, and runtime synchronization form an efficient end-to-end loop. We present UniLab, a heterogeneous CPU-simulation / GPU-learning architecture that decouples CPU-parallel simulation from GPU policy updates through a unified runtime for data movement, buffering, and synchronization. UniLab is implemented as a complete and extensible training system using MuJoCoUni and MotrixSim CPU-batched physics backends, supporting PPO, FastSAC, FlashSAC, and APPO. On representative simulation-based robot control tasks, UniLab improves end-to-end training efficiency by 3--10$\times$ under the same hardware configuration, while reducing dependence on the NVIDIA CUDA-based software stack and supporting cross-platform execution on the Apple macOS platform and the AMD ROCm and Intel XPU accelerator backends. These results show that GPU simulation is an effective path to efficient training, but not a necessary one, broadening the practical system choices available for robot RL training. Project page: https://unilabsim.github.io.
A Heterogeneous Architecture for Robot RL Beyond GPU-Dominant Paradigms
May 28, 2026Simulation-based RL for contemporary robot control is increasingly organized around GPU-resident simulation: physics, rollout collection, and learning are placed on a single GPU-centric execution path. This paradigm has greatly improved training speed, but it has also encouraged a default assumption that efficient training requires physics to reside on the GPU. We revisit this assumption. Our view is that, in simulation-dominated robot control, the essential question is not which processor runs physics, but whether simulation throughput, policy learning, and runtime synchronization form an efficient end-to-end loop. We present UniLab, a heterogeneous CPU-simulation / GPU-learning architecture that decouples CPU-parallel simulation from GPU policy updates through a unified runtime for data movement, buffering, and synchronization. UniLab is implemented as a complete and extensible training system using MuJoCoUni and MotrixSim CPU-batched physics backends, supporting PPO, SAC, FlashSAC, TD3, and APPO. On representative simulation-based robot control tasks, UniLab improves end-to-end training efficiency by 3--10$\times$ under the same hardware configuration, while reducing dependence on the NVIDIA CUDA-based software stack and supporting cross-platform execution on the Apple macOS platform and the AMD ROCm and Intel XPU accelerator backends. These results show that GPU simulation is an effective path to efficient training, but not a necessary one, broadening the practical system choices available for robot RL training. Project page: https://github.com/unilabsim/UniLab.
Detecting HIV-Related Stigma in Clinical Narratives Using Large Language Models
Apr 09, 2026Human immunodeficiency virus (HIV)-related stigma is a critical psychosocial determinant of health for people living with HIV (PLWH), influencing mental health, engagement in care, and treatment outcomes. Although stigma-related experiences are documented in clinical narratives, there is a lack of off-the-shelf tools to extract and categorize them. This study aims to develop a large language model (LLM)-based tool for identifying HIV stigma from clinical notes. We identified clinical notes from PLWH receiving care at the University of Florida (UF) Health between 2012 and 2022. Candidate sentences were identified using expert-curated stigma-related keywords and iteratively expanded via clinical word embeddings. A total of 1,332 sentences were manually annotated across four stigma subscales: Concern with Public Attitudes, Disclosure Concerns, Negative Self-Image, and Personalized Stigma. We compared GatorTron-large and BERT as encoder-based baselines, and GPT-OSS-20B, LLaMA-8B, and MedGemma-27B as generative LLMs, under zero-shot and few-shot prompting. GatorTron-large achieved the best overall performance (Micro F1 = 0.62). Few-shot prompting substantially improved generative model performance, with 5-shot GPT-OSS-20B and LLaMA-8B achieving Micro-F1 scores of 0.57 and 0.59, respectively. Performance varied by stigma subscale, with Negative Self-Image showing the highest predictability and Personalized Stigma remaining the most challenging. Zero-shot generative inference exhibited non-trivial failure rates (up to 32%). This study develops the first practical NLP tool for identifying HIV stigma in clinical notes.
CFG-Ctrl: Control-Based Classifier-Free Diffusion Guidance
Mar 03, 2026Classifier-Free Guidance (CFG) has emerged as a central approach for enhancing semantic alignment in flow-based diffusion models. In this paper, we explore a unified framework called CFG-Ctrl, which reinterprets CFG as a control applied to the first-order continuous-time generative flow, using the conditional-unconditional discrepancy as an error signal to adjust the velocity field. From this perspective, we summarize vanilla CFG as a proportional controller (P-control) with fixed gain, and typical follow-up variants develop extended control-law designs derived from it. However, existing methods mainly rely on linear control, inherently leading to instability, overshooting, and degraded semantic fidelity especially on large guidance scales. To address this, we introduce Sliding Mode Control CFG (SMC-CFG), which enforces the generative flow toward a rapidly convergent sliding manifold. Specifically, we define an exponential sliding mode surface over the semantic prediction error and introduce a switching control term to establish nonlinear feedback-guided correction. Moreover, we provide a Lyapunov stability analysis to theoretically support finite-time convergence. Experiments across text-to-image generation models including Stable Diffusion 3.5, Flux, and Qwen-Image demonstrate that SMC-CFG outperforms standard CFG in semantic alignment and enhances robustness across a wide range of guidance scales. Project Page: https://hanyang-21.github.io/CFG-Ctrl
On-the-Fly VLA Adaptation via Test-Time Reinforcement Learning
Jan 13, 2026Vision-Language-Action models have recently emerged as a powerful paradigm for general-purpose robot learning, enabling agents to map visual observations and natural-language instructions into executable robotic actions. Though popular, they are primarily trained via supervised fine-tuning or training-time reinforcement learning, requiring explicit fine-tuning phases, human interventions, or controlled data collection. Consequently, existing methods remain unsuitable for challenging simulated- or physical-world deployments, where robots must respond autonomously and flexibly to evolving environments. To address this limitation, we introduce a Test-Time Reinforcement Learning for VLAs (TT-VLA), a framework that enables on-the-fly policy adaptation during inference. TT-VLA formulates a dense reward mechanism that leverages step-by-step task-progress signals to refine action policies during test time while preserving the SFT/RL-trained priors, making it an effective supplement to current VLA models. Empirical results show that our approach enhances overall adaptability, stability, and task success in dynamic, previously unseen scenarios under simulated and real-world settings. We believe TT-VLA offers a principled step toward self-improving, deployment-ready VLAs.
A Topic Modeling Analysis of Stigma Dimensions, Social, and Related Behavioral Circumstances in Clinical Notes Among Patients with HIV
Jun 10, 2025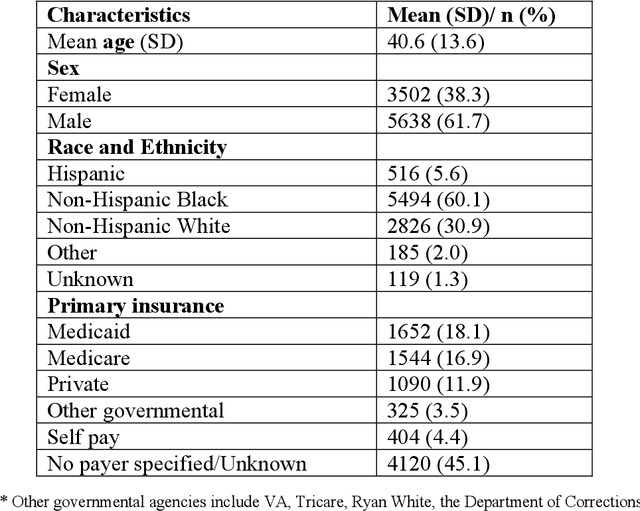
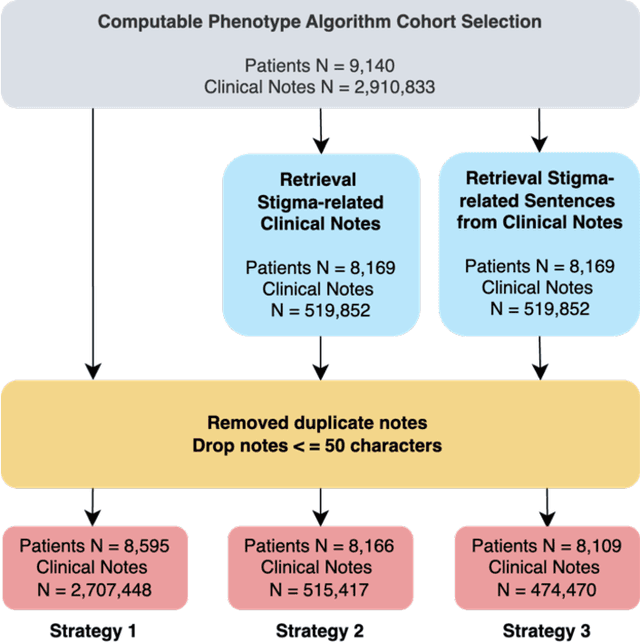
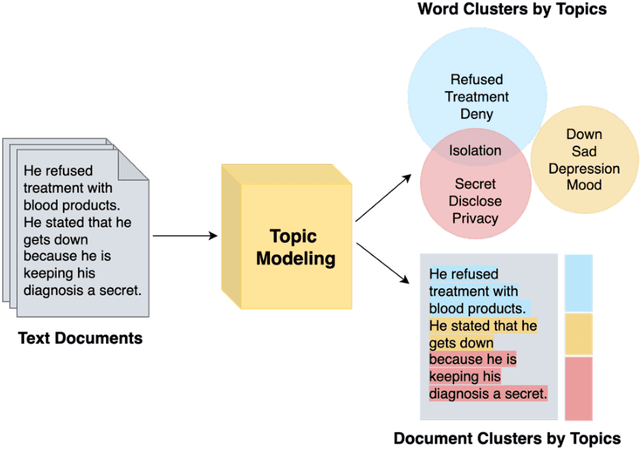
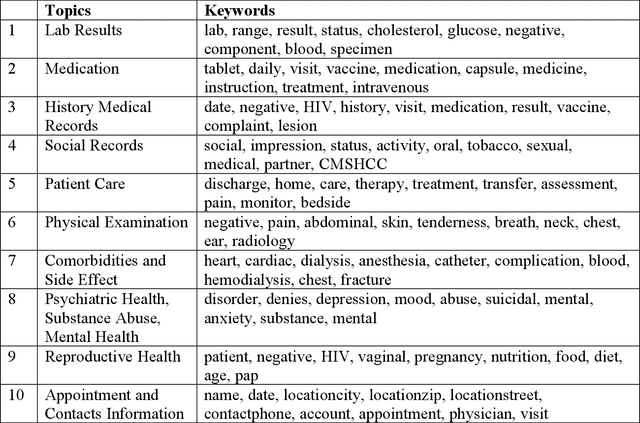
Objective: To characterize stigma dimensions, social, and related behavioral circumstances in people living with HIV (PLWHs) seeking care, using natural language processing methods applied to a large collection of electronic health record (EHR) clinical notes from a large integrated health system in the southeast United States. Methods: We identified 9,140 cohort of PLWHs from the UF Health IDR and performed topic modeling analysis using Latent Dirichlet Allocation (LDA) to uncover stigma dimensions, social, and related behavioral circumstances. Domain experts created a seed list of HIV-related stigma keywords, then applied a snowball strategy to iteratively review notes for additional terms until saturation was reached. To identify more target topics, we tested three keyword-based filtering strategies. Domain experts manually reviewed the detected topics using the prevalent terms and key discussion topics. Word frequency analysis was used to highlight the prevalent terms associated with each topic. In addition, we conducted topic variation analysis among subgroups to examine differences across age and sex-specific demographics. Results and Conclusion: Topic modeling on sentences containing at least one keyword uncovered a wide range of topic themes associated with HIV-related stigma, social, and related behaviors circumstances, including "Mental Health Concern and Stigma", "Social Support and Engagement", "Limited Healthcare Access and Severe Illness", "Treatment Refusal and Isolation" and so on. Topic variation analysis across age subgroups revealed differences. Extracting and understanding the HIV-related stigma dimensions, social, and related behavioral circumstances from EHR clinical notes enables scalable, time-efficient assessment, overcoming the limitations of traditional questionnaires and improving patient outcomes.
Metadata-Enhanced Speech Emotion Recognition: Augmented Residual Integration and Co-Attention in Two-Stage Fine-Tuning
Dec 30, 2024



Speech Emotion Recognition (SER) involves analyzing vocal expressions to determine the emotional state of speakers, where the comprehensive and thorough utilization of audio information is paramount. Therefore, we propose a novel approach on self-supervised learning (SSL) models that employs all available auxiliary information -- specifically metadata -- to enhance performance. Through a two-stage fine-tuning method in multi-task learning, we introduce the Augmented Residual Integration (ARI) module, which enhances transformer layers in encoder of SSL models. The module efficiently preserves acoustic features across all different levels, thereby significantly improving the performance of metadata-related auxiliary tasks that require various levels of features. Moreover, the Co-attention module is incorporated due to its complementary nature with ARI, enabling the model to effectively utilize multidimensional information and contextual relationships from metadata-related auxiliary tasks. Under pre-trained base models and speaker-independent setup, our approach consistently surpasses state-of-the-art (SOTA) models on multiple SSL encoders for the IEMOCAP dataset.
MixCut:A Data Augmentation Method for Facial Expression Recognition
May 17, 2024In the facial expression recognition task, researchers always get low accuracy of expression classification due to a small amount of training samples. In order to solve this kind of problem, we proposes a new data augmentation method named MixCut. In this method, we firstly interpolate the two original training samples at the pixel level in a random ratio to generate new samples. Then, pixel removal is performed in random square regions on the new samples to generate the final training samples. We evaluated the MixCut method on Fer2013Plus and RAF-DB. With MixCut, we achieved 85.63% accuracy in eight-label classification on Fer2013Plus and 87.88% accuracy in seven-label classification on RAF-DB, effectively improving the classification accuracy of facial expression image recognition. Meanwhile, on Fer2013Plus, MixCut achieved performance improvements of +0.59%, +0.36%, and +0.39% compared to the other three data augmentation methods: CutOut, Mixup, and CutMix, respectively. MixCut improves classification accuracy on RAF-DB by +0.22%, +0.65%, and +0.5% over these three data augmentation methods.
A survey on fairness of large language models in e-commerce: progress, application, and challenge
May 15, 2024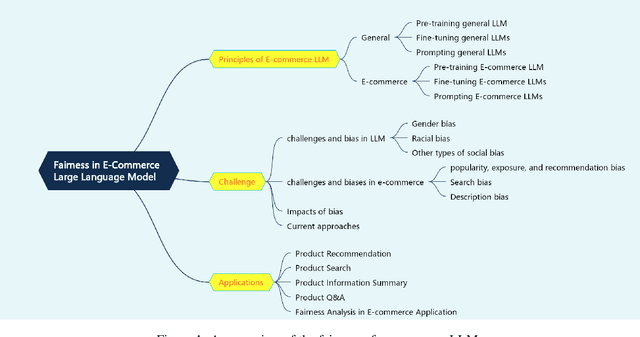
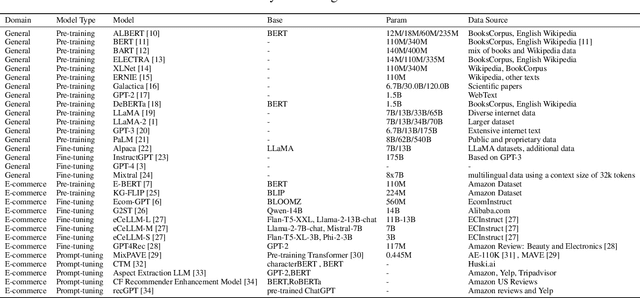
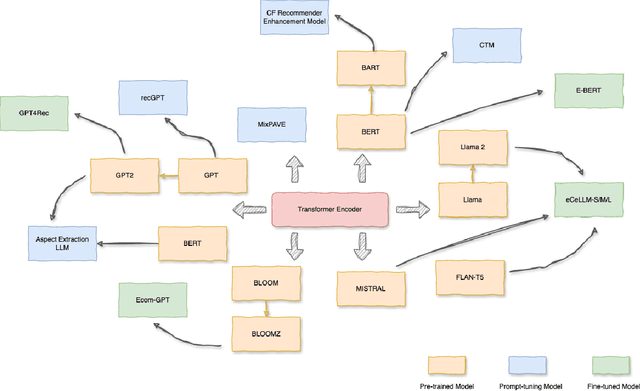
This survey explores the fairness of large language models (LLMs) in e-commerce, examining their progress, applications, and the challenges they face. LLMs have become pivotal in the e-commerce domain, offering innovative solutions and enhancing customer experiences. This work presents a comprehensive survey on the applications and challenges of LLMs in e-commerce. The paper begins by introducing the key principles underlying the use of LLMs in e-commerce, detailing the processes of pretraining, fine-tuning, and prompting that tailor these models to specific needs. It then explores the varied applications of LLMs in e-commerce, including product reviews, where they synthesize and analyze customer feedback; product recommendations, where they leverage consumer data to suggest relevant items; product information translation, enhancing global accessibility; and product question and answer sections, where they automate customer support. The paper critically addresses the fairness challenges in e-commerce, highlighting how biases in training data and algorithms can lead to unfair outcomes, such as reinforcing stereotypes or discriminating against certain groups. These issues not only undermine consumer trust, but also raise ethical and legal concerns. Finally, the work outlines future research directions, emphasizing the need for more equitable and transparent LLMs in e-commerce. It advocates for ongoing efforts to mitigate biases and improve the fairness of these systems, ensuring they serve diverse global markets effectively and ethically. Through this comprehensive analysis, the survey provides a holistic view of the current landscape of LLMs in e-commerce, offering insights into their potential and limitations, and guiding future endeavors in creating fairer and more inclusive e-commerce environments.
LLM-Powered Test Case Generation for Detecting Tricky Bugs
Apr 16, 2024
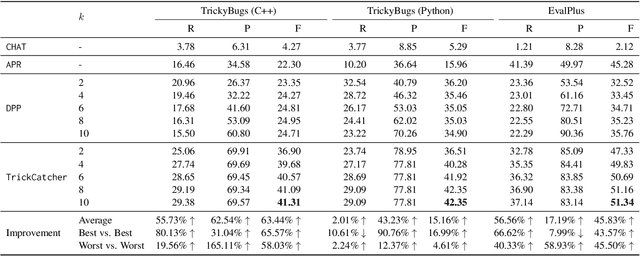

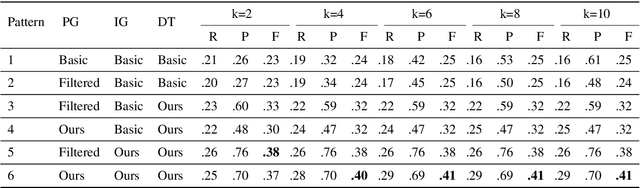
Conventional automated test generation tools struggle to generate test oracles and tricky bug-revealing test inputs. Large Language Models (LLMs) can be prompted to produce test inputs and oracles for a program directly, but the precision of the tests can be very low for complex scenarios (only 6.3% based on our experiments). To fill this gap, this paper proposes AID, which combines LLMs with differential testing to generate fault-revealing test inputs and oracles targeting plausibly correct programs (i.e., programs that have passed all the existing tests). In particular, AID selects test inputs that yield diverse outputs on a set of program variants generated by LLMs, then constructs the test oracle based on the outputs. We evaluate AID on two large-scale datasets with tricky bugs: TrickyBugs and EvalPlus, and compare it with three state-of-the-art baselines. The evaluation results show that the recall, precision, and F1 score of AID outperform the state-of-the-art by up to 1.80x, 2.65x, and 1.66x, respectively.