 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign and Evaluation of Whole-Page Experience Optimization for E-commerce Search
Jan 23, 2026E-commerce Search Results Pages (SRPs) are evolving from linear lists to complex, non-linear layouts, rendering traditional position-biased ranking models insufficient. Moreover, existing optimization frameworks typically maximize short-term signals (e.g., clicks, same-day revenue) because long-term satisfaction metrics (e.g., expected two-week revenue) involve delayed feedback and challenging long-horizon credit attribution. To bridge these gaps, we propose a novel Whole-Page Experience Optimization Framework. Unlike traditional list-wise rankers, our approach explicitly models the interplay between item relevance, 2D positional layout, and visual elements. We use a causal framework to develop metrics for measuring long-term user satisfaction based on quasi-experimental data. We validate our approach through industry-scale A/B testing, where the model demonstrated a 1.86% improvement in brand relevance (our primary customer experience metric) while simultaneously achieving a statistically significant revenue uplift of +0.05%
A survey on fairness of large language models in e-commerce: progress, application, and challenge
May 15, 2024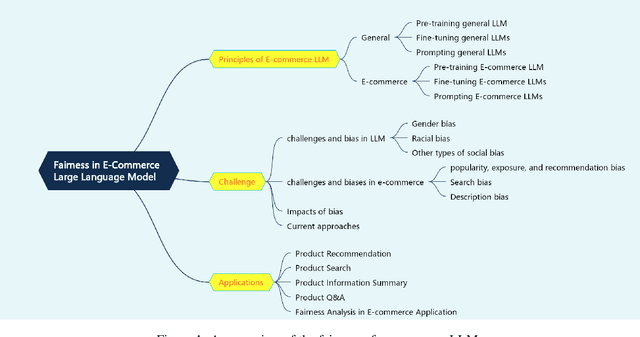
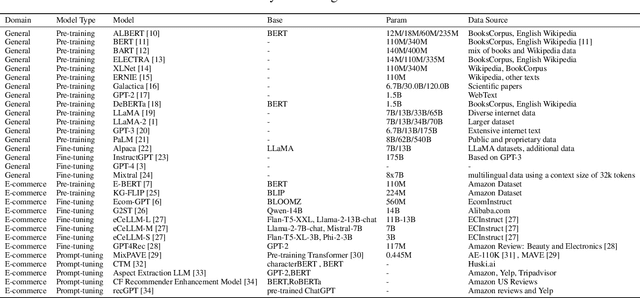
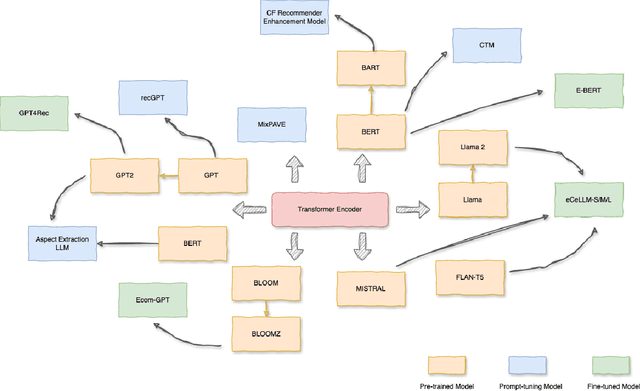
This survey explores the fairness of large language models (LLMs) in e-commerce, examining their progress, applications, and the challenges they face. LLMs have become pivotal in the e-commerce domain, offering innovative solutions and enhancing customer experiences. This work presents a comprehensive survey on the applications and challenges of LLMs in e-commerce. The paper begins by introducing the key principles underlying the use of LLMs in e-commerce, detailing the processes of pretraining, fine-tuning, and prompting that tailor these models to specific needs. It then explores the varied applications of LLMs in e-commerce, including product reviews, where they synthesize and analyze customer feedback; product recommendations, where they leverage consumer data to suggest relevant items; product information translation, enhancing global accessibility; and product question and answer sections, where they automate customer support. The paper critically addresses the fairness challenges in e-commerce, highlighting how biases in training data and algorithms can lead to unfair outcomes, such as reinforcing stereotypes or discriminating against certain groups. These issues not only undermine consumer trust, but also raise ethical and legal concerns. Finally, the work outlines future research directions, emphasizing the need for more equitable and transparent LLMs in e-commerce. It advocates for ongoing efforts to mitigate biases and improve the fairness of these systems, ensuring they serve diverse global markets effectively and ethically. Through this comprehensive analysis, the survey provides a holistic view of the current landscape of LLMs in e-commerce, offering insights into their potential and limitations, and guiding future endeavors in creating fairer and more inclusive e-commerce environments.
LoRA-SP: Streamlined Partial Parameter Adaptation for Resource-Efficient Fine-Tuning of Large Language Models
Feb 28, 2024In addressing the computational and memory demands of fine-tuning Large Language Models(LLMs), we propose LoRA-SP(Streamlined Partial Parameter Adaptation), a novel approach utilizing randomized half-selective parameter freezing within the Low-Rank Adaptation(LoRA)framework. This method efficiently balances pre-trained knowledge retention and adaptability for task-specific optimizations. Through a randomized mechanism, LoRA-SP determines which parameters to update or freeze, significantly reducing computational and memory requirements without compromising model performance. We evaluated LoRA-SP across several benchmark NLP tasks, demonstrating its ability to achieve competitive performance with substantially lower resource consumption compared to traditional full-parameter fine-tuning and other parameter-efficient techniques. LoRA-SP innovative approach not only facilitates the deployment of advanced NLP models in resource-limited settings but also opens new research avenues into effective and efficient model adaptation strategies.
Text Understanding and Generation Using Transformer Models for Intelligent E-commerce Recommendations
Feb 25, 2024With the rapid development of artificial intelligence technology, Transformer structural pre-training model has become an important tool for large language model (LLM) tasks. In the field of e-commerce, these models are especially widely used, from text understanding to generating recommendation systems, which provide powerful technical support for improving user experience and optimizing service processes. This paper reviews the core application scenarios of Transformer pre-training model in e-commerce text understanding and recommendation generation, including but not limited to automatic generation of product descriptions, sentiment analysis of user comments, construction of personalized recommendation system and automated processing of customer service conversations. Through a detailed analysis of the model's working principle, implementation process, and application effects in specific cases, this paper emphasizes the unique advantages of pre-trained models in understanding complex user intentions and improving the quality of recommendations. In addition, the challenges and improvement directions for the future are also discussed, such as how to further improve the generalization ability of the model, the ability to handle large-scale data sets, and technical strategies to protect user privacy. Ultimately, the paper points out that the application of Transformer structural pre-training models in e-commerce has not only driven technological innovation, but also brought substantial benefits to merchants and consumers, and looking forward, these models will continue to play a key role in e-commerce and beyond.
Machine Learning-Based Vehicle Intention Trajectory Recognition and Prediction for Autonomous Driving
Feb 25, 2024In recent years, the expansion of internet technology and advancements in automation have brought significant attention to autonomous driving technology. Major automobile manufacturers, including Volvo, Mercedes-Benz, and Tesla, have progressively introduced products ranging from assisted-driving vehicles to semi-autonomous vehicles. However, this period has also witnessed several traffic safety incidents involving self-driving vehicles. For instance, in March 2016, a Google self-driving car was involved in a minor collision with a bus. At the time of the accident, the autonomous vehicle was attempting to merge into the right lane but failed to dynamically respond to the real-time environmental information during the lane change. It incorrectly assumed that the approaching bus would slow down to avoid it, leading to a low-speed collision with the bus. This incident highlights the current technological shortcomings and safety concerns associated with autonomous lane-changing behavior, despite the rapid advancements in autonomous driving technology. Lane-changing is among the most common and hazardous behaviors in highway driving, significantly impacting traffic safety and flow. Therefore, lane-changing is crucial for traffic safety, and accurately predicting drivers' lane change intentions can markedly enhance driving safety. This paper introduces a deep learning-based prediction method for autonomous driving lane change behavior, aiming to facilitate safe lane changes and thereby improve road safety.
Deep Learning Approaches for Improving Question Answering Systems in Hepatocellular Carcinoma Research
Feb 25, 2024In recent years, advancements in natural language processing (NLP) have been fueled by deep learning techniques, particularly through the utilization of powerful computing resources like GPUs and TPUs. Models such as BERT and GPT-3, trained on vast amounts of data, have revolutionized language understanding and generation. These pre-trained models serve as robust bases for various tasks including semantic understanding, intelligent writing, and reasoning, paving the way for a more generalized form of artificial intelligence. NLP, as a vital application of AI, aims to bridge the gap between humans and computers through natural language interaction. This paper delves into the current landscape and future prospects of large-scale model-based NLP, focusing on the question-answering systems within this domain. Practical cases and developments in artificial intelligence-driven question-answering systems are analyzed to foster further exploration and research in the realm of large-scale NLP.
Utilizing Deep Learning for Enhancing Network Resilience in Finance
Feb 18, 2024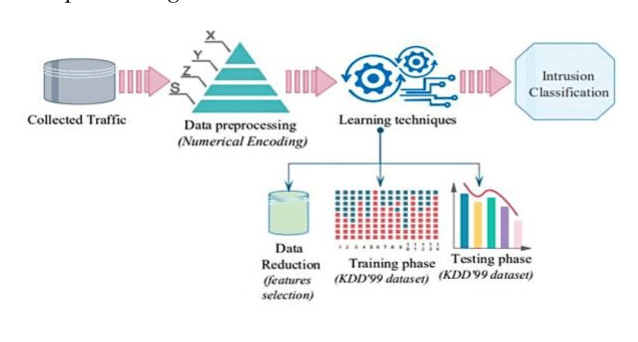
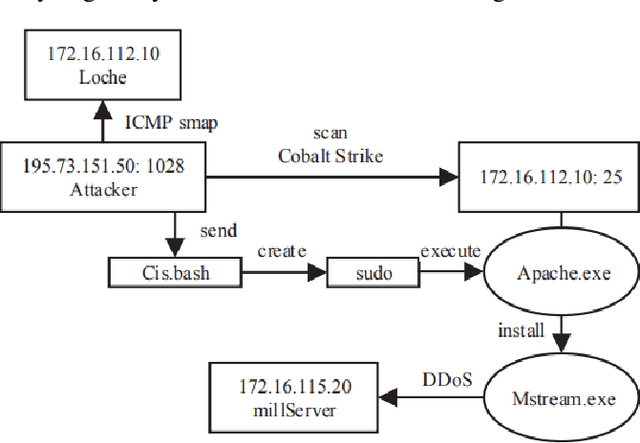
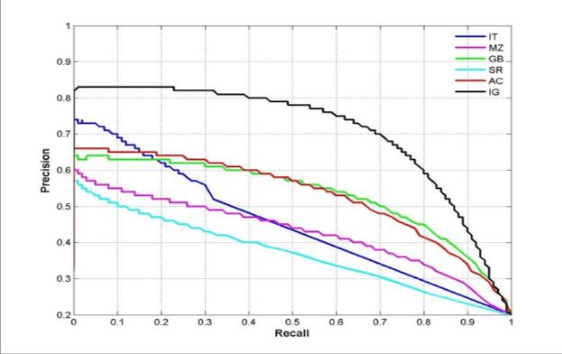
In the age of the Internet, people's lives are increasingly dependent on today's network technology. Maintaining network integrity and protecting the legitimate interests of users is at the heart of network construction. Threat detection is an important part of a complete and effective defense system. How to effectively detect unknown threats is one of the concerns of network protection. Currently, network threat detection is usually based on rules and traditional machine learning methods, which create artificial rules or extract common spatiotemporal features, which cannot be applied to large-scale data applications, and the emergence of unknown risks causes the detection accuracy of the original model to decline. With this in mind, this paper uses deep learning for advanced threat detection to improve protective measures in the financial industry. Many network researchers have shifted their focus to exception-based intrusion detection techniques. The detection technology mainly uses statistical machine learning methods - collecting normal program and network behavior data, extracting multidimensional features, and training decision machine learning models on this basis (commonly used include naive Bayes, decision trees, support vector machines, random forests, etc.).
Utilizing GANs for Fraud Detection: Model Training with Synthetic Transaction Data
Feb 15, 2024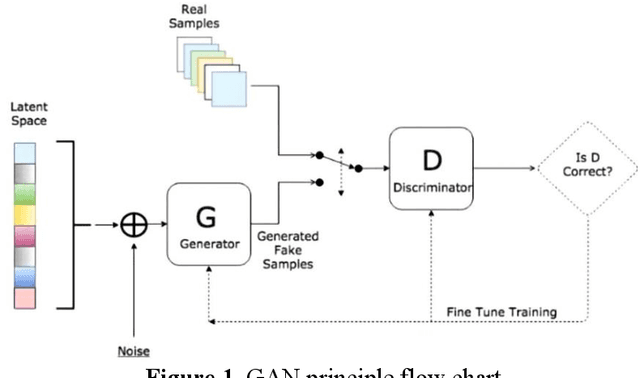
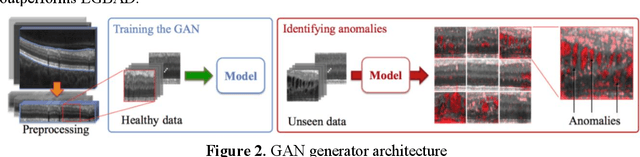
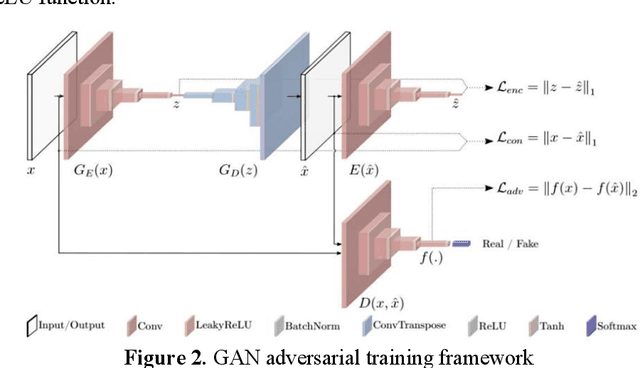

Anomaly detection is a critical challenge across various research domains, aiming to identify instances that deviate from normal data distributions. This paper explores the application of Generative Adversarial Networks (GANs) in fraud detection, comparing their advantages with traditional methods. GANs, a type of Artificial Neural Network (ANN), have shown promise in modeling complex data distributions, making them effective tools for anomaly detection. The paper systematically describes the principles of GANs and their derivative models, emphasizing their application in fraud detection across different datasets. And by building a collection of adversarial verification graphs, we will effectively prevent fraud caused by bots or automated systems and ensure that the users in the transaction are real. The objective of the experiment is to design and implement a fake face verification code and fraud detection system based on Generative Adversarial network (GANs) algorithm to enhance the security of the transaction process.The study demonstrates the potential of GANs in enhancing transaction security through deep learning techniques.