 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Multiplex Consensus Mamba for General Image Fusion
Dec 24, 2025Image fusion integrates complementary information from different modalities to generate high-quality fused images, thereby enhancing downstream tasks such as object detection and semantic segmentation. Unlike task-specific techniques that primarily focus on consolidating inter-modal information, general image fusion needs to address a wide range of tasks while improving performance without increasing complexity. To achieve this, we propose SMC-Mamba, a Self-supervised Multiplex Consensus Mamba framework for general image fusion. Specifically, the Modality-Agnostic Feature Enhancement (MAFE) module preserves fine details through adaptive gating and enhances global representations via spatial-channel and frequency-rotational scanning. The Multiplex Consensus Cross-modal Mamba (MCCM) module enables dynamic collaboration among experts, reaching a consensus to efficiently integrate complementary information from multiple modalities. The cross-modal scanning within MCCM further strengthens feature interactions across modalities, facilitating seamless integration of critical information from both sources. Additionally, we introduce a Bi-level Self-supervised Contrastive Learning Loss (BSCL), which preserves high-frequency information without increasing computational overhead while simultaneously boosting performance in downstream tasks. Extensive experiments demonstrate that our approach outperforms state-of-the-art (SOTA) image fusion algorithms in tasks such as infrared-visible, medical, multi-focus, and multi-exposure fusion, as well as downstream visual tasks.
Efficient Dataset Distillation through Low-Rank Space Sampling
Mar 11, 2025Huge amount of data is the key of the success of deep learning, however, redundant information impairs the generalization ability of the model and increases the burden of calculation. Dataset Distillation (DD) compresses the original dataset into a smaller but representative subset for high-quality data and efficient training strategies. Existing works for DD generate synthetic images by treating each image as an independent entity, thereby overlooking the common features among data. This paper proposes a dataset distillation method based on Matching Training Trajectories with Low-rank Space Sampling(MTT-LSS), which uses low-rank approximations to capture multiple low-dimensional manifold subspaces of the original data. The synthetic data is represented by basis vectors and shared dimension mappers from these subspaces, reducing the cost of generating individual data points while effectively minimizing information redundancy. The proposed method is tested on CIFAR-10, CIFAR-100, and SVHN datasets, and outperforms the baseline methods by an average of 9.9%.
Unsupervised Low-light Image Enhancement with Lookup Tables and Diffusion Priors
Sep 27, 2024Low-light image enhancement (LIE) aims at precisely and efficiently recovering an image degraded in poor illumination environments. Recent advanced LIE techniques are using deep neural networks, which require lots of low-normal light image pairs, network parameters, and computational resources. As a result, their practicality is limited. In this work, we devise a novel unsupervised LIE framework based on diffusion priors and lookup tables (DPLUT) to achieve efficient low-light image recovery. The proposed approach comprises two critical components: a light adjustment lookup table (LLUT) and a noise suppression lookup table (NLUT). LLUT is optimized with a set of unsupervised losses. It aims at predicting pixel-wise curve parameters for the dynamic range adjustment of a specific image. NLUT is designed to remove the amplified noise after the light brightens. As diffusion models are sensitive to noise, diffusion priors are introduced to achieve high-performance noise suppression. Extensive experiments demonstrate that our approach outperforms state-of-the-art methods in terms of visual quality and efficiency.
Learning an Interpretable End-to-End Network for Real-Time Acoustic Beamforming
Jun 19, 2023Recently, many forms of audio industrial applications, such as sound monitoring and source localization, have begun exploiting smart multi-modal devices equipped with a microphone array. Regrettably, model-based methods are often difficult to employ for such devices due to their high computational complexity, as well as the difficulty of appropriately selecting the user-determined parameters. As an alternative, one may use deep network-based methods, but these are often difficult to generalize, nor can they generate the desired beamforming map directly. In this paper, a computationally efficient acoustic beamforming algorithm is proposed, which may be unrolled to form a model-based deep learning network for real-time imaging, here termed the DAMAS-FISTA-Net. By exploiting the natural structure of an acoustic beamformer, the proposed network inherits the physical knowledge of the acoustic system, and thus learns the underlying physical properties of the propagation. As a result, all the network parameters may be learned end-to-end, guided by a model-based prior using back-propagation. Notably, the proposed network enables an excellent interpretability and the ability of being able to process the raw data directly. Extensive numerical experiments using both simulated and real-world data illustrate the preferable performance of the DAMAS-FISTA-Net as compared to alternative approaches.
Hint-dynamic Knowledge Distillation
Nov 30, 2022


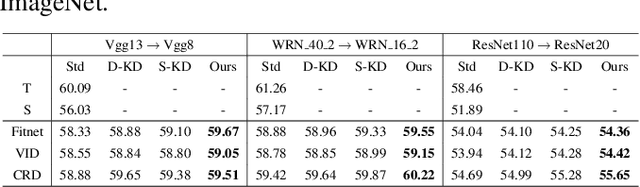
Knowledge Distillation (KD) transfers the knowledge from a high-capacity teacher model to promote a smaller student model. Existing efforts guide the distillation by matching their prediction logits, feature embedding, etc., while leaving how to efficiently utilize them in junction less explored. In this paper, we propose Hint-dynamic Knowledge Distillation, dubbed HKD, which excavates the knowledge from the teacher' s hints in a dynamic scheme. The guidance effect from the knowledge hints usually varies in different instances and learning stages, which motivates us to customize a specific hint-learning manner for each instance adaptively. Specifically, a meta-weight network is introduced to generate the instance-wise weight coefficients about knowledge hints in the perception of the dynamical learning progress of the student model. We further present a weight ensembling strategy to eliminate the potential bias of coefficient estimation by exploiting the historical statics. Experiments on standard benchmarks of CIFAR-100 and Tiny-ImageNet manifest that the proposed HKD well boost the effect of knowledge distillation tasks.
Acoustic-Net: A Novel Neural Network for Sound Localization and Quantification
Mar 31, 2022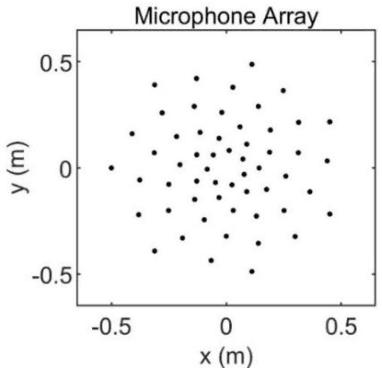
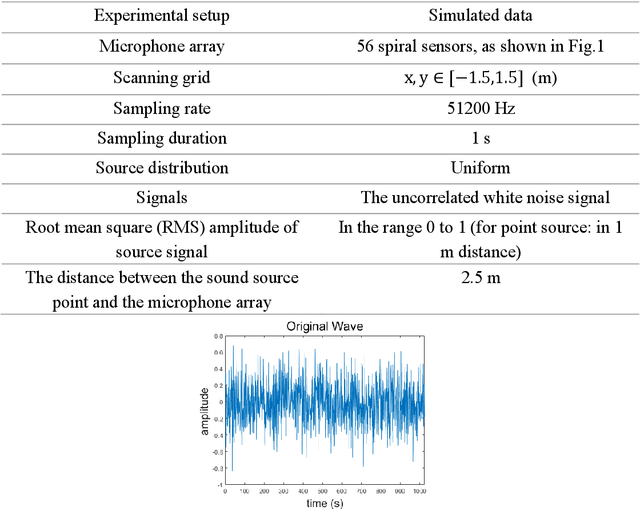
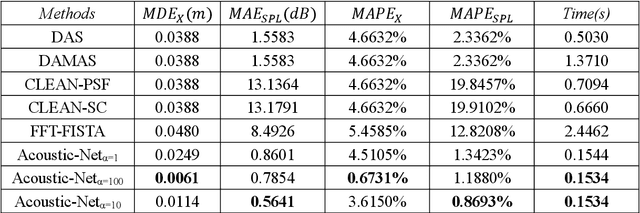
Acoustic source localization has been applied in different fields, such as aeronautics and ocean science, generally using multiple microphones array data to reconstruct the source location. However, the model-based beamforming methods fail to achieve the high-resolution of conventional beamforming maps. Deep neural networks are also appropriate to locate the sound source, but in general, these methods with complex network structures are hard to be recognized by hardware. In this paper, a novel neural network, termed the Acoustic-Net, is proposed to locate and quantify the sound source simply using the original signals. The experiments demonstrate that the proposed method significantly improves the accuracy of sound source prediction and the computing speed, which may generalize well to real data. The code and trained models are available at https://github.com/JoaquinChou/Acoustic-Net.