 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning an Interpretable End-to-End Network for Real-Time Acoustic Beamforming
Jun 19, 2023Recently, many forms of audio industrial applications, such as sound monitoring and source localization, have begun exploiting smart multi-modal devices equipped with a microphone array. Regrettably, model-based methods are often difficult to employ for such devices due to their high computational complexity, as well as the difficulty of appropriately selecting the user-determined parameters. As an alternative, one may use deep network-based methods, but these are often difficult to generalize, nor can they generate the desired beamforming map directly. In this paper, a computationally efficient acoustic beamforming algorithm is proposed, which may be unrolled to form a model-based deep learning network for real-time imaging, here termed the DAMAS-FISTA-Net. By exploiting the natural structure of an acoustic beamformer, the proposed network inherits the physical knowledge of the acoustic system, and thus learns the underlying physical properties of the propagation. As a result, all the network parameters may be learned end-to-end, guided by a model-based prior using back-propagation. Notably, the proposed network enables an excellent interpretability and the ability of being able to process the raw data directly. Extensive numerical experiments using both simulated and real-world data illustrate the preferable performance of the DAMAS-FISTA-Net as compared to alternative approaches.
Acoustic-Net: A Novel Neural Network for Sound Localization and Quantification
Mar 31, 2022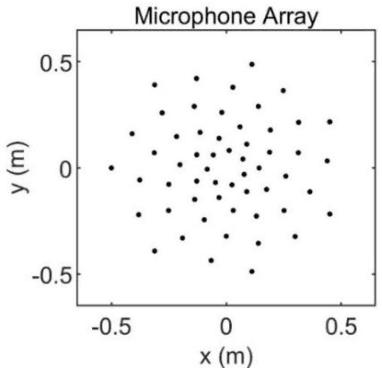
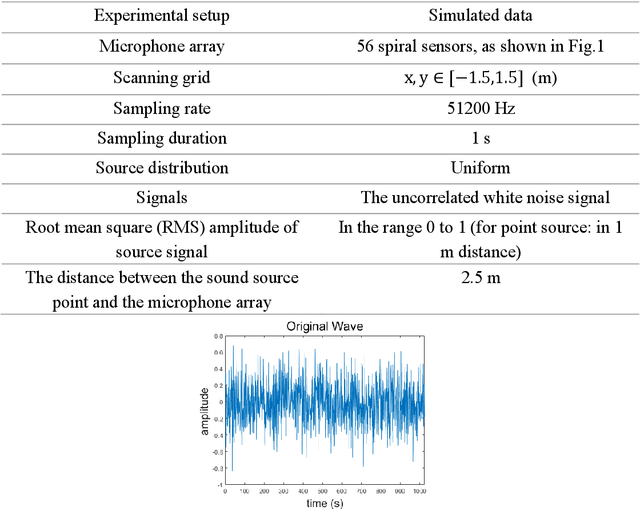
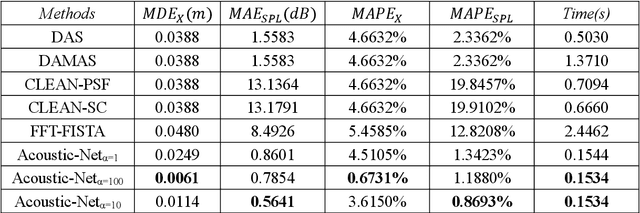
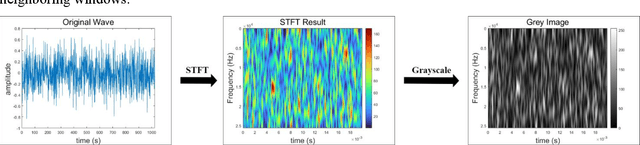
Acoustic source localization has been applied in different fields, such as aeronautics and ocean science, generally using multiple microphones array data to reconstruct the source location. However, the model-based beamforming methods fail to achieve the high-resolution of conventional beamforming maps. Deep neural networks are also appropriate to locate the sound source, but in general, these methods with complex network structures are hard to be recognized by hardware. In this paper, a novel neural network, termed the Acoustic-Net, is proposed to locate and quantify the sound source simply using the original signals. The experiments demonstrate that the proposed method significantly improves the accuracy of sound source prediction and the computing speed, which may generalize well to real data. The code and trained models are available at https://github.com/JoaquinChou/Acoustic-Net.