 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTree-Mamba: A Tree-Aware Mamba for Underwater Monocular Depth Estimation
Jul 10, 2025Underwater Monocular Depth Estimation (UMDE) is a critical task that aims to estimate high-precision depth maps from underwater degraded images caused by light absorption and scattering effects in marine environments. Recently, Mamba-based methods have achieved promising performance across various vision tasks; however, they struggle with the UMDE task because their inflexible state scanning strategies fail to model the structural features of underwater images effectively. Meanwhile, existing UMDE datasets usually contain unreliable depth labels, leading to incorrect object-depth relationships between underwater images and their corresponding depth maps. To overcome these limitations, we develop a novel tree-aware Mamba method, dubbed Tree-Mamba, for estimating accurate monocular depth maps from underwater degraded images. Specifically, we propose a tree-aware scanning strategy that adaptively constructs a minimum spanning tree based on feature similarity. The spatial topological features among the tree nodes are then flexibly aggregated through bottom-up and top-down traversals, enabling stronger multi-scale feature representation capabilities. Moreover, we construct an underwater depth estimation benchmark (called BlueDepth), which consists of 38,162 underwater image pairs with reliable depth labels. This benchmark serves as a foundational dataset for training existing deep learning-based UMDE methods to learn accurate object-depth relationships. Extensive experiments demonstrate the superiority of the proposed Tree-Mamba over several leading methods in both qualitative results and quantitative evaluations with competitive computational efficiency. Code and dataset will be available at https://wyjgr.github.io/Tree-Mamba.html.
V2V3D: View-to-View Denoised 3D Reconstruction for Light-Field Microscopy
Apr 10, 2025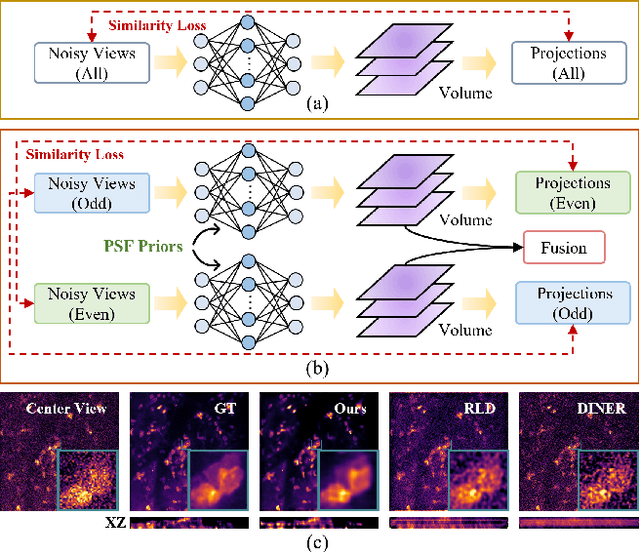
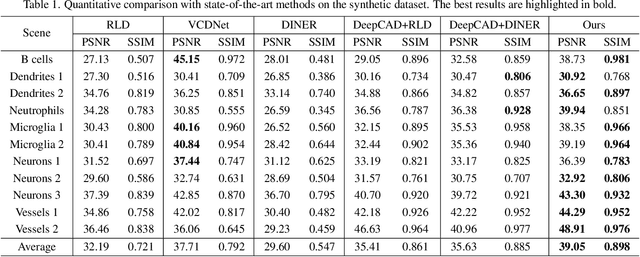
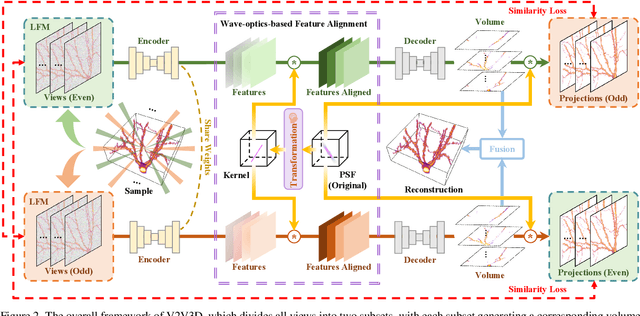
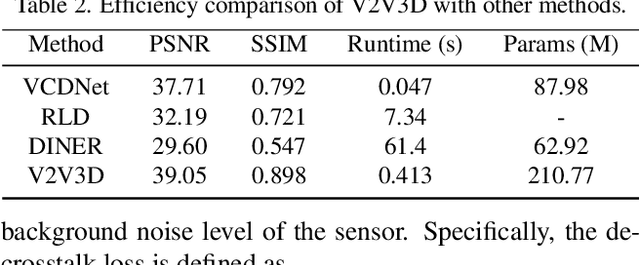
Light field microscopy (LFM) has gained significant attention due to its ability to capture snapshot-based, large-scale 3D fluorescence images. However, existing LFM reconstruction algorithms are highly sensitive to sensor noise or require hard-to-get ground-truth annotated data for training. To address these challenges, this paper introduces V2V3D, an unsupervised view2view-based framework that establishes a new paradigm for joint optimization of image denoising and 3D reconstruction in a unified architecture. We assume that the LF images are derived from a consistent 3D signal, with the noise in each view being independent. This enables V2V3D to incorporate the principle of noise2noise for effective denoising. To enhance the recovery of high-frequency details, we propose a novel wave-optics-based feature alignment technique, which transforms the point spread function, used for forward propagation in wave optics, into convolution kernels specifically designed for feature alignment. Moreover, we introduce an LFM dataset containing LF images and their corresponding 3D intensity volumes. Extensive experiments demonstrate that our approach achieves high computational efficiency and outperforms the other state-of-the-art methods. These advancements position V2V3D as a promising solution for 3D imaging under challenging conditions.
Unsupervised Low-light Image Enhancement with Lookup Tables and Diffusion Priors
Sep 27, 2024Low-light image enhancement (LIE) aims at precisely and efficiently recovering an image degraded in poor illumination environments. Recent advanced LIE techniques are using deep neural networks, which require lots of low-normal light image pairs, network parameters, and computational resources. As a result, their practicality is limited. In this work, we devise a novel unsupervised LIE framework based on diffusion priors and lookup tables (DPLUT) to achieve efficient low-light image recovery. The proposed approach comprises two critical components: a light adjustment lookup table (LLUT) and a noise suppression lookup table (NLUT). LLUT is optimized with a set of unsupervised losses. It aims at predicting pixel-wise curve parameters for the dynamic range adjustment of a specific image. NLUT is designed to remove the amplified noise after the light brightens. As diffusion models are sensitive to noise, diffusion priors are introduced to achieve high-performance noise suppression. Extensive experiments demonstrate that our approach outperforms state-of-the-art methods in terms of visual quality and efficiency.
AGLLDiff: Guiding Diffusion Models Towards Unsupervised Training-free Real-world Low-light Image Enhancement
Jul 23, 2024



Existing low-light image enhancement (LIE) methods have achieved noteworthy success in solving synthetic distortions, yet they often fall short in practical applications. The limitations arise from two inherent challenges in real-world LIE: 1) the collection of distorted/clean image pairs is often impractical and sometimes even unavailable, and 2) accurately modeling complex degradations presents a non-trivial problem. To overcome them, we propose the Attribute Guidance Diffusion framework (AGLLDiff), a training-free method for effective real-world LIE. Instead of specifically defining the degradation process, AGLLDiff shifts the paradigm and models the desired attributes, such as image exposure, structure and color of normal-light images. These attributes are readily available and impose no assumptions about the degradation process, which guides the diffusion sampling process to a reliable high-quality solution space. Extensive experiments demonstrate that our approach outperforms the current leading unsupervised LIE methods across benchmarks in terms of distortion-based and perceptual-based metrics, and it performs well even in sophisticated wild degradation.
Uncertainty Inspired Underwater Image Enhancement
Jul 20, 2022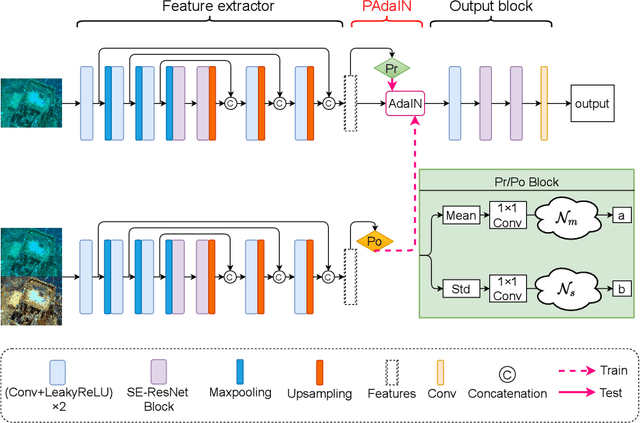
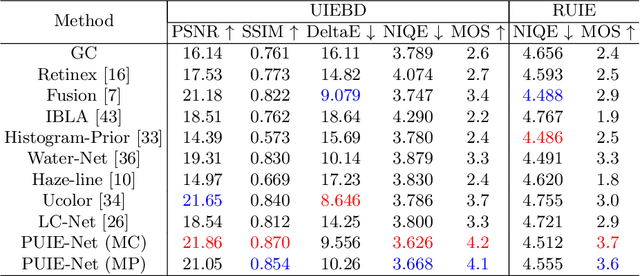


A main challenge faced in the deep learning-based Underwater Image Enhancement (UIE) is that the ground truth high-quality image is unavailable. Most of the existing methods first generate approximate reference maps and then train an enhancement network with certainty. This kind of method fails to handle the ambiguity of the reference map. In this paper, we resolve UIE into distribution estimation and consensus process. We present a novel probabilistic network to learn the enhancement distribution of degraded underwater images. Specifically, we combine conditional variational autoencoder with adaptive instance normalization to construct the enhancement distribution. After that, we adopt a consensus process to predict a deterministic result based on a set of samples from the distribution. By learning the enhancement distribution, our method can cope with the bias introduced in the reference map labeling to some extent. Additionally, the consensus process is useful to capture a robust and stable result. We examined the proposed method on two widely used real-world underwater image enhancement datasets. Experimental results demonstrate that our approach enables sampling possible enhancement predictions. Meanwhile, the consensus estimate yields competitive performance compared with state-of-the-art UIE methods. Code available at https://github.com/zhenqifu/PUIE-Net.
Underwater Image Enhancement via Learning Water Type Desensitized Representations
Feb 01, 2021
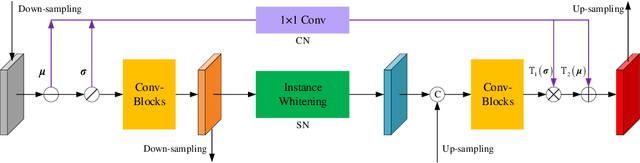


For underwater applications, the effects of light absorption and scattering result in image degradation. Moreover, the complex and changeable imaging environment makes it difficult to provide a universal enhancement solution to cope with the diversity of water types. In this letter, we present a novel underwater image enhancement (UIE) framework termed SCNet to address the above issues. SCNet is based on normalization schemes across both spatial and channel dimensions with the key idea of learning water type desensitized features. Considering the diversity of degradation is mainly rooted in the strong correlation among pixels, we apply whitening to de-correlates activations across spatial dimensions for each instance in a mini-batch. We also eliminate channel-wise correlation by standardizing and re-injecting the first two moments of the activations across channels. The normalization schemes of spatial and channel dimensions are performed at each scale of the U-Net to obtain multi-scale representations. With such latent encodings, the decoder can easily reconstruct the clean signal, and unaffected by the distortion types caused by the water. Experimental results on two real-world UIE datasets show that the proposed approach can successfully enhance images with diverse water types, and achieves competitive performance in visual quality improvement.
Twice Mixing: A Rank Learning based Quality Assessment Approach for Underwater Image Enhancement
Feb 01, 2021
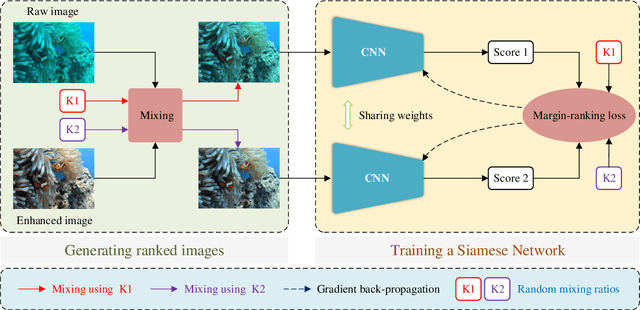


To improve the quality of underwater images, various kinds of underwater image enhancement (UIE) operators have been proposed during the past few years. However, the lack of effective objective evaluation methods limits the further development of UIE techniques. In this paper, we propose a novel rank learning guided no-reference quality assessment method for UIE. Our approach, termed Twice Mixing, is motivated by the observation that a mid-quality image can be generated by mixing a high-quality image with its low-quality version. Typical mixup algorithms linearly interpolate a given pair of input data. However, the human visual system is non-uniformity and non-linear in processing images. Therefore, instead of directly training a deep neural network based on the mixed images and their absolute scores calculated by linear combinations, we propose to train a Siamese Network to learn their quality rankings. Twice Mixing is trained based on an elaborately formulated self-supervision mechanism. Specifically, before each iteration, we randomly generate two mixing ratios which will be employed for both generating virtual images and guiding the network training. In the test phase, a single branch of the network is extracted to predict the quality rankings of different UIE outputs. We conduct extensive experiments on both synthetic and real-world datasets. Experimental results demonstrate that our approach outperforms the previous methods significantly.