 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Skeleton Understanding via Differentiable Rendering and MLLMs
Mar 18, 2026Multimodal large language models (MLLMs) exhibit strong visual-language reasoning, yet remain confined to their native modalities and cannot directly process structured, non-visual data such as human skeletons. Existing methods either compress skeleton dynamics into lossy feature vectors for text alignment, or quantize motion into discrete tokens that generalize poorly across heterogeneous skeleton formats. We present SkeletonLLM, which achieves universal skeleton understanding by translating arbitrary skeleton sequences into the MLLM's native visual modality. At its core is DrAction, a differentiable, format-agnostic renderer that converts skeletal kinematics into compact image sequences. Because the pipeline is end-to-end differentiable, MLLM gradients can directly guide the rendering to produce task-informative visual tokens. To further enhance reasoning capabilities, we introduce a cooperative training strategy: Causal Reasoning Distillation transfers structured, step-by-step reasoning from a teacher model, while Discriminative Finetuning sharpens decision boundaries between confusable actions. SkeletonLLM demonstrates strong generalization on diverse tasks including recognition, captioning, reasoning, and cross-format transfer -- suggesting a viable path for applying MLLMs to non-native modalities. Code will be released upon acceptance.
Uncertainty Inspired Underwater Image Enhancement
Jul 20, 2022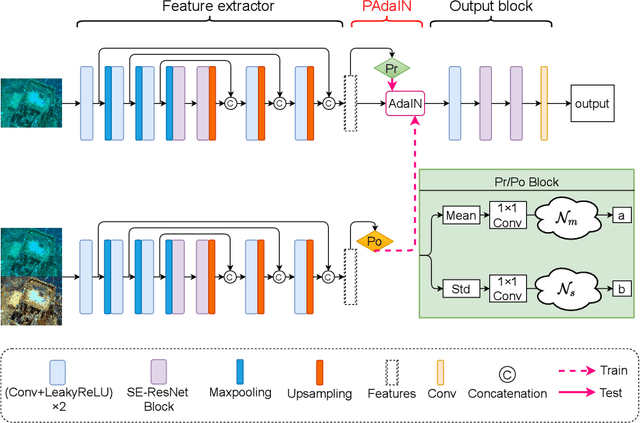
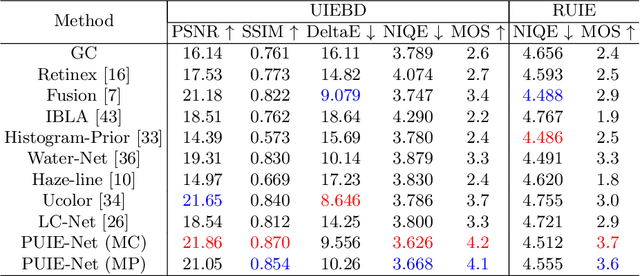


A main challenge faced in the deep learning-based Underwater Image Enhancement (UIE) is that the ground truth high-quality image is unavailable. Most of the existing methods first generate approximate reference maps and then train an enhancement network with certainty. This kind of method fails to handle the ambiguity of the reference map. In this paper, we resolve UIE into distribution estimation and consensus process. We present a novel probabilistic network to learn the enhancement distribution of degraded underwater images. Specifically, we combine conditional variational autoencoder with adaptive instance normalization to construct the enhancement distribution. After that, we adopt a consensus process to predict a deterministic result based on a set of samples from the distribution. By learning the enhancement distribution, our method can cope with the bias introduced in the reference map labeling to some extent. Additionally, the consensus process is useful to capture a robust and stable result. We examined the proposed method on two widely used real-world underwater image enhancement datasets. Experimental results demonstrate that our approach enables sampling possible enhancement predictions. Meanwhile, the consensus estimate yields competitive performance compared with state-of-the-art UIE methods. Code available at https://github.com/zhenqifu/PUIE-Net.
CMUA-Watermark: A Cross-Model Universal Adversarial Watermark for Combating Deepfakes
May 23, 2021

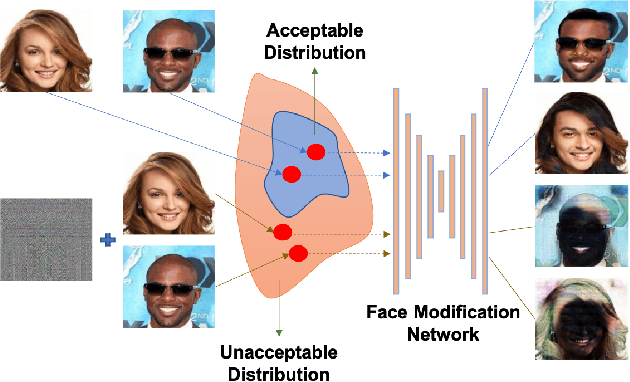

Malicious application of deepfakes (i.e., technologies can generate target faces or face attributes) has posed a huge threat to our society. The fake multimedia content generated by deepfake models can harm the reputation and even threaten the property of the person who has been impersonated. Fortunately, the adversarial watermark could be used for combating deepfake models, leading them to generate distorted images. The existing methods require an individual training process for every facial image, to generate the adversarial watermark against a specific deepfake model, which are extremely inefficient. To address this problem, we propose a universal adversarial attack method on deepfake models, to generate a Cross-Model Universal Adversarial Watermark (CMUA-Watermark) that can protect thousands of facial images from multiple deepfake models. Specifically, we first propose a cross-model universal attack pipeline by attacking multiple deepfake models and combining gradients from these models iteratively. Then we introduce a batch-based method to alleviate the conflict of adversarial watermarks generated by different facial images. Finally, we design a more reasonable and comprehensive evaluation method for evaluating the effectiveness of the adversarial watermark. Experimental results demonstrate that the proposed CMUA-Watermark can effectively distort the fake facial images generated by deepfake models and successfully protect facial images from deepfakes in real scenes.
RPATTACK: Refined Patch Attack on General Object Detectors
Mar 23, 2021



Nowadays, general object detectors like YOLO and Faster R-CNN as well as their variants are widely exploited in many applications. Many works have revealed that these detectors are extremely vulnerable to adversarial patch attacks. The perturbed regions generated by previous patch-based attack works on object detectors are very large which are not necessary for attacking and perceptible for human eyes. To generate much less but more efficient perturbation, we propose a novel patch-based method for attacking general object detectors. Firstly, we propose a patch selection and refining scheme to find the pixels which have the greatest importance for attack and remove the inconsequential perturbations gradually. Then, for a stable ensemble attack, we balance the gradients of detectors to avoid over-optimizing one of them during the training phase. Our RPAttack can achieve an amazing missed detection rate of 100% for both Yolo v4 and Faster R-CNN while only modifies 0.32% pixels on VOC 2007 test set. Our code is available at https://github.com/VDIGPKU/RPAttack.
Learning a Single Model with a Wide Range of Quality Factors for JPEG Image Artifacts Removal
Sep 15, 2020
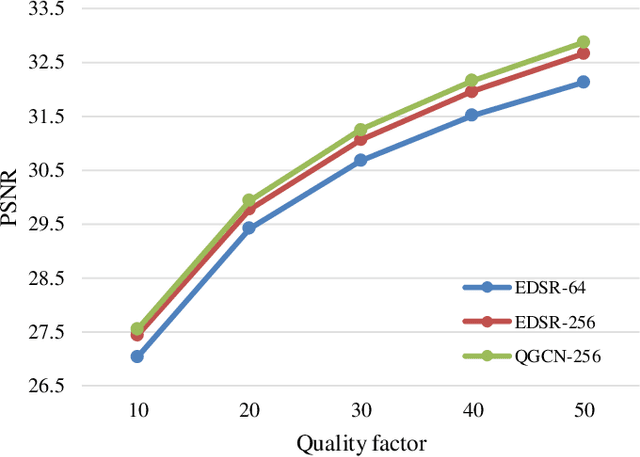
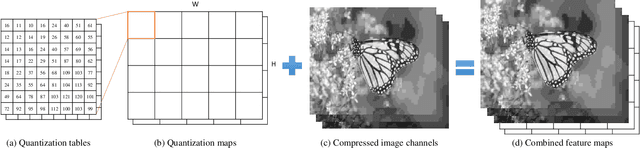
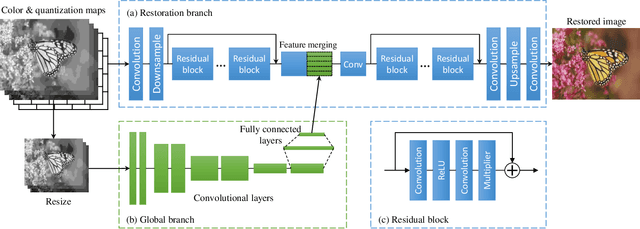
Lossy compression brings artifacts into the compressed image and degrades the visual quality. In recent years, many compression artifacts removal methods based on convolutional neural network (CNN) have been developed with great success. However, these methods usually train a model based on one specific value or a small range of quality factors. Obviously, if the test image's quality factor does not match to the assumed value range, then degraded performance will be resulted. With this motivation and further consideration of practical usage, a highly robust compression artifacts removal network is proposed in this paper. Our proposed network is a single model approach that can be trained for handling a wide range of quality factors while consistently delivering superior or comparable image artifacts removal performance. To demonstrate, we focus on the JPEG compression with quality factors, ranging from 1 to 60. Note that a turnkey success of our proposed network lies in the novel utilization of the quantization tables as part of the training data. Furthermore, it has two branches in parallel---i.e., the restoration branch and the global branch. The former effectively removes the local artifacts, such as ringing artifacts removal. On the other hand, the latter extracts the global features of the entire image that provides highly instrumental image quality improvement, especially effective on dealing with the global artifacts, such as blocking, color shifting. Extensive experimental results performed on color and grayscale images have clearly demonstrated the effectiveness and efficacy of our proposed single-model approach on the removal of compression artifacts from the decoded image.
PNEN: Pyramid Non-Local Enhanced Networks
Aug 22, 2020



Existing neural networks proposed for low-level image processing tasks are usually implemented by stacking convolution layers with limited kernel size. Every convolution layer merely involves in context information from a small local neighborhood. More contextual features can be explored as more convolution layers are adopted. However it is difficult and costly to take full advantage of long-range dependencies. We propose a novel non-local module, Pyramid Non-local Block, to build up connection between every pixel and all remain pixels. The proposed module is capable of efficiently exploiting pairwise dependencies between different scales of low-level structures. The target is fulfilled through first learning a query feature map with full resolution and a pyramid of reference feature maps with downscaled resolutions. Then correlations with multi-scale reference features are exploited for enhancing pixel-level feature representation. The calculation procedure is economical considering memory consumption and computational cost. Based on the proposed module, we devise a Pyramid Non-local Enhanced Networks for edge-preserving image smoothing which achieves state-of-the-art performance in imitating three classical image smoothing algorithms. Additionally, the pyramid non-local block can be directly incorporated into convolution neural networks for other image restoration tasks. We integrate it into two existing methods for image denoising and single image super-resolution, achieving consistently improved performance.