 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePurifying Generative LLMs from Backdoors without Prior Knowledge or Clean Reference
Mar 13, 2026Backdoor attacks pose severe security threats to large language models (LLMs), where a model behaves normally under benign inputs but produces malicious outputs when a hidden trigger appears. Existing backdoor removal methods typically assume prior knowledge of triggers, access to a clean reference model, or rely on aggressive finetuning configurations, and are often limited to classification tasks. However, such assumptions fall apart in real-world instruction-tuned LLM settings. In this work, we propose a new framework for purifying instruction-tuned LLM without any prior trigger knowledge or clean references. Through systematic sanity checks, we find that backdoor associations are redundantly encoded across MLP layers, while attention modules primarily amplify trigger signals without establishing the behavior. Leveraging this insight, we shift the focus from isolating specific backdoor triggers to cutting off the trigger-behavior associations, and design an immunization-inspired elimination approach: by constructing multiple synthetic backdoored variants of the given suspicious model, each trained with different malicious trigger-behavior pairs, and contrasting them with their clean counterparts. The recurring modifications across variants reveal a shared "backdoor signature"-analogous to antigens in a virus. Guided by this signature, we neutralize highly suspicious components in LLM and apply lightweight finetuning to restore its fluency, producing purified models that withstand diverse backdoor attacks and threat models while preserving generative capability.
Background Matters: A Cross-view Bidirectional Modeling Framework for Semi-supervised Medical Image Segmentation
May 22, 2025Semi-supervised medical image segmentation (SSMIS) leverages unlabeled data to reduce reliance on manually annotated images. However, current SOTA approaches predominantly focus on foreground-oriented modeling (i.e., segmenting only the foreground region) and have largely overlooked the potential benefits of explicitly modeling the background region. Our study theoretically and empirically demonstrates that highly certain predictions in background modeling enhance the confidence of corresponding foreground modeling. Building on this insight, we propose the Cross-view Bidirectional Modeling (CVBM) framework, which introduces a novel perspective by incorporating background modeling to improve foreground modeling performance. Within CVBM, background modeling serves as an auxiliary perspective, providing complementary supervisory signals to enhance the confidence of the foreground model. Additionally, CVBM introduces an innovative bidirectional consistency mechanism, which ensures mutual alignment between foreground predictions and background-guided predictions. Extensive experiments demonstrate that our approach achieves SOTA performance on the LA, Pancreas, ACDC, and HRF datasets. Notably, on the Pancreas dataset, CVBM outperforms fully supervised methods (i.e., DSC: 84.57% vs. 83.89%) while utilizing only 20% of the labeled data. Our code is publicly available at https://github.com/caoluyang0830/CVBM.git.
Superficial Safety Alignment Hypothesis
Oct 07, 2024As large language models (LLMs) are overwhelmingly more and more integrated into various applications, ensuring they generate safe and aligned responses is a pressing need. Previous research on alignment has largely focused on general instruction-following but has often overlooked the unique properties and challenges of safety alignment, such as the brittleness of safety mechanisms. To bridge the gap, we propose the Superficial Safety Alignment Hypothesis (SSAH), which posits that safety alignment should teach an otherwise unsafe model to choose the correct reasoning direction - interpreted as a specialized binary classification task - and incorporate a refusal mechanism with multiple reserved fallback options. Furthermore, through SSAH, we hypothesize that safety guardrails in LLMs can be established by just a small number of essential components. To verify this, we conduct an ablation study and successfully identify four types of attribute-critical components in safety-aligned LLMs: Exclusive Safety Unit (ESU), Exclusive Utility Unit (EUU), Complex Unit (CU), and Redundant Unit (RU). Our findings show that freezing certain safety-critical components 7.5\% during fine-tuning allows the model to retain its safety attributes while adapting to new tasks. Additionally, we show that leveraging redundant units 20\% in the pre-trained model as an ``alignment budget'' can effectively minimize the alignment tax while achieving the alignment goal. All considered, this paper concludes that the atomic functional unit for safety in LLMs is at the neuron level and underscores that safety alignment should not be complicated. We believe this work contributes to the foundation of efficient and scalable safety alignment for future LLMs.
Greedy Output Approximation: Towards Efficient Structured Pruning for LLMs Without Retraining
Jul 26, 2024To remove redundant components of large language models (LLMs) without incurring significant computational costs, this work focuses on single-shot pruning without a retraining phase. We simplify the pruning process for Transformer-based LLMs by identifying a depth-2 pruning structure that functions independently. Additionally, we propose two inference-aware pruning criteria derived from the optimization perspective of output approximation, which outperforms traditional training-aware metrics such as gradient and Hessian. We also introduce a two-step reconstruction technique to mitigate pruning errors without model retraining. Experimental results demonstrate that our approach significantly reduces computational costs and hardware requirements while maintaining superior performance across various datasets and models.
AI-Generated Text Detection and Classification Based on BERT Deep Learning Algorithm
May 26, 2024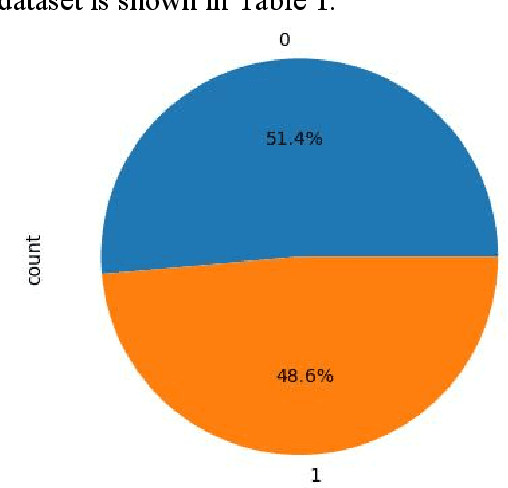
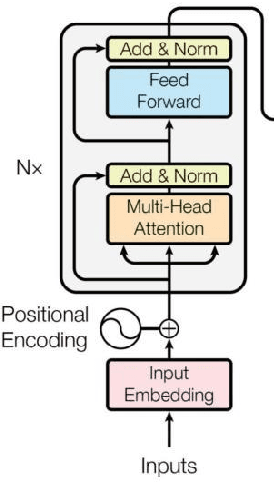
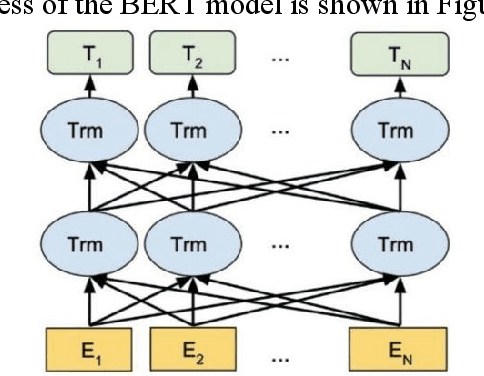
AI-generated text detection plays an increasingly important role in various fields. In this study, we developed an efficient AI-generated text detection model based on the BERT algorithm, which provides new ideas and methods for solving related problems. In the data preprocessing stage, a series of steps were taken to process the text, including operations such as converting to lowercase, word splitting, removing stop words, stemming extraction, removing digits, and eliminating redundant spaces, to ensure data quality and accuracy. By dividing the dataset into a training set and a test set in the ratio of 60% and 40%, and observing the changes in the accuracy and loss values during the training process, we found that the model performed well during the training process. The accuracy increases steadily from the initial 94.78% to 99.72%, while the loss value decreases from 0.261 to 0.021 and converges gradually, which indicates that the BERT model is able to detect AI-generated text with high accuracy and the prediction results are gradually approaching the real classification results. Further analysis of the results of the training and test sets reveals that in terms of loss value, the average loss of the training set is 0.0565, while the average loss of the test set is 0.0917, showing a slightly higher loss value. As for the accuracy, the average accuracy of the training set reaches 98.1%, while the average accuracy of the test set is 97.71%, which is not much different from each other, indicating that the model has good generalisation ability. In conclusion, the AI-generated text detection model based on the BERT algorithm proposed in this study shows high accuracy and stability in experiments, providing an effective solution for related fields.
FP8-BERT: Post-Training Quantization for Transformer
Dec 12, 2023Transformer-based models, such as BERT, have been widely applied in a wide range of natural language processing tasks. However, one inevitable side effect is that they require massive memory storage and inference cost when deployed in production. Quantization is one of the popularized ways to alleviate the cost. However, the previous 8-bit quantization strategy based on INT8 data format either suffers from the degradation of accuracy in a Post-Training Quantization (PTQ) fashion or requires an expensive Quantization-Aware Training (QAT) process. Recently, a new numeric format FP8 (i.e. floating-point of 8-bits) has been proposed and supported in commercial AI computing platforms such as H100. In this paper, we empirically validate the effectiveness of FP8 as a way to do Post-Training Quantization without significant loss of accuracy, with a simple calibration and format conversion process. We adopt the FP8 standard proposed by NVIDIA Corp. (2022) in our extensive experiments of BERT variants on GLUE and SQuAD v1.1 datasets, and show that PTQ with FP8 can significantly improve the accuracy upon that with INT8, to the extent of the full-precision model.
Beyond Gradient and Priors in Privacy Attacks: Leveraging Pooler Layer Inputs of Language Models in Federated Learning
Dec 10, 2023
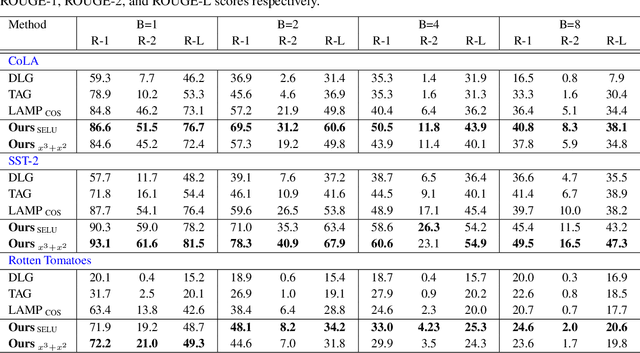
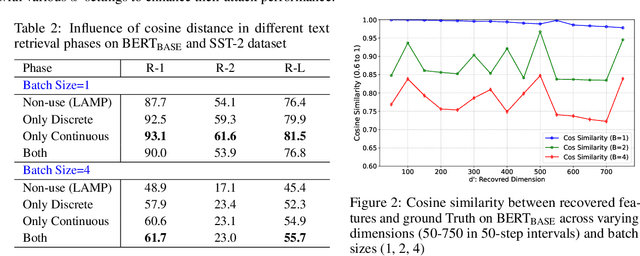
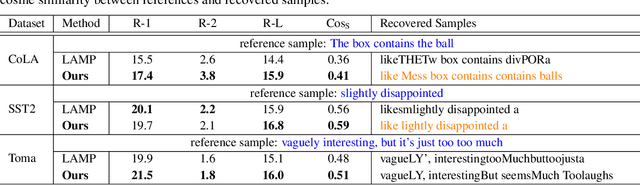
Federated learning (FL) emphasizes decentralized training by storing data locally and sending only model updates, underlining user privacy. Recently, a line of works on privacy attacks impairs user privacy by extracting sensitive training text from language models in the context of FL. Yet, these attack techniques face distinct hurdles: some work chiefly with limited batch sizes (e.g., batch size of 1), and others are easily detectable. This paper introduces an innovative approach that is challenging to detect, significantly enhancing the recovery rate of text in various batch-size settings. Building on fundamental gradient matching and domain prior knowledge, we enhance the attack by recovering the input of the Pooler layer of language models, which enables us to provide additional supervised signals at the feature level. Unlike gradient data, these signals do not average across sentences and tokens, thereby offering more nuanced and effective insights. We benchmark our method using text classification tasks on datasets such as CoLA, SST-2, and Rotten Tomatoes. Across different batch sizes and models, our approach consistently outperforms previous state-of-the-art results.
Breaking through Deterministic Barriers: Randomized Pruning Mask Generation and Selection
Oct 19, 2023It is widely acknowledged that large and sparse models have higher accuracy than small and dense models under the same model size constraints. This motivates us to train a large model and then remove its redundant neurons or weights by pruning. Most existing works pruned the networks in a deterministic way, the performance of which solely depends on a single pruning criterion and thus lacks variety. Instead, in this paper, we propose a model pruning strategy that first generates several pruning masks in a designed random way. Subsequently, along with an effective mask-selection rule, the optimal mask is chosen from the pool of mask candidates. To further enhance efficiency, we introduce an early mask evaluation strategy, mitigating the overhead associated with training multiple masks. Our extensive experiments demonstrate that this approach achieves state-of-the-art performance across eight datasets from GLUE, particularly excelling at high levels of sparsity.
Towards Robust Pruning: An Adaptive Knowledge-Retention Pruning Strategy for Language Models
Oct 19, 2023The pruning objective has recently extended beyond accuracy and sparsity to robustness in language models. Despite this, existing methods struggle to enhance robustness against adversarial attacks when continually increasing model sparsity and require a retraining process. As humans step into the era of large language models, these issues become increasingly prominent. This paper proposes that the robustness of language models is proportional to the extent of pre-trained knowledge they encompass. Accordingly, we introduce a post-training pruning strategy designed to faithfully replicate the embedding space and feature space of dense language models, aiming to conserve more pre-trained knowledge during the pruning process. In this setup, each layer's reconstruction error not only originates from itself but also includes cumulative error from preceding layers, followed by an adaptive rectification. Compared to other state-of-art baselines, our approach demonstrates a superior balance between accuracy, sparsity, robustness, and pruning cost with BERT on datasets SST2, IMDB, and AGNews, marking a significant stride towards robust pruning in language models.
Accelerating Vision Transformers Based on Heterogeneous Attention Patterns
Oct 11, 2023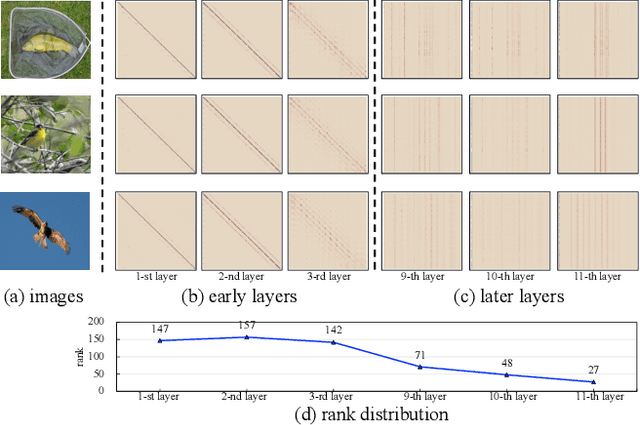
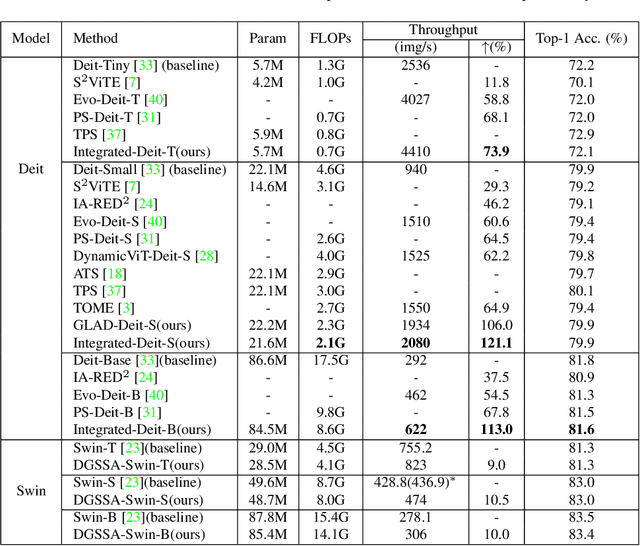
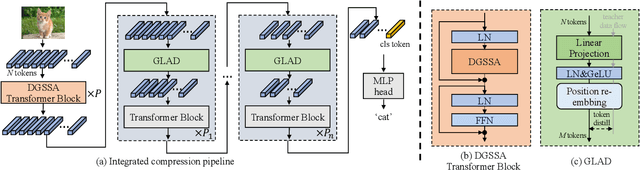
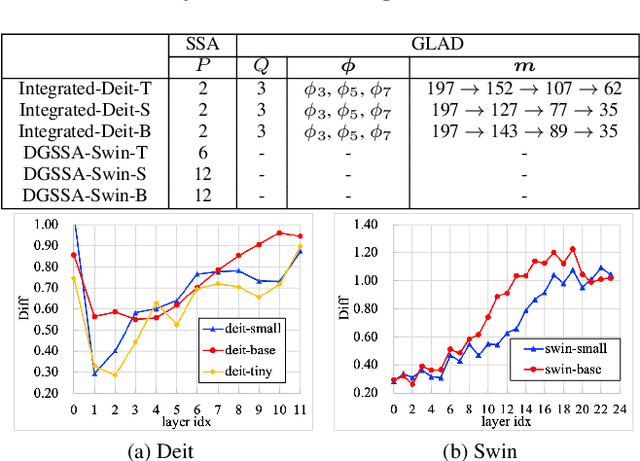
Recently, Vision Transformers (ViTs) have attracted a lot of attention in the field of computer vision. Generally, the powerful representative capacity of ViTs mainly benefits from the self-attention mechanism, which has a high computation complexity. To accelerate ViTs, we propose an integrated compression pipeline based on observed heterogeneous attention patterns across layers. On one hand, different images share more similar attention patterns in early layers than later layers, indicating that the dynamic query-by-key self-attention matrix may be replaced with a static self-attention matrix in early layers. Then, we propose a dynamic-guided static self-attention (DGSSA) method where the matrix inherits self-attention information from the replaced dynamic self-attention to effectively improve the feature representation ability of ViTs. On the other hand, the attention maps have more low-rank patterns, which reflect token redundancy, in later layers than early layers. In a view of linear dimension reduction, we further propose a method of global aggregation pyramid (GLAD) to reduce the number of tokens in later layers of ViTs, such as Deit. Experimentally, the integrated compression pipeline of DGSSA and GLAD can accelerate up to 121% run-time throughput compared with DeiT, which surpasses all SOTA approaches.