 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Gradient and Priors in Privacy Attacks: Leveraging Pooler Layer Inputs of Language Models in Federated Learning
Paper and Code

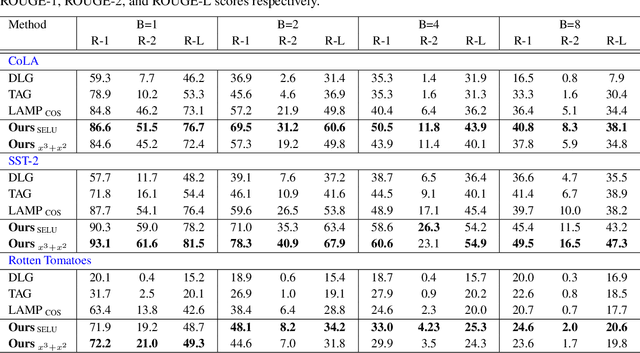
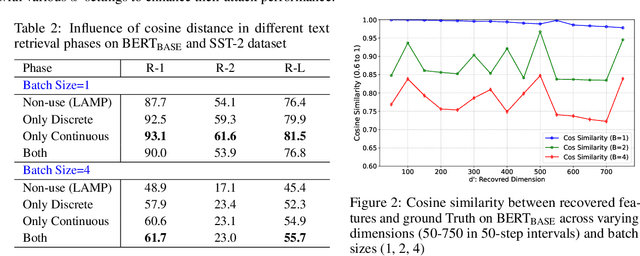
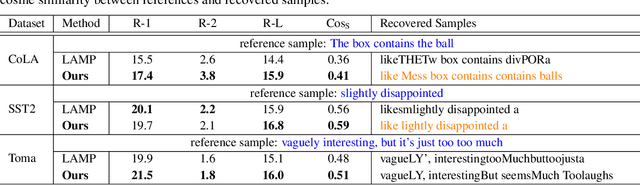
Federated learning (FL) emphasizes decentralized training by storing data locally and sending only model updates, underlining user privacy. Recently, a line of works on privacy attacks impairs user privacy by extracting sensitive training text from language models in the context of FL. Yet, these attack techniques face distinct hurdles: some work chiefly with limited batch sizes (e.g., batch size of 1), and others are easily detectable. This paper introduces an innovative approach that is challenging to detect, significantly enhancing the recovery rate of text in various batch-size settings. Building on fundamental gradient matching and domain prior knowledge, we enhance the attack by recovering the input of the Pooler layer of language models, which enables us to provide additional supervised signals at the feature level. Unlike gradient data, these signals do not average across sentences and tokens, thereby offering more nuanced and effective insights. We benchmark our method using text classification tasks on datasets such as CoLA, SST-2, and Rotten Tomatoes. Across different batch sizes and models, our approach consistently outperforms previous state-of-the-art results.