 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Vision Transformers Based on Heterogeneous Attention Patterns
Paper and Code
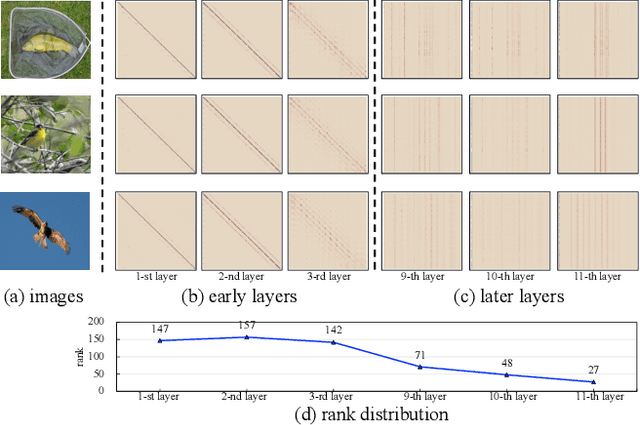
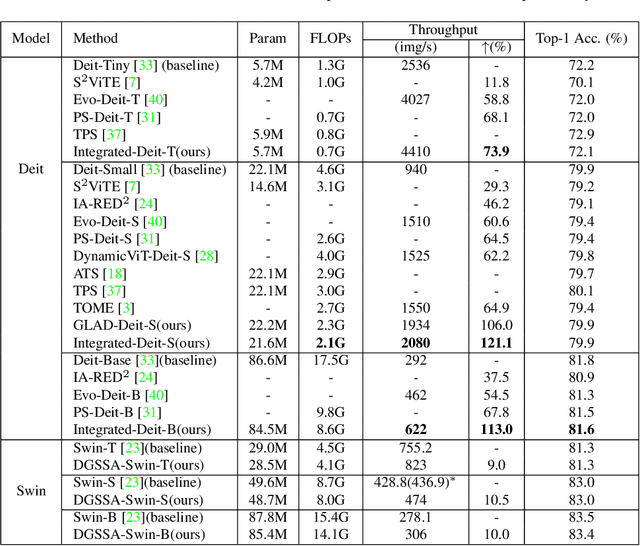
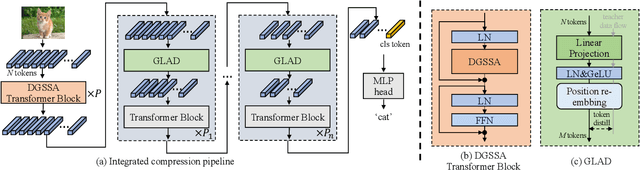
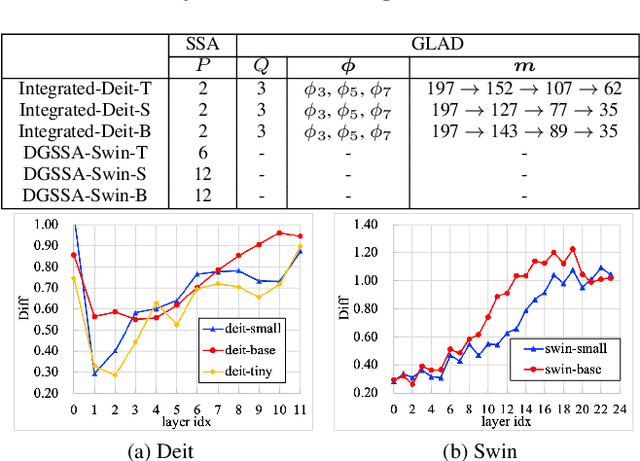
Recently, Vision Transformers (ViTs) have attracted a lot of attention in the field of computer vision. Generally, the powerful representative capacity of ViTs mainly benefits from the self-attention mechanism, which has a high computation complexity. To accelerate ViTs, we propose an integrated compression pipeline based on observed heterogeneous attention patterns across layers. On one hand, different images share more similar attention patterns in early layers than later layers, indicating that the dynamic query-by-key self-attention matrix may be replaced with a static self-attention matrix in early layers. Then, we propose a dynamic-guided static self-attention (DGSSA) method where the matrix inherits self-attention information from the replaced dynamic self-attention to effectively improve the feature representation ability of ViTs. On the other hand, the attention maps have more low-rank patterns, which reflect token redundancy, in later layers than early layers. In a view of linear dimension reduction, we further propose a method of global aggregation pyramid (GLAD) to reduce the number of tokens in later layers of ViTs, such as Deit. Experimentally, the integrated compression pipeline of DGSSA and GLAD can accelerate up to 121% run-time throughput compared with DeiT, which surpasses all SOTA approaches.