 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenseSteer: Steering Small Language Models towards Dense Math Reasoning
May 28, 2026Large language models (LLMs) demonstrate strong chain-of-thought (CoT) reasoning abilities, while smaller models (<= 3B parameters) significantly underperform on multi-step reasoning tasks. Based on empirical analyses of the Qwen-2.5 model family on math reasoning benchmarks, we find that more proficient reasoning is associated with fewer reasoning steps but higher information density per step, a property we term Dense Reasoning. Motivated by this observation, we propose DenseSteer, a training-free inference-time steering framework that enhances small-model reasoning by modulating internal representations toward dense reasoning patterns. Experiments show that our method yields consistent accuracy improvements without increasing token-level Negative Log-Likelihood, highlighting dense reasoning as an effective structural approach to mathematical problem solving.
Position: Retire the "Positive Backdoor" Label -- Secret Alignment Requires Strict and Systematic Evaluation
May 27, 2026This position paper argues that the AI/ML community should stop overclaiming and retire the label "positive backdoor," and instead treat trigger-activated hidden behaviors as Secret Alignment. Crucially, protective claims based on Secret Alignment should be presumed not secure by default unless supported by rigorous, standardized evaluation. The Private AI era, enabled by open-weight LLMs and accessible training/inference stacks, turns language models into privately owned digital assets, creating security concerns around unauthorized access, model theft, and behavioral misuse. Recently, a line of work framed as "positive backdoors" has been proposed to address these challenges. To ground our position in evidence, we unify these proposals as covert trigger-behavior associations for access gating, ownership attribution, and safety enforcement, and evaluate three representative applications across six core properties: effectiveness, harmlessness, persistence, efficiency, robustness, and reliability. Our results reveal substantial brittleness - especially in the confidentiality, integrity, and availability (CIA) - of trigger-behavior mappings often underrepresented by existing claims. We further relate these outcomes to behavior density and decision complexity, offering a behavioral lens for understanding deployment-time risks and motivating community-wide evaluation that makes Secret Alignment claims provable.
Learnability and Privacy Vulnerability are Entangled in a Few Critical Weights
Mar 13, 2026Prior approaches for membership privacy preservation usually update or retrain all weights in neural networks, which is costly and can lead to unnecessary utility loss or even more serious misalignment in predictions between training data and non-training data. In this work, we observed three insights: i) privacy vulnerability exists in a very small fraction of weights; ii) however, most of those weights also critically impact utility performance; iii) the importance of weights stems from their locations rather than their values. According to these insights, to preserve privacy, we score critical weights, and instead of discarding those neurons, we rewind only the weights for fine-tuning. We show that, through extensive experiments, this mechanism exhibits outperforming resilience in most cases against Membership Inference Attacks while maintaining utility.
Purifying Generative LLMs from Backdoors without Prior Knowledge or Clean Reference
Mar 13, 2026Backdoor attacks pose severe security threats to large language models (LLMs), where a model behaves normally under benign inputs but produces malicious outputs when a hidden trigger appears. Existing backdoor removal methods typically assume prior knowledge of triggers, access to a clean reference model, or rely on aggressive finetuning configurations, and are often limited to classification tasks. However, such assumptions fall apart in real-world instruction-tuned LLM settings. In this work, we propose a new framework for purifying instruction-tuned LLM without any prior trigger knowledge or clean references. Through systematic sanity checks, we find that backdoor associations are redundantly encoded across MLP layers, while attention modules primarily amplify trigger signals without establishing the behavior. Leveraging this insight, we shift the focus from isolating specific backdoor triggers to cutting off the trigger-behavior associations, and design an immunization-inspired elimination approach: by constructing multiple synthetic backdoored variants of the given suspicious model, each trained with different malicious trigger-behavior pairs, and contrasting them with their clean counterparts. The recurring modifications across variants reveal a shared "backdoor signature"-analogous to antigens in a virus. Guided by this signature, we neutralize highly suspicious components in LLM and apply lightweight finetuning to restore its fluency, producing purified models that withstand diverse backdoor attacks and threat models while preserving generative capability.
Decoupling Generalizability and Membership Privacy Risks in Neural Networks
Feb 02, 2026A deep learning model usually has to sacrifice some utilities when it acquires some other abilities or characteristics. Privacy preservation has such trade-off relationships with utilities. The loss disparity between various defense approaches implies the potential to decouple generalizability and privacy risks to maximize privacy gain. In this paper, we identify that the model's generalization and privacy risks exist in different regions in deep neural network architectures. Based on the observations that we investigate, we propose Privacy-Preserving Training Principle (PPTP) to protect model components from privacy risks while minimizing the loss in generalizability. Through extensive evaluations, our approach shows significantly better maintenance in model generalizability while enhancing privacy preservation.
Impact of Layer Norm on Memorization and Generalization in Transformers
Nov 13, 2025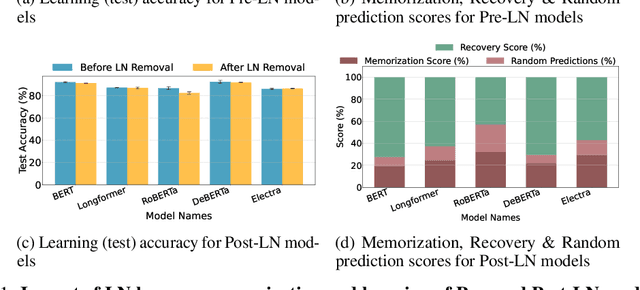
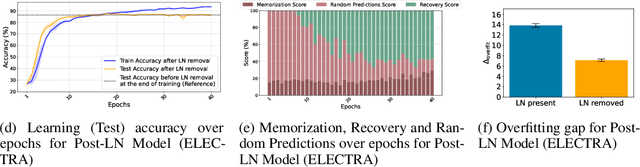
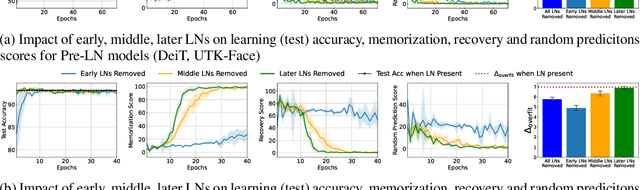
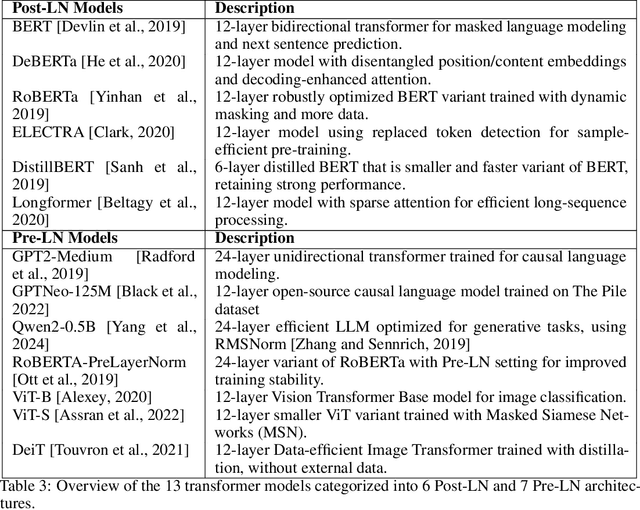
Layer Normalization (LayerNorm) is one of the fundamental components in transformers that stabilizes training and improves optimization. In recent times, Pre-LayerNorm transformers have become the preferred choice over Post-LayerNorm transformers due to their stable gradient flow. However, the impact of LayerNorm on learning and memorization across these architectures remains unclear. In this work, we investigate how LayerNorm influences memorization and learning for Pre- and Post-LayerNorm transformers. We identify that LayerNorm serves as a key factor for stable learning in Pre-LayerNorm transformers, while in Post-LayerNorm transformers, it impacts memorization. Our analysis reveals that eliminating LayerNorm parameters in Pre-LayerNorm models exacerbates memorization and destabilizes learning, while in Post-LayerNorm models, it effectively mitigates memorization by restoring genuine labels. We further precisely identify that early layers LayerNorm are the most critical over middle/later layers and their influence varies across Pre and Post LayerNorm models. We have validated it through 13 models across 6 Vision and Language datasets. These insights shed new light on the role of LayerNorm in shaping memorization and learning in transformers.
Explaining How Quantization Disparately Skews a Model
Sep 08, 2025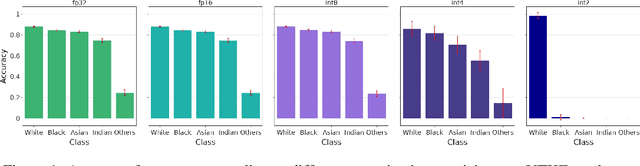
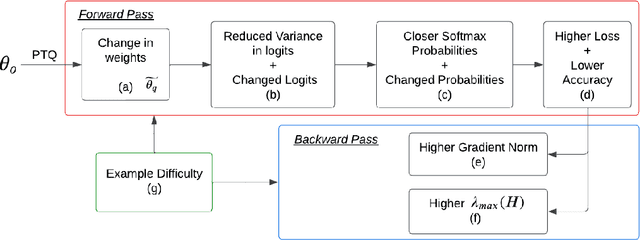
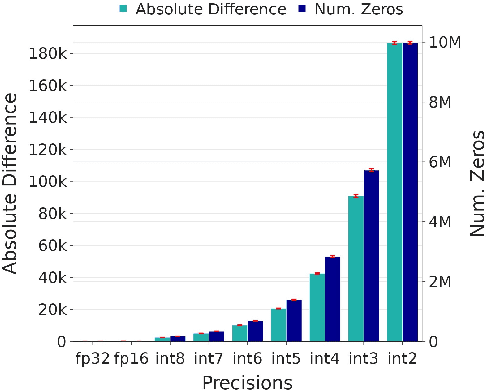
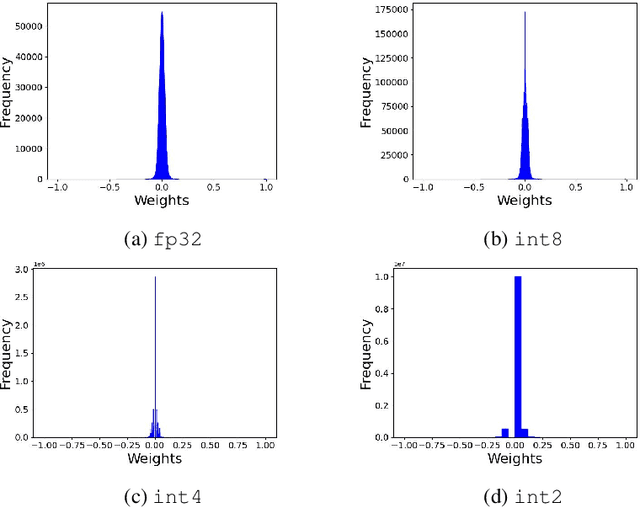
Post Training Quantization (PTQ) is widely adopted due to its high compression capacity and speed with minimal impact on accuracy. However, we observed that disparate impacts are exacerbated by quantization, especially for minority groups. Our analysis explains that in the course of quantization there is a chain of factors attributed to a disparate impact across groups during forward and backward passes. We explore how the changes in weights and activations induced by quantization cause cascaded impacts in the network, resulting in logits with lower variance, increased loss, and compromised group accuracies. We extend our study to verify the influence of these impacts on group gradient norms and eigenvalues of the Hessian matrix, providing insights into the state of the network from an optimization point of view. To mitigate these effects, we propose integrating mixed precision Quantization Aware Training (QAT) with dataset sampling methods and weighted loss functions, therefore providing fair deployment of quantized neural networks.
RESQUE: Quantifying Estimator to Task and Distribution Shift for Sustainable Model Reusability
Dec 20, 2024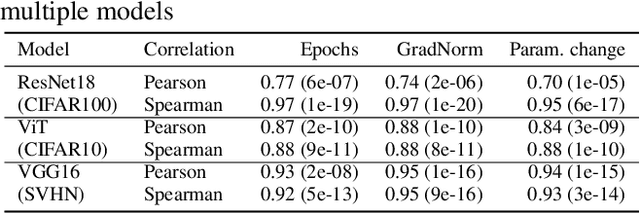
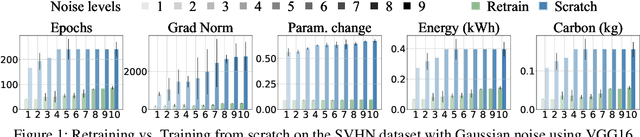
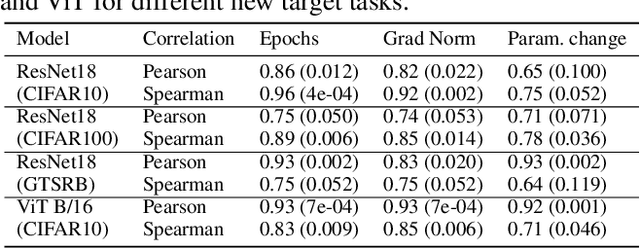
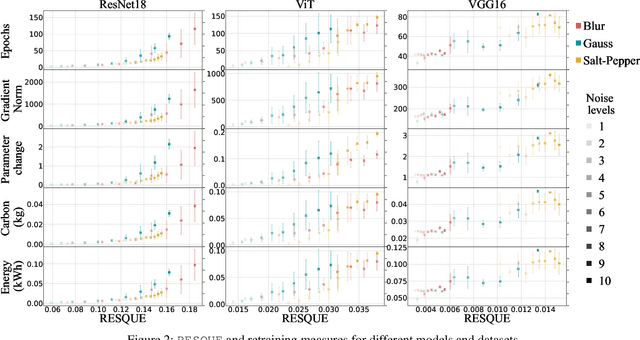
As a strategy for sustainability of deep learning, reusing an existing model by retraining it rather than training a new model from scratch is critical. In this paper, we propose REpresentation Shift QUantifying Estimator (RESQUE), a predictive quantifier to estimate the retraining cost of a model to distributional shifts or change of tasks. It provides a single concise index for an estimate of resources required for retraining the model. Through extensive experiments, we show that RESQUE has a strong correlation with various retraining measures. Our results validate that RESQUE is an effective indicator in terms of epochs, gradient norms, changes of parameter magnitude, energy, and carbon emissions. These measures align well with RESQUE for new tasks, multiple noise types, and varying noise intensities. As a result, RESQUE enables users to make informed decisions for retraining to different tasks/distribution shifts and determine the most cost-effective and sustainable option, allowing for the reuse of a model with a much smaller footprint in the environment. The code for this work is available here: https://github.com/JEKimLab/AAAI2025RESQUE
Superficial Safety Alignment Hypothesis
Oct 07, 2024As large language models (LLMs) are overwhelmingly more and more integrated into various applications, ensuring they generate safe and aligned responses is a pressing need. Previous research on alignment has largely focused on general instruction-following but has often overlooked the unique properties and challenges of safety alignment, such as the brittleness of safety mechanisms. To bridge the gap, we propose the Superficial Safety Alignment Hypothesis (SSAH), which posits that safety alignment should teach an otherwise unsafe model to choose the correct reasoning direction - interpreted as a specialized binary classification task - and incorporate a refusal mechanism with multiple reserved fallback options. Furthermore, through SSAH, we hypothesize that safety guardrails in LLMs can be established by just a small number of essential components. To verify this, we conduct an ablation study and successfully identify four types of attribute-critical components in safety-aligned LLMs: Exclusive Safety Unit (ESU), Exclusive Utility Unit (EUU), Complex Unit (CU), and Redundant Unit (RU). Our findings show that freezing certain safety-critical components 7.5\% during fine-tuning allows the model to retain its safety attributes while adapting to new tasks. Additionally, we show that leveraging redundant units 20\% in the pre-trained model as an ``alignment budget'' can effectively minimize the alignment tax while achieving the alignment goal. All considered, this paper concludes that the atomic functional unit for safety in LLMs is at the neuron level and underscores that safety alignment should not be complicated. We believe this work contributes to the foundation of efficient and scalable safety alignment for future LLMs.
Representation Magnitude has a Liability to Privacy Vulnerability
Jul 23, 2024
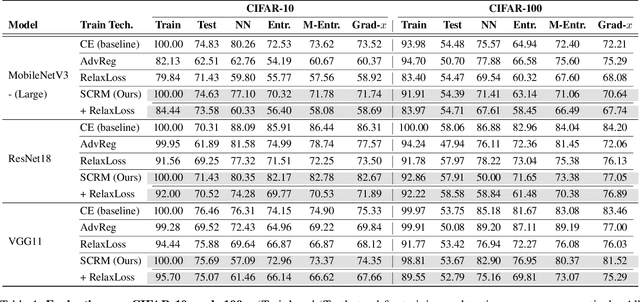
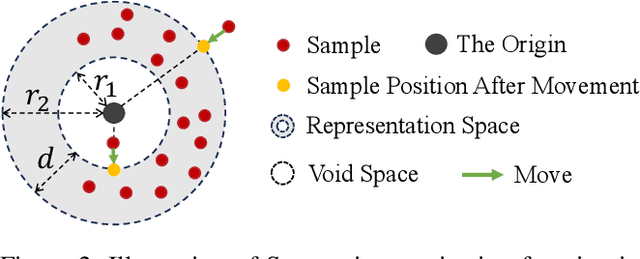
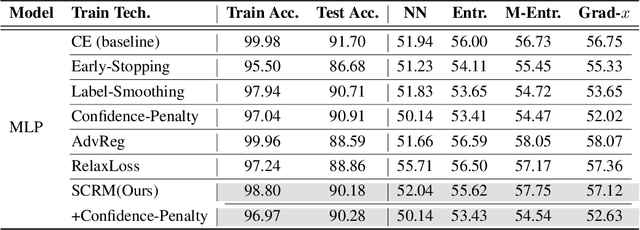
The privacy-preserving approaches to machine learning (ML) models have made substantial progress in recent years. However, it is still opaque in which circumstances and conditions the model becomes privacy-vulnerable, leading to a challenge for ML models to maintain both performance and privacy. In this paper, we first explore the disparity between member and non-member data in the representation of models under common training frameworks. We identify how the representation magnitude disparity correlates with privacy vulnerability and address how this correlation impacts privacy vulnerability. Based on the observations, we propose Saturn Ring Classifier Module (SRCM), a plug-in model-level solution to mitigate membership privacy leakage. Through a confined yet effective representation space, our approach ameliorates models' privacy vulnerability while maintaining generalizability. The code of this work can be found here: \url{https://github.com/JEKimLab/AIES2024_SRCM}