 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Environmental Cost Throughout Model's Adaptive Life Cycle
Jul 23, 2024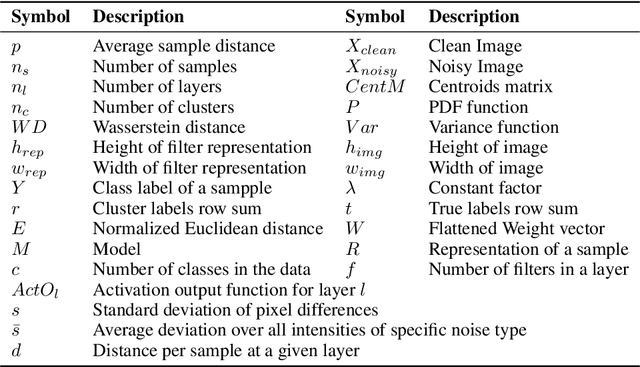

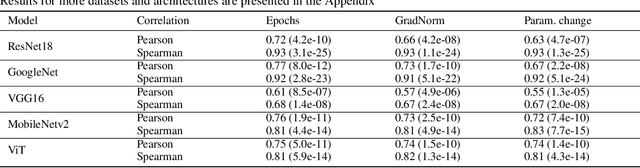
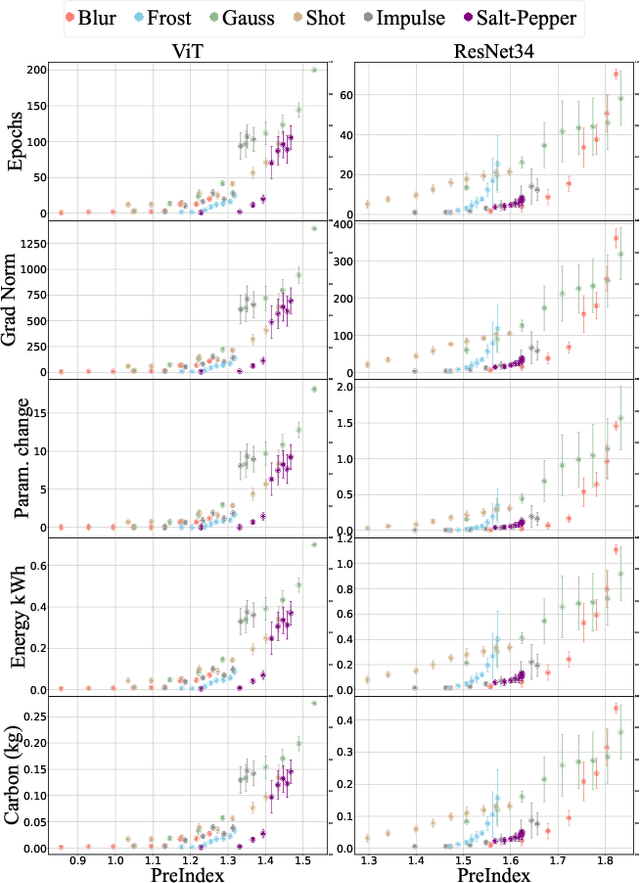
With the rapid increase in the research, development, and application of neural networks in the current era, there is a proportional increase in the energy needed to train and use models. Crucially, this is accompanied by the increase in carbon emissions into the environment. A sustainable and socially beneficial approach to reducing the carbon footprint and rising energy demands associated with the modern age of AI/deep learning is the adaptive and continuous reuse of models with regard to changes in the environment of model deployment or variations/changes in the input data. In this paper, we propose PreIndex, a predictive index to estimate the environmental and compute resources associated with model retraining to distributional shifts in data. PreIndex can be used to estimate environmental costs such as carbon emissions and energy usage when retraining from current data distribution to new data distribution. It also correlates with and can be used to estimate other resource indicators associated with deep learning, such as epochs, gradient norm, and magnitude of model parameter change. PreIndex requires only one forward pass of the data, following which it provides a single concise value to estimate resources associated with retraining to the new distribution shifted data. We show that PreIndex can be reliably used across various datasets, model architectures, different types, and intensities of distribution shifts. Thus, PreIndex enables users to make informed decisions for retraining to different distribution shifts and determine the most cost-effective and sustainable option, allowing for the reuse of a model with a much smaller footprint in the environment. The code for this work is available here: https://github.com/JEKimLab/AIES2024PreIndex
Aggregate Representation Measure for Predictive Model Reusability
May 15, 2024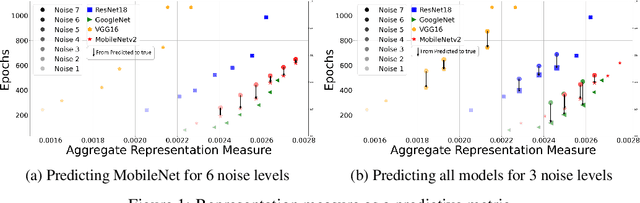
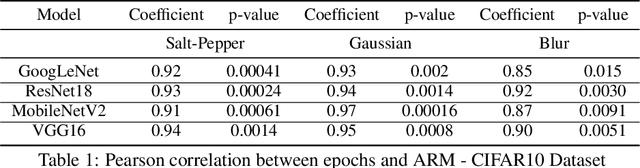
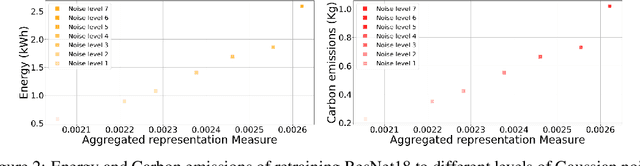
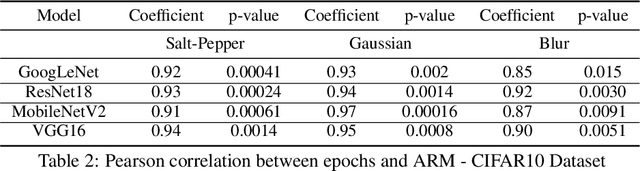
In this paper, we propose a predictive quantifier to estimate the retraining cost of a trained model in distribution shifts. The proposed Aggregated Representation Measure (ARM) quantifies the change in the model's representation from the old to new data distribution. It provides, before actually retraining the model, a single concise index of resources - epochs, energy, and carbon emissions - required for the retraining. This enables reuse of a model with a much lower cost than training a new model from scratch. The experimental results indicate that ARM reasonably predicts retraining costs for varying noise intensities and enables comparisons among multiple model architectures to determine the most cost-effective and sustainable option.
Cooperative Learning for Cost-Adaptive Inference
Dec 26, 2023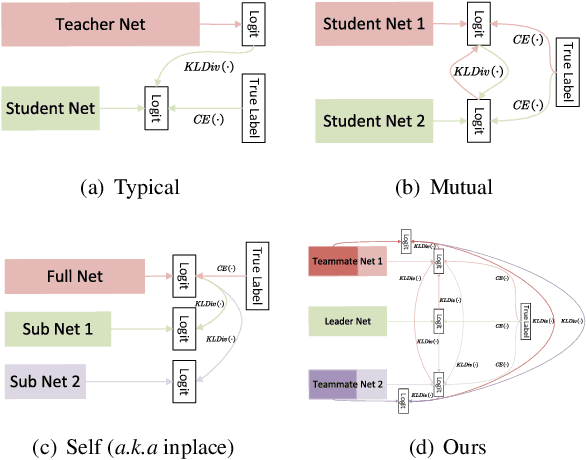
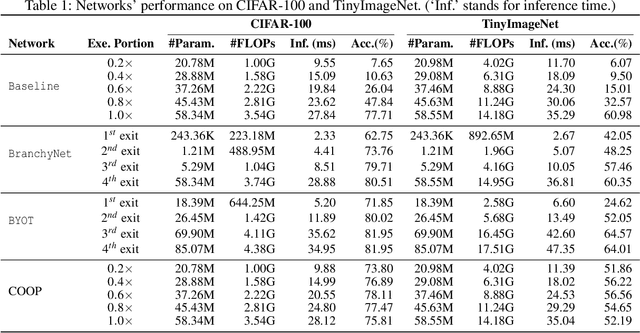
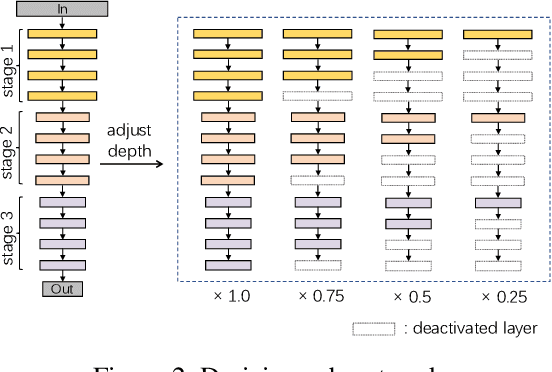
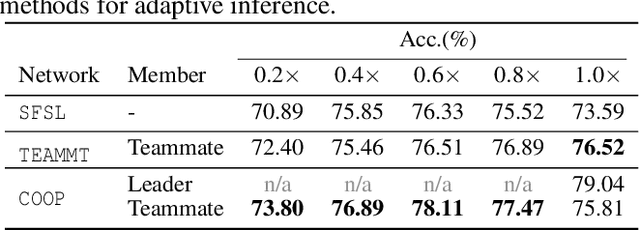
We propose a cooperative training framework for deep neural network architectures that enables the runtime network depths to change to satisfy dynamic computing resource requirements. In our framework, the number of layers participating in computation can be chosen dynamically to meet performance-cost trade-offs at inference runtime. Our method trains two Teammate nets and a Leader net, and two sets of Teammate sub-networks with various depths through knowledge distillation. The Teammate nets derive sub-networks and transfer knowledge to them, and to each other, while the Leader net guides Teammate nets to ensure accuracy. The approach trains the framework atomically at once instead of individually training various sizes of models; in a sense, the various-sized networks are all trained at once, in a "package deal." The proposed framework is not tied to any specific architecture but can incorporate any existing models/architectures, therefore it can maintain stable results and is insensitive to the size of a dataset's feature map. Compared with other related approaches, it provides comparable accuracy to its full network while various sizes of models are available.