 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupling Generalizability and Membership Privacy Risks in Neural Networks
Feb 02, 2026A deep learning model usually has to sacrifice some utilities when it acquires some other abilities or characteristics. Privacy preservation has such trade-off relationships with utilities. The loss disparity between various defense approaches implies the potential to decouple generalizability and privacy risks to maximize privacy gain. In this paper, we identify that the model's generalization and privacy risks exist in different regions in deep neural network architectures. Based on the observations that we investigate, we propose Privacy-Preserving Training Principle (PPTP) to protect model components from privacy risks while minimizing the loss in generalizability. Through extensive evaluations, our approach shows significantly better maintenance in model generalizability while enhancing privacy preservation.
Representation Magnitude has a Liability to Privacy Vulnerability
Jul 23, 2024The privacy-preserving approaches to machine learning (ML) models have made substantial progress in recent years. However, it is still opaque in which circumstances and conditions the model becomes privacy-vulnerable, leading to a challenge for ML models to maintain both performance and privacy. In this paper, we first explore the disparity between member and non-member data in the representation of models under common training frameworks. We identify how the representation magnitude disparity correlates with privacy vulnerability and address how this correlation impacts privacy vulnerability. Based on the observations, we propose Saturn Ring Classifier Module (SRCM), a plug-in model-level solution to mitigate membership privacy leakage. Through a confined yet effective representation space, our approach ameliorates models' privacy vulnerability while maintaining generalizability. The code of this work can be found here: \url{https://github.com/JEKimLab/AIES2024_SRCM}
Center-Based Relaxed Learning Against Membership Inference Attacks
Apr 26, 2024Membership inference attacks (MIAs) are currently considered one of the main privacy attack strategies, and their defense mechanisms have also been extensively explored. However, there is still a gap between the existing defense approaches and ideal models in performance and deployment costs. In particular, we observed that the privacy vulnerability of the model is closely correlated with the gap between the model's data-memorizing ability and generalization ability. To address this, we propose a new architecture-agnostic training paradigm called center-based relaxed learning (CRL), which is adaptive to any classification model and provides privacy preservation by sacrificing a minimal or no loss of model generalizability. We emphasize that CRL can better maintain the model's consistency between member and non-member data. Through extensive experiments on standard classification datasets, we empirically show that this approach exhibits comparable performance without requiring additional model capacity or data costs.
Cooperative Learning for Cost-Adaptive Inference
Dec 26, 2023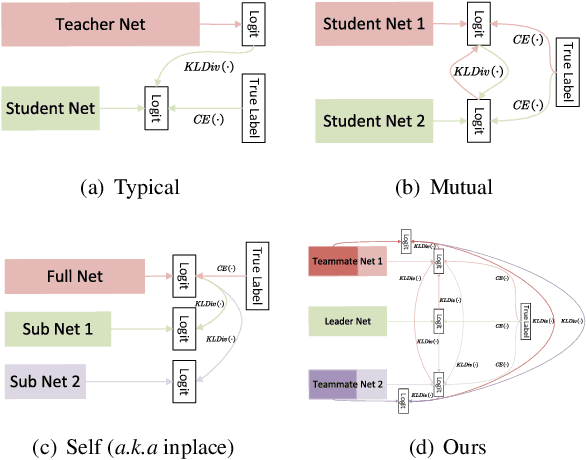
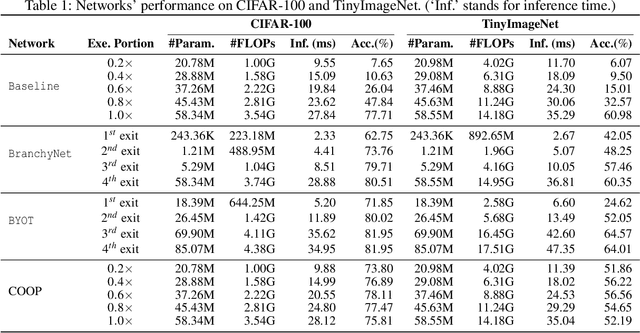
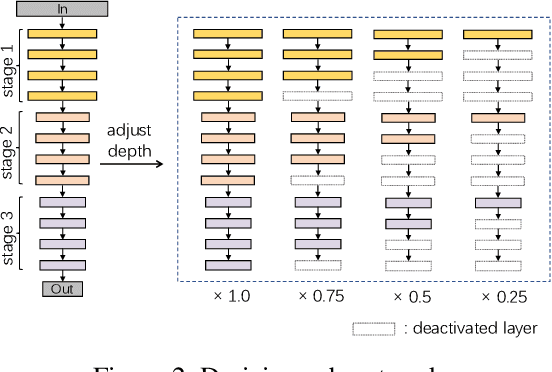
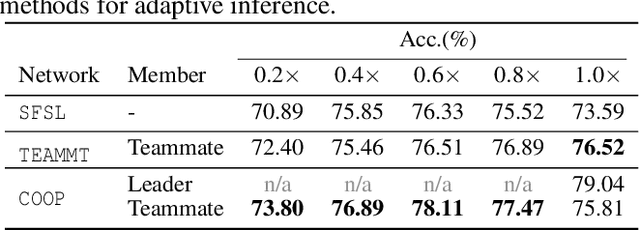
We propose a cooperative training framework for deep neural network architectures that enables the runtime network depths to change to satisfy dynamic computing resource requirements. In our framework, the number of layers participating in computation can be chosen dynamically to meet performance-cost trade-offs at inference runtime. Our method trains two Teammate nets and a Leader net, and two sets of Teammate sub-networks with various depths through knowledge distillation. The Teammate nets derive sub-networks and transfer knowledge to them, and to each other, while the Leader net guides Teammate nets to ensure accuracy. The approach trains the framework atomically at once instead of individually training various sizes of models; in a sense, the various-sized networks are all trained at once, in a "package deal." The proposed framework is not tied to any specific architecture but can incorporate any existing models/architectures, therefore it can maintain stable results and is insensitive to the size of a dataset's feature map. Compared with other related approaches, it provides comparable accuracy to its full network while various sizes of models are available.