 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan an Actor-Critic Optimization Framework Improve Analog Design Optimization?
Mar 25, 2026Analog design often slows down because even small changes to device sizes or biases require expensive simulation cycles, and high-quality solutions typically occupy only a narrow part of a very large search space. While existing optimizers reduce some of this burden, they largely operate without the kind of judgment designers use when deciding where to search next. This paper presents an actor-critic optimization framework (ACOF) for analog sizing that brings that form of guidance into the loop. Rather than treating optimization as a purely black-box search problem, ACOF separates the roles of proposal and evaluation: an actor suggests promising regions of the design space, while a critic reviews those choices, enforces design legality, and redirects the search when progress is hampered. This structure preserves compatibility with standard simulator-based flows while making the search process more deliberate, stable, and interpretable. Across our test circuits, ACOF improves the top-10 figure of merit by an average of 38.9% over the strongest competing baseline and reduces regret by an average of 24.7%, with peak gains of 70.5% in FoM and 42.2% lower regret on individual circuits. By combining iterative reasoning with simulation-driven search, the framework offers a more transparent path toward automated analog sizing across challenging design spaces.
GIFT: Generalizing Intent for Flexible Test-Time Rewards
Mar 23, 2026Robots learn reward functions from user demonstrations, but these rewards often fail to generalize to new environments. This failure occurs because learned rewards latch onto spurious correlations in training data rather than the underlying human intent that demonstrations represent. Existing methods leverage visual or semantic similarity to improve robustness, yet these surface-level cues often diverge from what humans actually care about. We present Generalizing Intent for Flexible Test-Time Rewards (GIFT), a framework that grounds reward generalization in human intent rather than surface cues. GIFT leverages language models to infer high-level intent from user demonstrations by contrasting preferred with non-preferred behaviors. At deployment, GIFT maps novel test states to behaviorally equivalent training states via intent-conditioned similarity, enabling learned rewards to generalize across distribution shifts without retraining. We evaluate GIFT on tabletop manipulation tasks with new objects and layouts. Across four simulated tasks with over 50 unseen objects, GIFT consistently outperforms visual and semantic similarity baselines in test-time pairwise win rate and state-alignment F1 score. Real-world experiments on a 7-DoF Franka Panda robot demonstrate that GIFT reliably transfers to physical settings. Further discussion can be found at https://mit-clear-lab.github.io/GIFT/
QuArch: A Question-Answering Dataset for AI Agents in Computer Architecture
Jan 06, 2025



We introduce QuArch, a dataset of 1500 human-validated question-answer pairs designed to evaluate and enhance language models' understanding of computer architecture. The dataset covers areas including processor design, memory systems, and performance optimization. Our analysis highlights a significant performance gap: the best closed-source model achieves 84% accuracy, while the top small open-source model reaches 72%. We observe notable struggles in memory systems, interconnection networks, and benchmarking. Fine-tuning with QuArch improves small model accuracy by up to 8%, establishing a foundation for advancing AI-driven computer architecture research. The dataset and leaderboard are at https://harvard-edge.github.io/QuArch/.
Can Low-Rank Knowledge Distillation in LLMs be Useful for Microelectronic Reasoning?
Jun 19, 2024In this work, we present empirical results regarding the feasibility of using offline large language models (LLMs) in the context of electronic design automation (EDA). The goal is to investigate and evaluate a contemporary language model's (Llama-2-7B) ability to function as a microelectronic Q & A expert as well as its reasoning, and generation capabilities in solving microelectronic-related problems. Llama-2-7B was tested across a variety of adaptation methods, including introducing a novel low-rank knowledge distillation (LoRA-KD) scheme. Our experiments produce both qualitative and quantitative results.
Large Reasoning Models for 3D Floorplanning in EDA: Learning from Imperfections
Jun 15, 2024

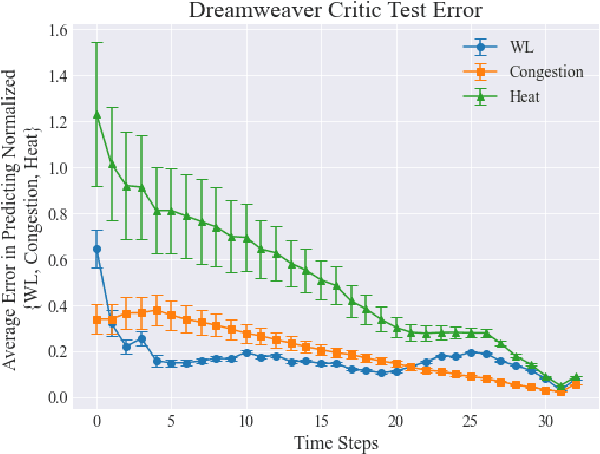
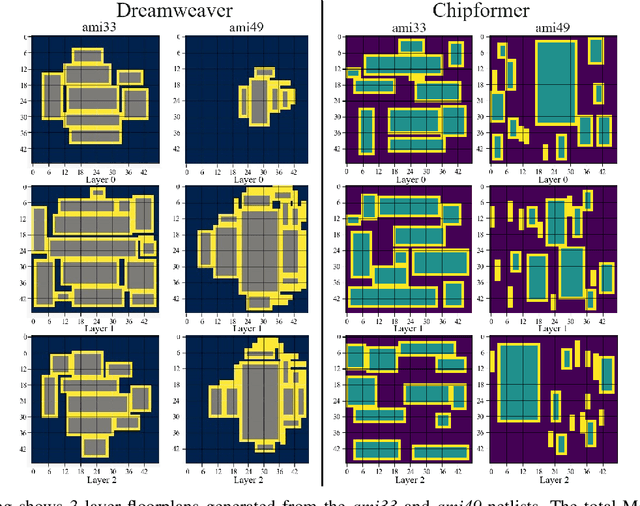
In this paper, we introduce Dreamweaver, which belongs to a new class of auto-regressive decision-making models known as large reasoning models (LRMs). Dreamweaver is designed to improve 3D floorplanning in electronic design automation (EDA) via an architecture that melds advancements in sequence-to-sequence reinforcement learning algorithms. A significant advantage of our approach is its ability to effectively reason over large discrete action spaces, which is essential for handling the numerous potential positions for various functional blocks in floorplanning. Additionally, Dreamweaver demonstrates strong performance even when trained on entirely random trajectories, showcasing its capacity to leverage sub-optimal or non-expert trajectories to enhance its results. This innovative approach contributes to streamlining the integrated circuit (IC) design flow and reducing the high computational costs typically associated with floorplanning. We evaluate its performance against a current state-of-the-art method, highlighting notable improvements.
The Over-Certainty Phenomenon in Modern UDA Algorithms
Apr 24, 2024



When neural networks are confronted with unfamiliar data that deviate from their training set, this signifies a domain shift. While these networks output predictions on their inputs, they typically fail to account for their level of familiarity with these novel observations. This challenge becomes even more pronounced in resource-constrained settings, such as embedded systems or edge devices. To address such challenges, we aim to recalibrate a neural network's decision boundaries in relation to its cognizance of the data it observes, introducing an approach we coin as certainty distillation. While prevailing works navigate unsupervised domain adaptation (UDA) with the goal of curtailing model entropy, they unintentionally birth models that grapple with calibration inaccuracies - a dilemma we term the over-certainty phenomenon. In this paper, we probe the drawbacks of this traditional learning model. As a solution to the issue, we propose a UDA algorithm that not only augments accuracy but also assures model calibration, all while maintaining suitability for environments with limited computational resources.