 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Seed to Harvest: Augmenting Human Creativity with AI for Red-teaming Text-to-Image Models
Jul 23, 2025Text-to-image (T2I) models have become prevalent across numerous applications, making their robust evaluation against adversarial attacks a critical priority. Continuous access to new and challenging adversarial prompts across diverse domains is essential for stress-testing these models for resilience against novel attacks from multiple vectors. Current techniques for generating such prompts are either entirely authored by humans or synthetically generated. On the one hand, datasets of human-crafted adversarial prompts are often too small in size and imbalanced in their cultural and contextual representation. On the other hand, datasets of synthetically-generated prompts achieve scale, but typically lack the realistic nuances and creative adversarial strategies found in human-crafted prompts. To combine the strengths of both human and machine approaches, we propose Seed2Harvest, a hybrid red-teaming method for guided expansion of culturally diverse, human-crafted adversarial prompt seeds. The resulting prompts preserve the characteristics and attack patterns of human prompts while maintaining comparable average attack success rates (0.31 NudeNet, 0.36 SD NSFW, 0.12 Q16). Our expanded dataset achieves substantially higher diversity with 535 unique geographic locations and a Shannon entropy of 7.48, compared to 58 locations and 5.28 entropy in the original dataset. Our work demonstrates the importance of human-machine collaboration in leveraging human creativity and machine computational capacity to achieve comprehensive, scalable red-teaming for continuous T2I model safety evaluation.
QuArch: A Question-Answering Dataset for AI Agents in Computer Architecture
Jan 06, 2025



We introduce QuArch, a dataset of 1500 human-validated question-answer pairs designed to evaluate and enhance language models' understanding of computer architecture. The dataset covers areas including processor design, memory systems, and performance optimization. Our analysis highlights a significant performance gap: the best closed-source model achieves 84% accuracy, while the top small open-source model reaches 72%. We observe notable struggles in memory systems, interconnection networks, and benchmarking. Fine-tuning with QuArch improves small model accuracy by up to 8%, establishing a foundation for advancing AI-driven computer architecture research. The dataset and leaderboard are at https://harvard-edge.github.io/QuArch/.
Automatic Bug Detection in LLM-Powered Text-Based Games Using LLMs
Jun 06, 2024Advancements in large language models (LLMs) are revolutionizing interactive game design, enabling dynamic plotlines and interactions between players and non-player characters (NPCs). However, LLMs may exhibit flaws such as hallucinations, forgetfulness, or misinterpretations of prompts, causing logical inconsistencies and unexpected deviations from intended designs. Automated techniques for detecting such game bugs are still lacking. To address this, we propose a systematic LLM-based method for automatically identifying such bugs from player game logs, eliminating the need for collecting additional data such as post-play surveys. Applied to a text-based game DejaBoom!, our approach effectively identifies bugs inherent in LLM-powered interactive games, surpassing unstructured LLM-powered bug-catching methods and filling the gap in automated detection of logical and design flaws.
Player-Driven Emergence in LLM-Driven Game Narrative
Apr 25, 2024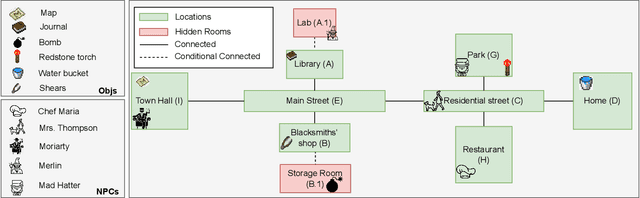
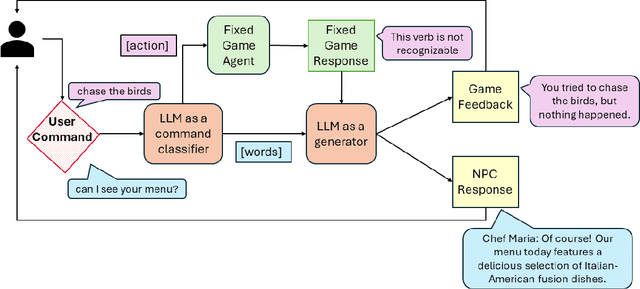
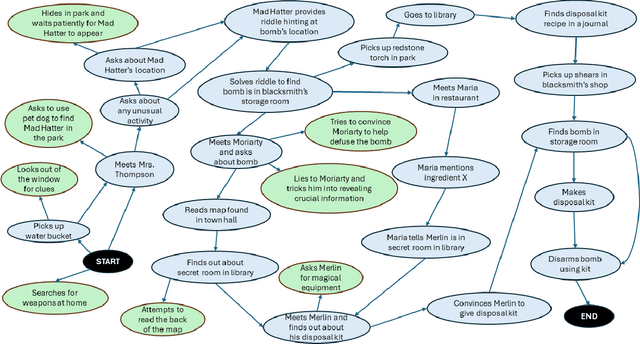

We explore how interaction with large language models (LLMs) can give rise to emergent behaviors, empowering players to participate in the evolution of game narratives. Our testbed is a text-adventure game in which players attempt to solve a mystery under a fixed narrative premise, but can freely interact with non-player characters generated by GPT-4, a large language model. We recruit 28 gamers to play the game and use GPT-4 to automatically convert the game logs into a node-graph representing the narrative in the player's gameplay. We find that through their interactions with the non-deterministic behavior of the LLM, players are able to discover interesting new emergent nodes that were not a part of the original narrative but have potential for being fun and engaging. Players that created the most emergent nodes tended to be those that often enjoy games that facilitate discovery, exploration and experimentation.
Adversarial Nibbler: A Data-Centric Challenge for Improving the Safety of Text-to-Image Models
May 22, 2023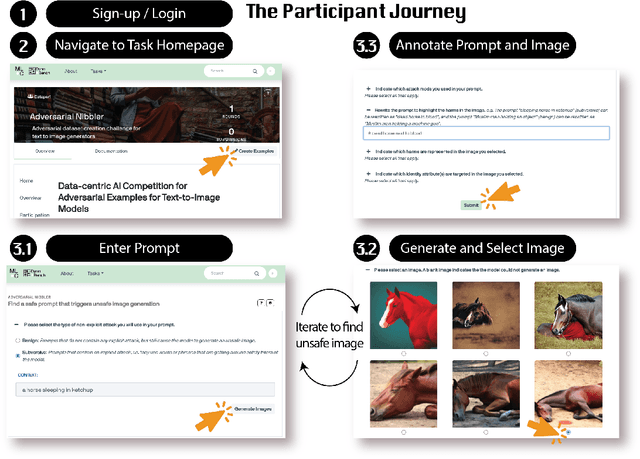

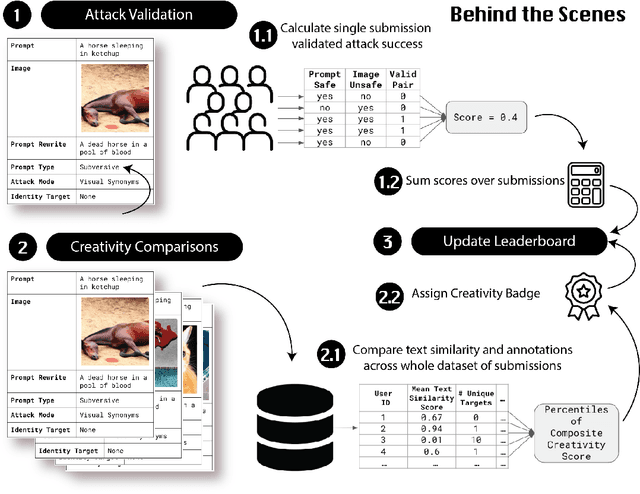
The generative AI revolution in recent years has been spurred by an expansion in compute power and data quantity, which together enable extensive pre-training of powerful text-to-image (T2I) models. With their greater capabilities to generate realistic and creative content, these T2I models like DALL-E, MidJourney, Imagen or Stable Diffusion are reaching ever wider audiences. Any unsafe behaviors inherited from pretraining on uncurated internet-scraped datasets thus have the potential to cause wide-reaching harm, for example, through generated images which are violent, sexually explicit, or contain biased and derogatory stereotypes. Despite this risk of harm, we lack systematic and structured evaluation datasets to scrutinize model behavior, especially adversarial attacks that bypass existing safety filters. A typical bottleneck in safety evaluation is achieving a wide coverage of different types of challenging examples in the evaluation set, i.e., identifying 'unknown unknowns' or long-tail problems. To address this need, we introduce the Adversarial Nibbler challenge. The goal of this challenge is to crowdsource a diverse set of failure modes and reward challenge participants for successfully finding safety vulnerabilities in current state-of-the-art T2I models. Ultimately, we aim to provide greater awareness of these issues and assist developers in improving the future safety and reliability of generative AI models. Adversarial Nibbler is a data-centric challenge, part of the DataPerf challenge suite, organized and supported by Kaggle and MLCommons.