 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA2Perf: Real-World Autonomous Agents Benchmark
Mar 04, 2025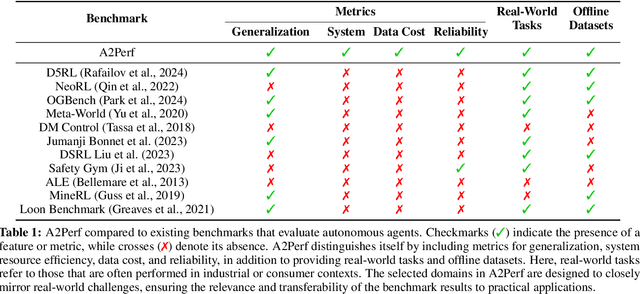

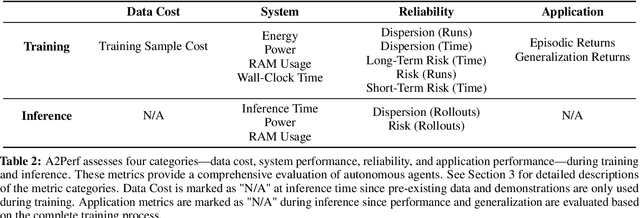

Autonomous agents and systems cover a number of application areas, from robotics and digital assistants to combinatorial optimization, all sharing common, unresolved research challenges. It is not sufficient for agents to merely solve a given task; they must generalize to out-of-distribution tasks, perform reliably, and use hardware resources efficiently during training and inference, among other requirements. Several methods, such as reinforcement learning and imitation learning, are commonly used to tackle these problems, each with different trade-offs. However, there is a lack of benchmarking suites that define the environments, datasets, and metrics which can be used to provide a meaningful way for the community to compare progress on applying these methods to real-world problems. We introduce A2Perf--a benchmark with three environments that closely resemble real-world domains: computer chip floorplanning, web navigation, and quadruped locomotion. A2Perf provides metrics that track task performance, generalization, system resource efficiency, and reliability, which are all critical to real-world applications. Using A2Perf, we demonstrate that web navigation agents can achieve latencies comparable to human reaction times on consumer hardware, reveal reliability trade-offs between algorithms for quadruped locomotion, and quantify the energy costs of different learning approaches for computer chip-design. In addition, we propose a data cost metric to account for the cost incurred acquiring offline data for imitation learning and hybrid algorithms, which allows us to better compare these approaches. A2Perf also contains several standard baselines, enabling apples-to-apples comparisons across methods and facilitating progress in real-world autonomy. As an open-source benchmark, A2Perf is designed to remain accessible, up-to-date, and useful to the research community over the long term.
QuArch: A Question-Answering Dataset for AI Agents in Computer Architecture
Jan 06, 2025



We introduce QuArch, a dataset of 1500 human-validated question-answer pairs designed to evaluate and enhance language models' understanding of computer architecture. The dataset covers areas including processor design, memory systems, and performance optimization. Our analysis highlights a significant performance gap: the best closed-source model achieves 84% accuracy, while the top small open-source model reaches 72%. We observe notable struggles in memory systems, interconnection networks, and benchmarking. Fine-tuning with QuArch improves small model accuracy by up to 8%, establishing a foundation for advancing AI-driven computer architecture research. The dataset and leaderboard are at https://harvard-edge.github.io/QuArch/.
ArchGym: An Open-Source Gymnasium for Machine Learning Assisted Architecture Design
Jun 15, 2023Machine learning is a prevalent approach to tame the complexity of design space exploration for domain-specific architectures. Using ML for design space exploration poses challenges. First, it's not straightforward to identify the suitable algorithm from an increasing pool of ML methods. Second, assessing the trade-offs between performance and sample efficiency across these methods is inconclusive. Finally, lack of a holistic framework for fair, reproducible, and objective comparison across these methods hinders progress of adopting ML-aided architecture design space exploration and impedes creating repeatable artifacts. To mitigate these challenges, we introduce ArchGym, an open-source gym and easy-to-extend framework that connects diverse search algorithms to architecture simulators. To demonstrate utility, we evaluate ArchGym across multiple vanilla and domain-specific search algorithms in designing custom memory controller, deep neural network accelerators, and custom SoC for AR/VR workloads, encompassing over 21K experiments. Results suggest that with unlimited samples, ML algorithms are equally favorable to meet user-defined target specification if hyperparameters are tuned; no solution is necessarily better than another (e.g., reinforcement learning vs. Bayesian methods). We coin the term hyperparameter lottery to describe the chance for a search algorithm to find an optimal design provided meticulously selected hyperparameters. The ease of data collection and aggregation in ArchGym facilitates research in ML-aided architecture design space exploration. As a case study, we show this advantage by developing a proxy cost model with an RMSE of 0.61% that offers a 2,000-fold reduction in simulation time. Code and data for ArchGym is available at https://bit.ly/ArchGym.
Jump-Start Reinforcement Learning
Apr 05, 2022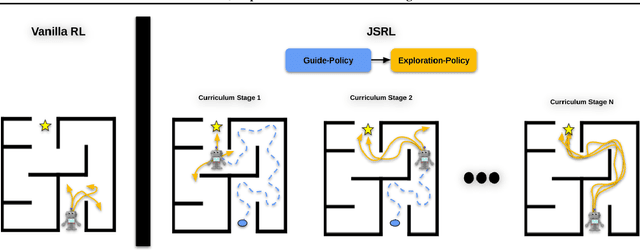
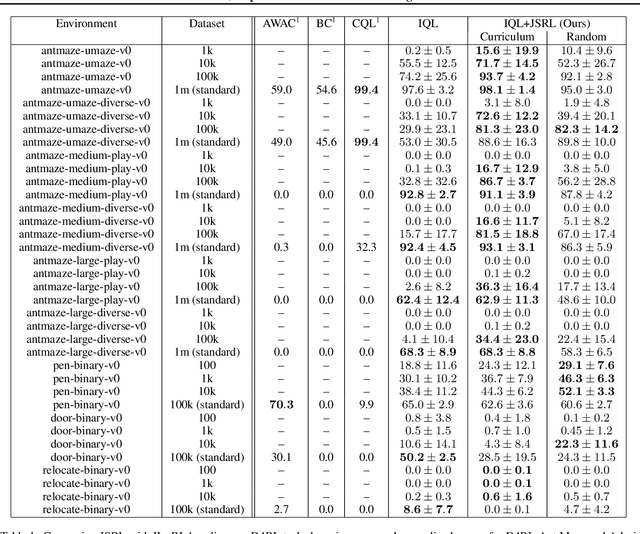
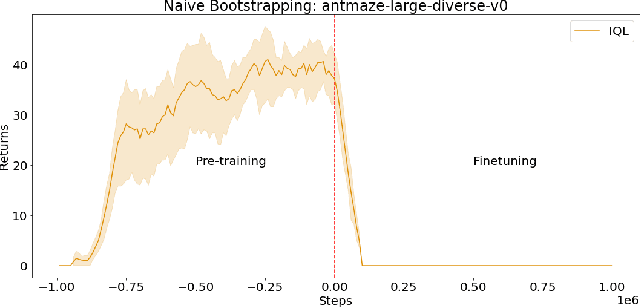
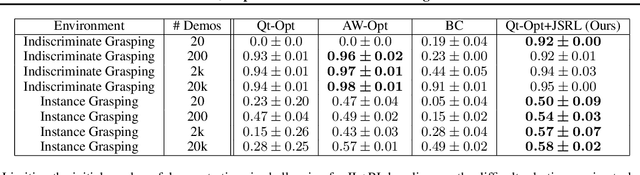
Reinforcement learning (RL) provides a theoretical framework for continuously improving an agent's behavior via trial and error. However, efficiently learning policies from scratch can be very difficult, particularly for tasks with exploration challenges. In such settings, it might be desirable to initialize RL with an existing policy, offline data, or demonstrations. However, naively performing such initialization in RL often works poorly, especially for value-based methods. In this paper, we present a meta algorithm that can use offline data, demonstrations, or a pre-existing policy to initialize an RL policy, and is compatible with any RL approach. In particular, we propose Jump-Start Reinforcement Learning (JSRL), an algorithm that employs two policies to solve tasks: a guide-policy, and an exploration-policy. By using the guide-policy to form a curriculum of starting states for the exploration-policy, we are able to efficiently improve performance on a set of simulated robotic tasks. We show via experiments that JSRL is able to significantly outperform existing imitation and reinforcement learning algorithms, particularly in the small-data regime. In addition, we provide an upper bound on the sample complexity of JSRL and show that with the help of a guide-policy, one can improve the sample complexity for non-optimism exploration methods from exponential in horizon to polynomial.
Improving Mild Cognitive Impairment Prediction via Reinforcement Learning and Dialogue Simulation
Feb 18, 2018
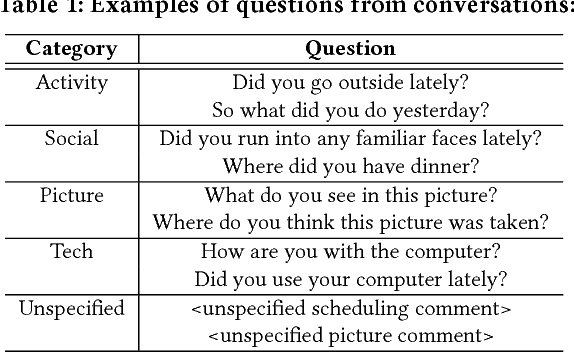
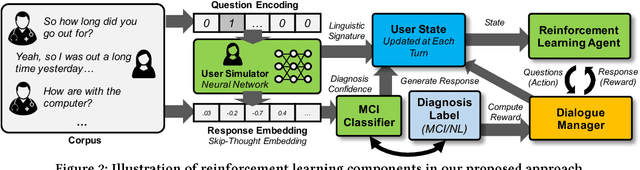
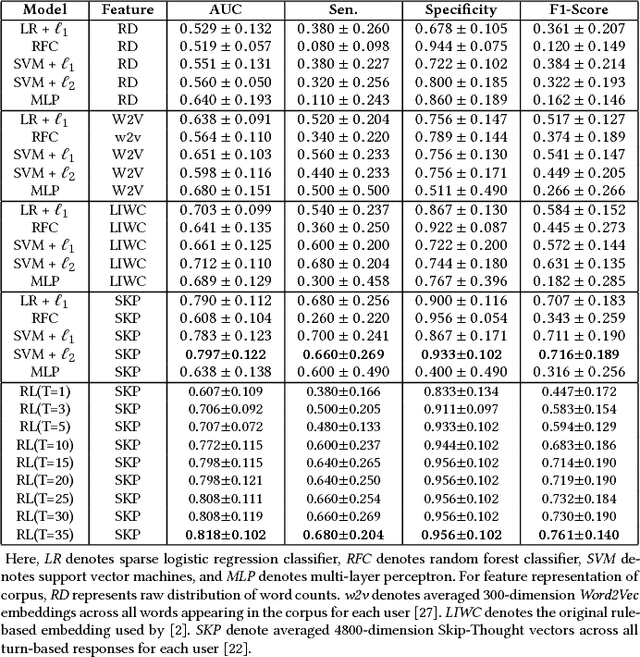
Mild cognitive impairment (MCI) is a prodromal phase in the progression from normal aging to dementia, especially Alzheimers disease. Even though there is mild cognitive decline in MCI patients, they have normal overall cognition and thus is challenging to distinguish from normal aging. Using transcribed data obtained from recorded conversational interactions between participants and trained interviewers, and applying supervised learning models to these data, a recent clinical trial has shown a promising result in differentiating MCI from normal aging. However, the substantial amount of interactions with medical staff can still incur significant medical care expenses in practice. In this paper, we propose a novel reinforcement learning (RL) framework to train an efficient dialogue agent on existing transcripts from clinical trials. Specifically, the agent is trained to sketch disease-specific lexical probability distribution, and thus to converse in a way that maximizes the diagnosis accuracy and minimizes the number of conversation turns. We evaluate the performance of the proposed reinforcement learning framework on the MCI diagnosis from a real clinical trial. The results show that while using only a few turns of conversation, our framework can significantly outperform state-of-the-art supervised learning approaches.