 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVADER: Visual Affordance Detection and Error Recovery for Multi Robot Human Collaboration
May 25, 2024



Robots today can exploit the rich world knowledge of large language models to chain simple behavioral skills into long-horizon tasks. However, robots often get interrupted during long-horizon tasks due to primitive skill failures and dynamic environments. We propose VADER, a plan, execute, detect framework with seeking help as a new skill that enables robots to recover and complete long-horizon tasks with the help of humans or other robots. VADER leverages visual question answering (VQA) modules to detect visual affordances and recognize execution errors. It then generates prompts for a language model planner (LMP) which decides when to seek help from another robot or human to recover from errors in long-horizon task execution. We show the effectiveness of VADER with two long-horizon robotic tasks. Our pilot study showed that VADER is capable of performing complex long-horizon tasks by asking for help from another robot to clear a table. Our user study showed that VADER is capable of performing complex long-horizon tasks by asking for help from a human to clear a path. We gathered feedback from people (N=19) about the performance of the VADER performance vs. a robot that did not ask for help. https://google-vader.github.io/
Learning to Learn Faster from Human Feedback with Language Model Predictive Control
Feb 18, 2024



Large language models (LLMs) have been shown to exhibit a wide range of capabilities, such as writing robot code from language commands -- enabling non-experts to direct robot behaviors, modify them based on feedback, or compose them to perform new tasks. However, these capabilities (driven by in-context learning) are limited to short-term interactions, where users' feedback remains relevant for only as long as it fits within the context size of the LLM, and can be forgotten over longer interactions. In this work, we investigate fine-tuning the robot code-writing LLMs, to remember their in-context interactions and improve their teachability i.e., how efficiently they adapt to human inputs (measured by average number of corrections before the user considers the task successful). Our key observation is that when human-robot interactions are formulated as a partially observable Markov decision process (in which human language inputs are observations, and robot code outputs are actions), then training an LLM to complete previous interactions can be viewed as training a transition dynamics model -- that can be combined with classic robotics techniques such as model predictive control (MPC) to discover shorter paths to success. This gives rise to Language Model Predictive Control (LMPC), a framework that fine-tunes PaLM 2 to improve its teachability on 78 tasks across 5 robot embodiments -- improving non-expert teaching success rates of unseen tasks by 26.9% while reducing the average number of human corrections from 2.4 to 1.9. Experiments show that LMPC also produces strong meta-learners, improving the success rate of in-context learning new tasks on unseen robot embodiments and APIs by 31.5%. See videos, code, and demos at: https://robot-teaching.github.io/.
Deep RL at Scale: Sorting Waste in Office Buildings with a Fleet of Mobile Manipulators
May 05, 2023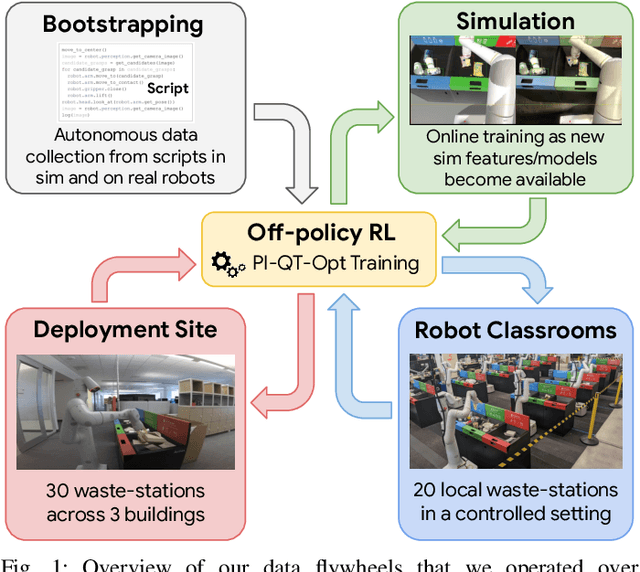


We describe a system for deep reinforcement learning of robotic manipulation skills applied to a large-scale real-world task: sorting recyclables and trash in office buildings. Real-world deployment of deep RL policies requires not only effective training algorithms, but the ability to bootstrap real-world training and enable broad generalization. To this end, our system combines scalable deep RL from real-world data with bootstrapping from training in simulation, and incorporates auxiliary inputs from existing computer vision systems as a way to boost generalization to novel objects, while retaining the benefits of end-to-end training. We analyze the tradeoffs of different design decisions in our system, and present a large-scale empirical validation that includes training on real-world data gathered over the course of 24 months of experimentation, across a fleet of 23 robots in three office buildings, with a total training set of 9527 hours of robotic experience. Our final validation also consists of 4800 evaluation trials across 240 waste station configurations, in order to evaluate in detail the impact of the design decisions in our system, the scaling effects of including more real-world data, and the performance of the method on novel objects. The projects website and videos can be found at \href{http://rl-at-scale.github.io}{rl-at-scale.github.io}.
Jump-Start Reinforcement Learning
Apr 05, 2022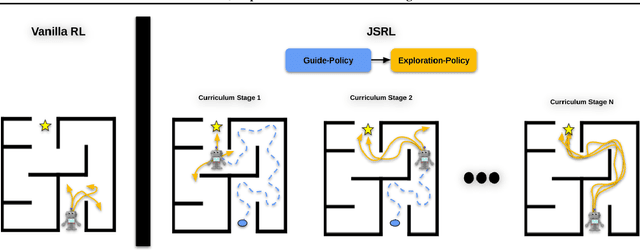
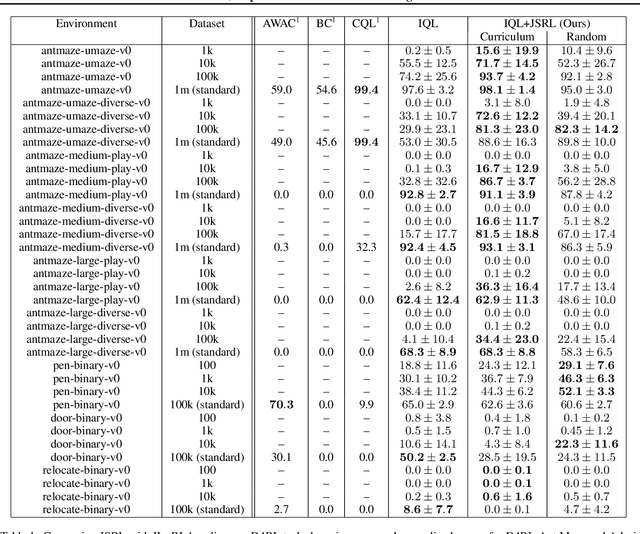
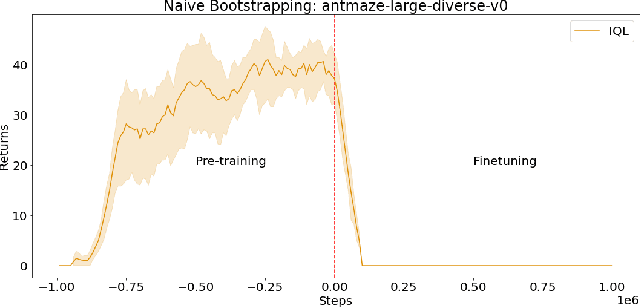
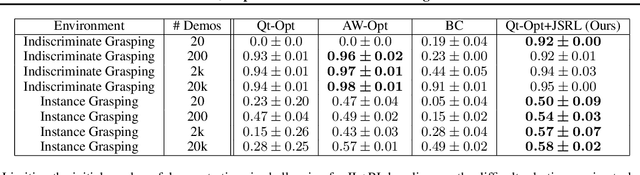
Reinforcement learning (RL) provides a theoretical framework for continuously improving an agent's behavior via trial and error. However, efficiently learning policies from scratch can be very difficult, particularly for tasks with exploration challenges. In such settings, it might be desirable to initialize RL with an existing policy, offline data, or demonstrations. However, naively performing such initialization in RL often works poorly, especially for value-based methods. In this paper, we present a meta algorithm that can use offline data, demonstrations, or a pre-existing policy to initialize an RL policy, and is compatible with any RL approach. In particular, we propose Jump-Start Reinforcement Learning (JSRL), an algorithm that employs two policies to solve tasks: a guide-policy, and an exploration-policy. By using the guide-policy to form a curriculum of starting states for the exploration-policy, we are able to efficiently improve performance on a set of simulated robotic tasks. We show via experiments that JSRL is able to significantly outperform existing imitation and reinforcement learning algorithms, particularly in the small-data regime. In addition, we provide an upper bound on the sample complexity of JSRL and show that with the help of a guide-policy, one can improve the sample complexity for non-optimism exploration methods from exponential in horizon to polynomial.
Practical Imitation Learning in the Real World via Task Consistency Loss
Feb 03, 2022

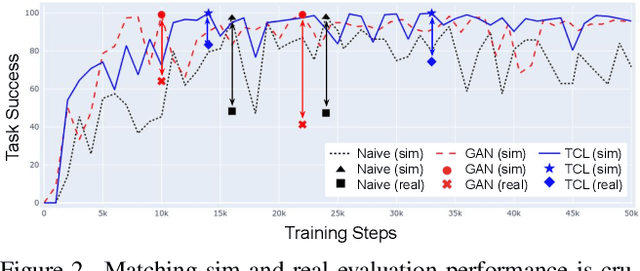
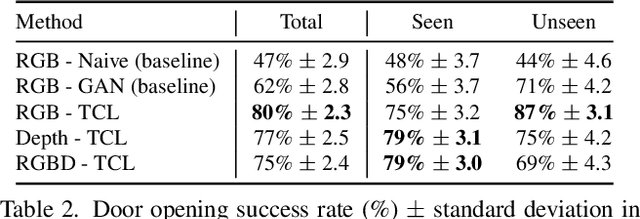
Recent work in visual end-to-end learning for robotics has shown the promise of imitation learning across a variety of tasks. Such approaches are expensive both because they require large amounts of real world training demonstrations and because identifying the best model to deploy in the real world requires time-consuming real-world evaluations. These challenges can be mitigated by simulation: by supplementing real world data with simulated demonstrations and using simulated evaluations to identify high performing policies. However, this introduces the well-known "reality gap" problem, where simulator inaccuracies decorrelate performance in simulation from that of reality. In this paper, we build on top of prior work in GAN-based domain adaptation and introduce the notion of a Task Consistency Loss (TCL), a self-supervised loss that encourages sim and real alignment both at the feature and action-prediction levels. We demonstrate the effectiveness of our approach by teaching a mobile manipulator to autonomously approach a door, turn the handle to open the door, and enter the room. The policy performs control from RGB and depth images and generalizes to doors not encountered in training data. We achieve 80% success across ten seen and unseen scenes using only ~16.2 hours of teleoperated demonstrations in sim and real. To the best of our knowledge, this is the first work to tackle latched door opening from a purely end-to-end learning approach, where the task of navigation and manipulation are jointly modeled by a single neural network.