 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Game Decision Transformers
May 30, 2022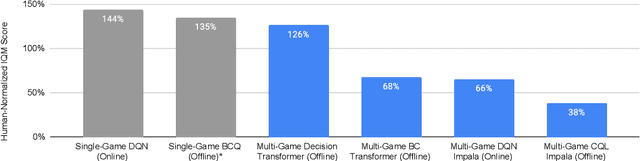

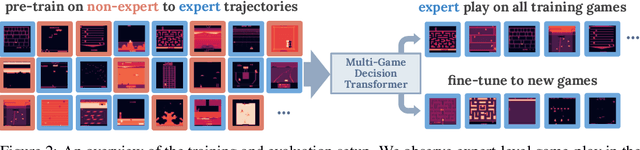
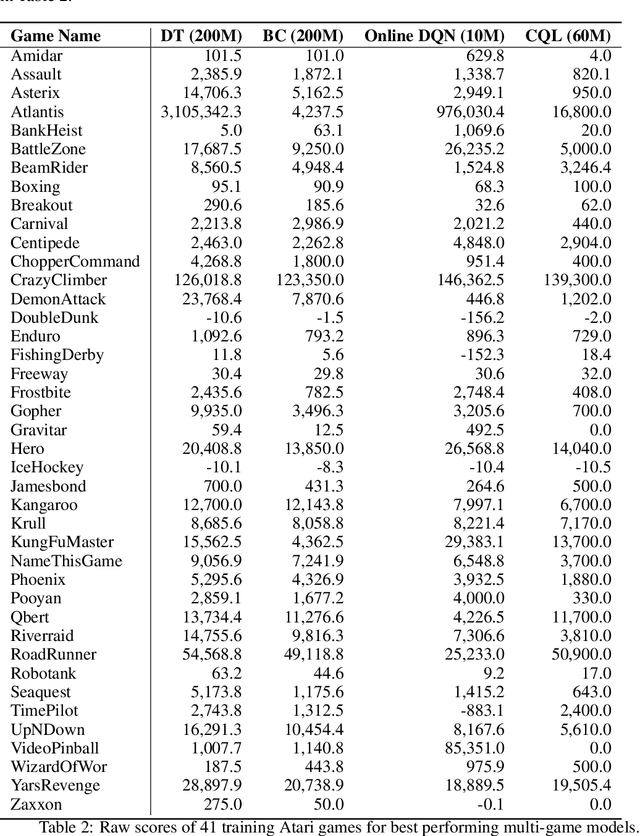
A longstanding goal of the field of AI is a strategy for compiling diverse experience into a highly capable, generalist agent. In the subfields of vision and language, this was largely achieved by scaling up transformer-based models and training them on large, diverse datasets. Motivated by this progress, we investigate whether the same strategy can be used to produce generalist reinforcement learning agents. Specifically, we show that a single transformer-based model - with a single set of weights - trained purely offline can play a suite of up to 46 Atari games simultaneously at close-to-human performance. When trained and evaluated appropriately, we find that the same trends observed in language and vision hold, including scaling of performance with model size and rapid adaptation to new games via fine-tuning. We compare several approaches in this multi-game setting, such as online and offline RL methods and behavioral cloning, and find that our Multi-Game Decision Transformer models offer the best scalability and performance. We release the pre-trained models and code to encourage further research in this direction. Additional information, videos and code can be seen at: sites.google.com/view/multi-game-transformers
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Apr 04, 2022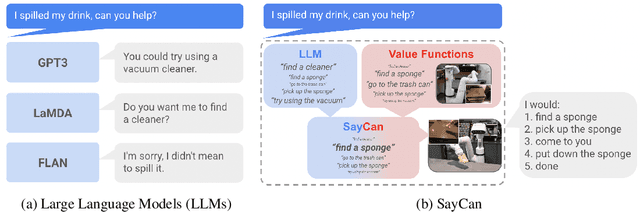
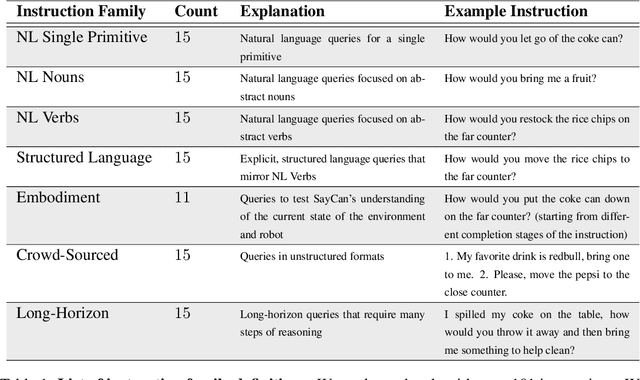
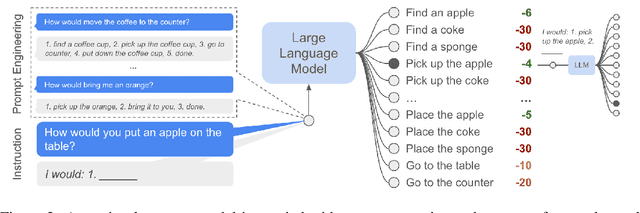
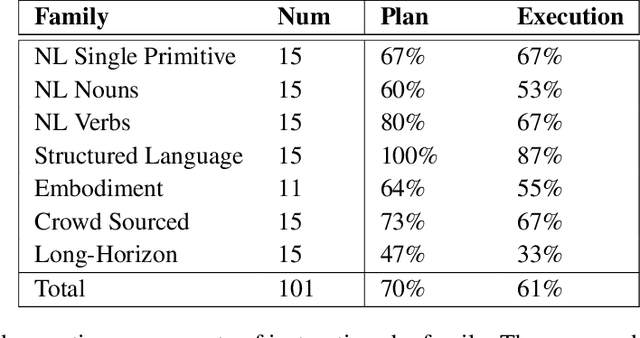
Large language models can encode a wealth of semantic knowledge about the world. Such knowledge could be extremely useful to robots aiming to act upon high-level, temporally extended instructions expressed in natural language. However, a significant weakness of language models is that they lack real-world experience, which makes it difficult to leverage them for decision making within a given embodiment. For example, asking a language model to describe how to clean a spill might result in a reasonable narrative, but it may not be applicable to a particular agent, such as a robot, that needs to perform this task in a particular environment. We propose to provide real-world grounding by means of pretrained skills, which are used to constrain the model to propose natural language actions that are both feasible and contextually appropriate. The robot can act as the language model's "hands and eyes," while the language model supplies high-level semantic knowledge about the task. We show how low-level skills can be combined with large language models so that the language model provides high-level knowledge about the procedures for performing complex and temporally-extended instructions, while value functions associated with these skills provide the grounding necessary to connect this knowledge to a particular physical environment. We evaluate our method on a number of real-world robotic tasks, where we show the need for real-world grounding and that this approach is capable of completing long-horizon, abstract, natural language instructions on a mobile manipulator. The project's website and the video can be found at https://say-can.github.io/
Bayesian Imitation Learning for End-to-End Mobile Manipulation
Feb 15, 2022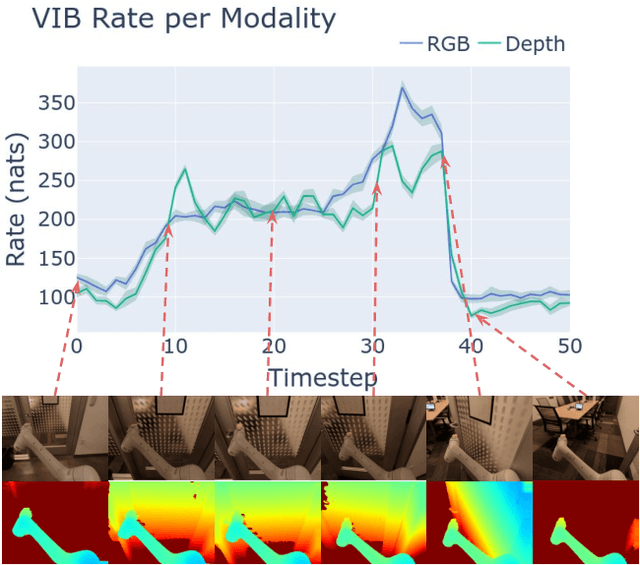
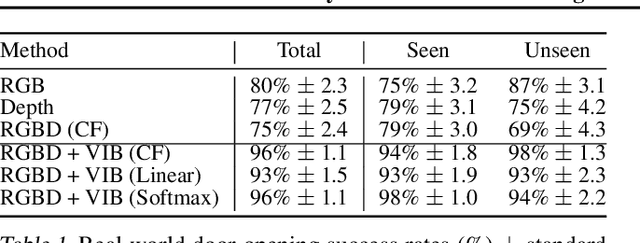
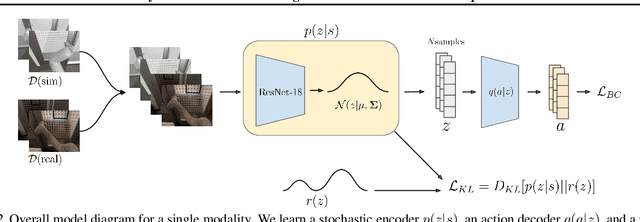
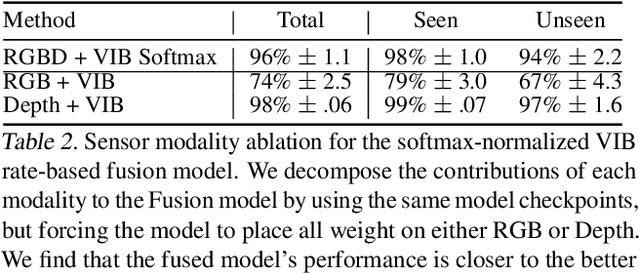
In this work we investigate and demonstrate benefits of a Bayesian approach to imitation learning from multiple sensor inputs, as applied to the task of opening office doors with a mobile manipulator. Augmenting policies with additional sensor inputs, such as RGB + depth cameras, is a straightforward approach to improving robot perception capabilities, especially for tasks that may favor different sensors in different situations. As we scale multi-sensor robotic learning to unstructured real-world settings (e.g. offices, homes) and more complex robot behaviors, we also increase reliance on simulators for cost, efficiency, and safety. Consequently, the sim-to-real gap across multiple sensor modalities also increases, making simulated validation more difficult. We show that using the Variational Information Bottleneck (Alemi et al., 2016) to regularize convolutional neural networks improves generalization to held-out domains and reduces the sim-to-real gap in a sensor-agnostic manner. As a side effect, the learned embeddings also provide useful estimates of model uncertainty for each sensor. We demonstrate that our method is able to help close the sim-to-real gap and successfully fuse RGB and depth modalities based on understanding of the situational uncertainty of each sensor. In a real-world office environment, we achieve 96% task success, improving upon the baseline by +16%.
BC-Z: Zero-Shot Task Generalization with Robotic Imitation Learning
Feb 04, 2022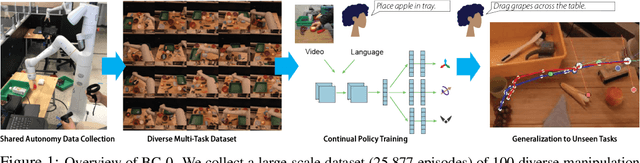
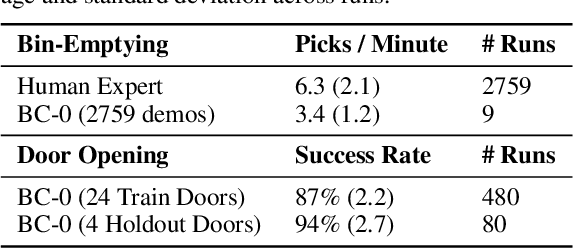

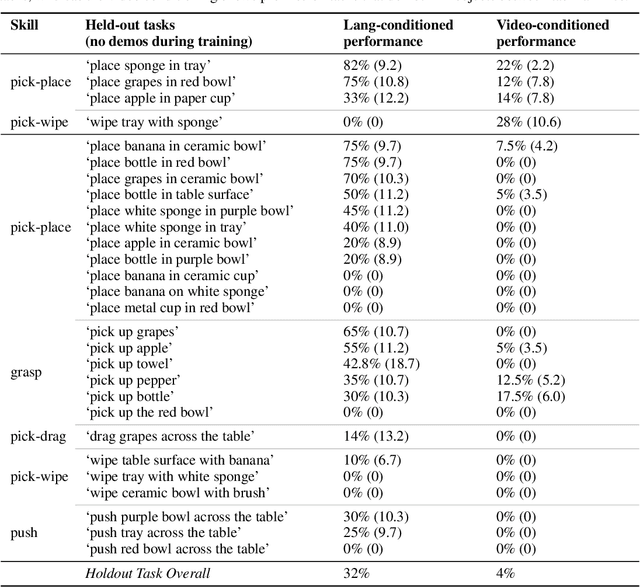
In this paper, we study the problem of enabling a vision-based robotic manipulation system to generalize to novel tasks, a long-standing challenge in robot learning. We approach the challenge from an imitation learning perspective, aiming to study how scaling and broadening the data collected can facilitate such generalization. To that end, we develop an interactive and flexible imitation learning system that can learn from both demonstrations and interventions and can be conditioned on different forms of information that convey the task, including pre-trained embeddings of natural language or videos of humans performing the task. When scaling data collection on a real robot to more than 100 distinct tasks, we find that this system can perform 24 unseen manipulation tasks with an average success rate of 44%, without any robot demonstrations for those tasks.
* CoRL 2021, 23 pages
Practical Imitation Learning in the Real World via Task Consistency Loss
Feb 03, 2022

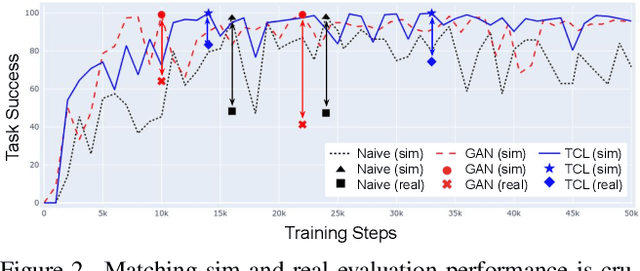
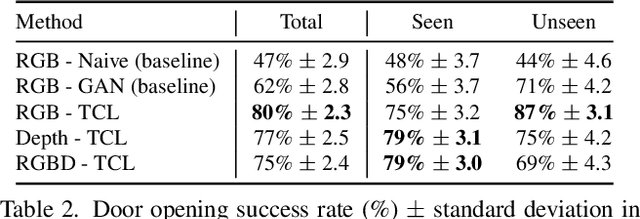
Recent work in visual end-to-end learning for robotics has shown the promise of imitation learning across a variety of tasks. Such approaches are expensive both because they require large amounts of real world training demonstrations and because identifying the best model to deploy in the real world requires time-consuming real-world evaluations. These challenges can be mitigated by simulation: by supplementing real world data with simulated demonstrations and using simulated evaluations to identify high performing policies. However, this introduces the well-known "reality gap" problem, where simulator inaccuracies decorrelate performance in simulation from that of reality. In this paper, we build on top of prior work in GAN-based domain adaptation and introduce the notion of a Task Consistency Loss (TCL), a self-supervised loss that encourages sim and real alignment both at the feature and action-prediction levels. We demonstrate the effectiveness of our approach by teaching a mobile manipulator to autonomously approach a door, turn the handle to open the door, and enter the room. The policy performs control from RGB and depth images and generalizes to doors not encountered in training data. We achieve 80% success across ten seen and unseen scenes using only ~16.2 hours of teleoperated demonstrations in sim and real. To the best of our knowledge, this is the first work to tackle latched door opening from a purely end-to-end learning approach, where the task of navigation and manipulation are jointly modeled by a single neural network.
AW-Opt: Learning Robotic Skills with Imitation and Reinforcement at Scale
Nov 11, 2021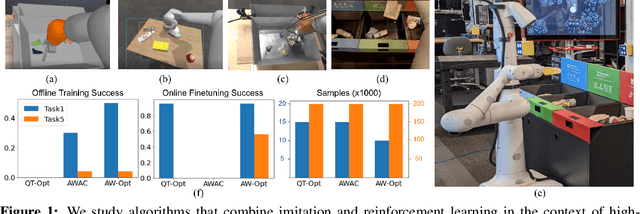
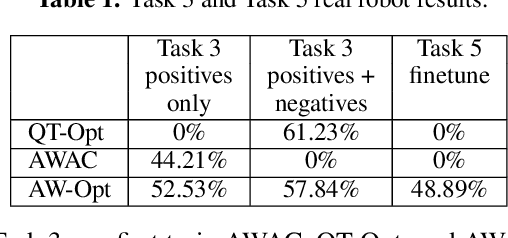
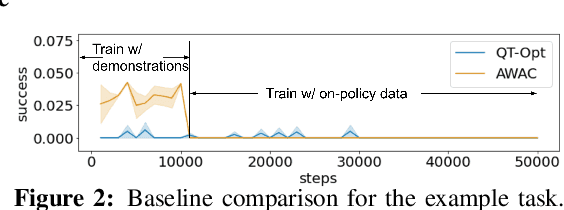
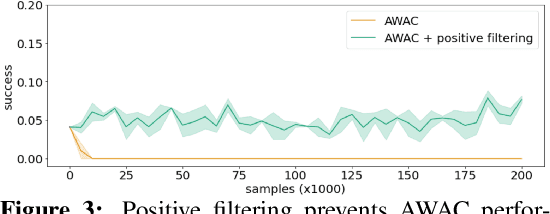
Robotic skills can be learned via imitation learning (IL) using user-provided demonstrations, or via reinforcement learning (RL) using large amountsof autonomously collected experience.Both methods have complementarystrengths and weaknesses: RL can reach a high level of performance, but requiresexploration, which can be very time consuming and unsafe; IL does not requireexploration, but only learns skills that are as good as the provided demonstrations.Can a single method combine the strengths of both approaches? A number ofprior methods have aimed to address this question, proposing a variety of tech-niques that integrate elements of IL and RL. However, scaling up such methodsto complex robotic skills that integrate diverse offline data and generalize mean-ingfully to real-world scenarios still presents a major challenge. In this paper, ouraim is to test the scalability of prior IL + RL algorithms and devise a system basedon detailed empirical experimentation that combines existing components in themost effective and scalable way. To that end, we present a series of experimentsaimed at understanding the implications of each design decision, so as to develop acombined approach that can utilize demonstrations and heterogeneous prior datato attain the best performance on a range of real-world and realistic simulatedrobotic problems. Our complete method, which we call AW-Opt, combines ele-ments of advantage-weighted regression [1, 2] and QT-Opt [3], providing a unifiedapproach for integrating demonstrations and offline data for robotic manipulation.Please see https://awopt.github.io for more details.
RetinaGAN: An Object-aware Approach to Sim-to-Real Transfer
Nov 06, 2020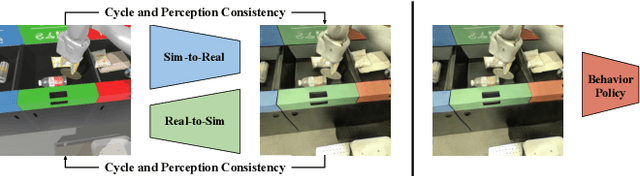

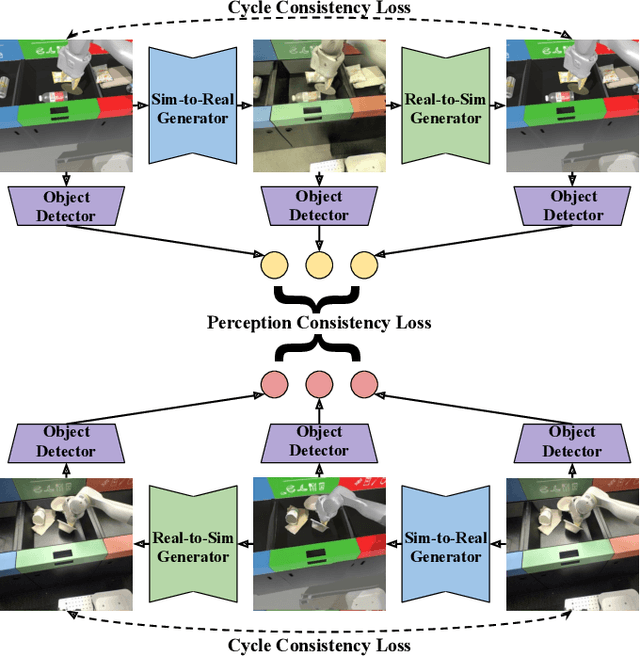
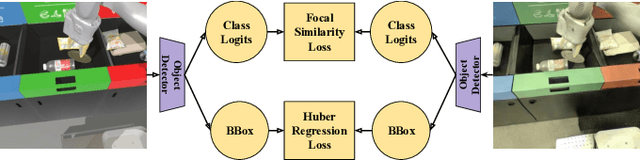
The success of deep reinforcement learning (RL) and imitation learning (IL) in vision-based robotic manipulation typically hinges on the expense of large scale data collection. With simulation, data to train a policy can be collected efficiently at scale, but the visual gap between sim and real makes deployment in the real world difficult. We introduce RetinaGAN, a generative adversarial network (GAN) approach to adapt simulated images to realistic ones with object-detection consistency. RetinaGAN is trained in an unsupervised manner without task loss dependencies, and preserves general object structure and texture in adapted images. We evaluate our method on three real world tasks: grasping, pushing, and door opening. RetinaGAN improves upon the performance of prior sim-to-real methods for RL-based object instance grasping and continues to be effective even in the limited data regime. When applied to a pushing task in a similar visual domain, RetinaGAN demonstrates transfer with no additional real data requirements. We also show our method bridges the visual gap for a novel door opening task using imitation learning in a new visual domain. Visit the project website at https://retinagan.github.io/
Meta-Learning Requires Meta-Augmentation
Jul 10, 2020

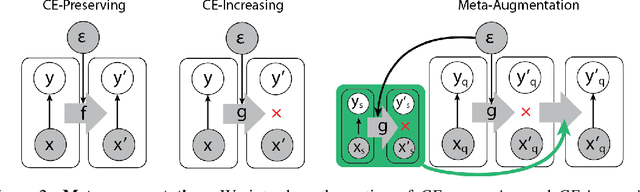

Meta-learning algorithms aim to learn two components: a model that predicts targets for a task, and a base learner that quickly updates that model when given examples from a new task. This additional level of learning can be powerful, but it also creates another potential source for overfitting, since we can now overfit in either the model or the base learner. We describe both of these forms of metalearning overfitting, and demonstrate that they appear experimentally in common meta-learning benchmarks. We then use an information-theoretic framework to discuss meta-augmentation, a way to add randomness that discourages the base learner and model from learning trivial solutions that do not generalize to new tasks. We demonstrate that meta-augmentation produces large complementary benefits to recently proposed meta-regularization techniques.
Thinking While Moving: Deep Reinforcement Learning with Concurrent Control
Apr 25, 2020



We study reinforcement learning in settings where sampling an action from the policy must be done concurrently with the time evolution of the controlled system, such as when a robot must decide on the next action while still performing the previous action. Much like a person or an animal, the robot must think and move at the same time, deciding on its next action before the previous one has completed. In order to develop an algorithmic framework for such concurrent control problems, we start with a continuous-time formulation of the Bellman equations, and then discretize them in a way that is aware of system delays. We instantiate this new class of approximate dynamic programming methods via a simple architectural extension to existing value-based deep reinforcement learning algorithms. We evaluate our methods on simulated benchmark tasks and a large-scale robotic grasping task where the robot must "think while moving".
Scalable Multi-Task Imitation Learning with Autonomous Improvement
Feb 25, 2020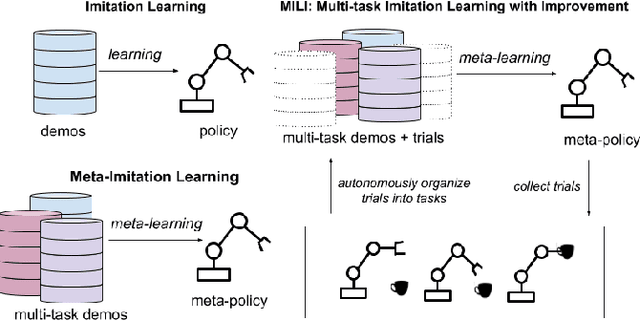

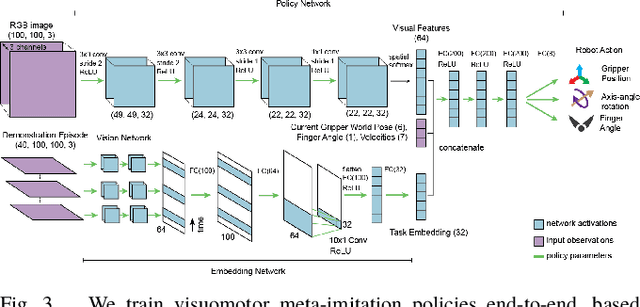

While robot learning has demonstrated promising results for enabling robots to automatically acquire new skills, a critical challenge in deploying learning-based systems is scale: acquiring enough data for the robot to effectively generalize broadly. Imitation learning, in particular, has remained a stable and powerful approach for robot learning, but critically relies on expert operators for data collection. In this work, we target this challenge, aiming to build an imitation learning system that can continuously improve through autonomous data collection, while simultaneously avoiding the explicit use of reinforcement learning, to maintain the stability, simplicity, and scalability of supervised imitation. To accomplish this, we cast the problem of imitation with autonomous improvement into a multi-task setting. We utilize the insight that, in a multi-task setting, a failed attempt at one task might represent a successful attempt at another task. This allows us to leverage the robot's own trials as demonstrations for tasks other than the one that the robot actually attempted. Using an initial dataset of multi-task demonstration data, the robot autonomously collects trials which are only sparsely labeled with a binary indication of whether the trial accomplished any useful task or not. We then embed the trials into a learned latent space of tasks, trained using only the initial demonstration dataset, to draw similarities between various trials, enabling the robot to achieve one-shot generalization to new tasks. In contrast to prior imitation learning approaches, our method can autonomously collect data with sparse supervision for continuous improvement, and in contrast to reinforcement learning algorithms, our method can effectively improve from sparse, task-agnostic reward signals.