 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Multi-Task Imitation Learning with Autonomous Improvement
Paper and Code
Feb 25, 2020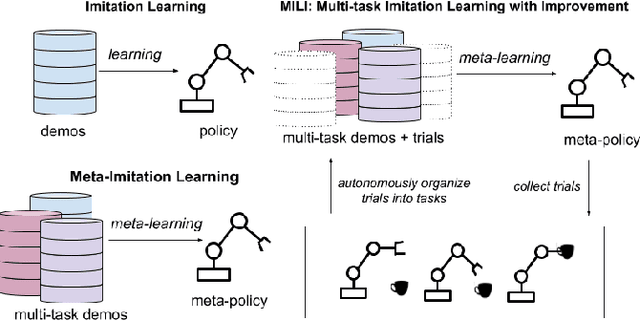

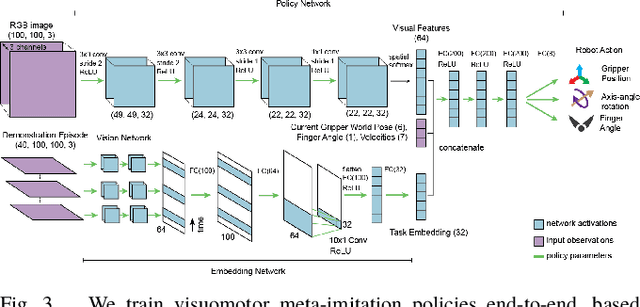

While robot learning has demonstrated promising results for enabling robots to automatically acquire new skills, a critical challenge in deploying learning-based systems is scale: acquiring enough data for the robot to effectively generalize broadly. Imitation learning, in particular, has remained a stable and powerful approach for robot learning, but critically relies on expert operators for data collection. In this work, we target this challenge, aiming to build an imitation learning system that can continuously improve through autonomous data collection, while simultaneously avoiding the explicit use of reinforcement learning, to maintain the stability, simplicity, and scalability of supervised imitation. To accomplish this, we cast the problem of imitation with autonomous improvement into a multi-task setting. We utilize the insight that, in a multi-task setting, a failed attempt at one task might represent a successful attempt at another task. This allows us to leverage the robot's own trials as demonstrations for tasks other than the one that the robot actually attempted. Using an initial dataset of multi-task demonstration data, the robot autonomously collects trials which are only sparsely labeled with a binary indication of whether the trial accomplished any useful task or not. We then embed the trials into a learned latent space of tasks, trained using only the initial demonstration dataset, to draw similarities between various trials, enabling the robot to achieve one-shot generalization to new tasks. In contrast to prior imitation learning approaches, our method can autonomously collect data with sparse supervision for continuous improvement, and in contrast to reinforcement learning algorithms, our method can effectively improve from sparse, task-agnostic reward signals.