 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Designing a Learning Robot: Improving Morphology for Enhanced Task Performance and Learning
Mar 23, 2023As robots become more prevalent, optimizing their design for better performance and efficiency is becoming increasingly important. However, current robot design practices overlook the impact of perception and design choices on a robot's learning capabilities. To address this gap, we propose a comprehensive methodology that accounts for the interplay between the robot's perception, hardware characteristics, and task requirements. Our approach optimizes the robot's morphology holistically, leading to improved learning and task execution proficiency. To achieve this, we introduce a Morphology-AGnostIc Controller (MAGIC), which helps with the rapid assessment of different robot designs. The MAGIC policy is efficiently trained through a novel PRIvileged Single-stage learning via latent alignMent (PRISM) framework, which also encourages behaviors that are typical of robot onboard observation. Our simulation-based results demonstrate that morphologies optimized holistically improve the robot performance by 15-20% on various manipulation tasks, and require 25x less data to match human-expert made morphology performance. In summary, our work contributes to the growing trend of learning-based approaches in robotics and emphasizes the potential in designing robots that facilitate better learning.
Asking for Help: Failure Prediction in Behavioral Cloning through Value Approximation
Feb 08, 2023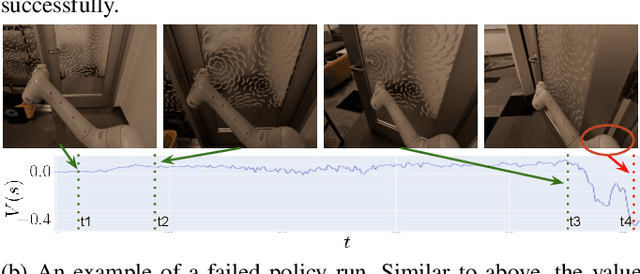
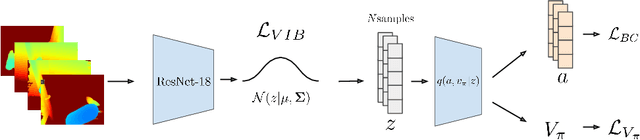
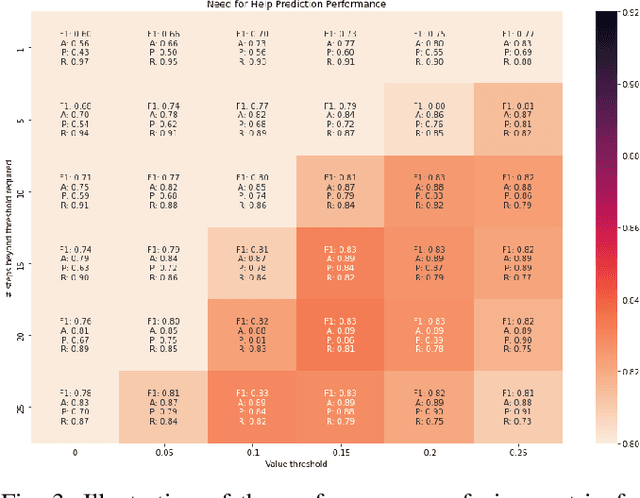
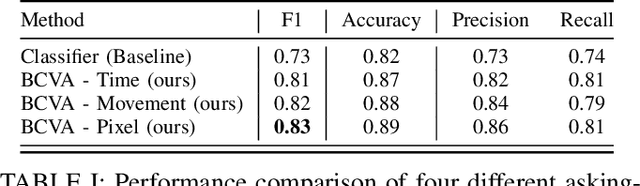
Recent progress in end-to-end Imitation Learning approaches has shown promising results and generalization capabilities on mobile manipulation tasks. Such models are seeing increasing deployment in real-world settings, where scaling up requires robots to be able to operate with high autonomy, i.e. requiring as little human supervision as possible. In order to avoid the need for one-on-one human supervision, robots need to be able to detect and prevent policy failures ahead of time, and ask for help, allowing a remote operator to supervise multiple robots and help when needed. However, the black-box nature of end-to-end Imitation Learning models such as Behavioral Cloning, as well as the lack of an explicit state-value representation, make it difficult to predict failures. To this end, we introduce Behavioral Cloning Value Approximation (BCVA), an approach to learning a state value function based on and trained jointly with a Behavioral Cloning policy that can be used to predict failures. We demonstrate the effectiveness of BCVA by applying it to the challenging mobile manipulation task of latched-door opening, showing that we can identify failure scenarios with with 86% precision and 81% recall, evaluated on over 2000 real world runs, improving upon the baseline of simple failure classification by 10 percentage-points.
Leveraging Haptic Feedback to Improve Data Quality and Quantity for Deep Imitation Learning Models
Nov 06, 2022
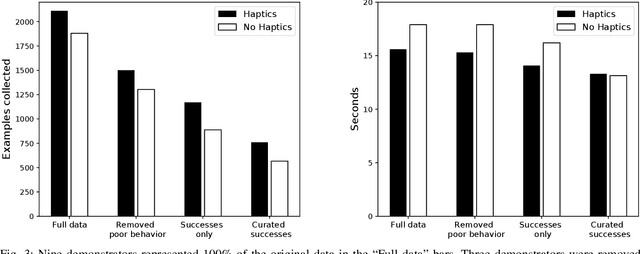

Learning from demonstration (LfD) is a proven technique to teach robots new skills. Data quality and quantity play a critical role in LfD trained model performance. In this paper we analyze the effect of enhancing an existing teleoperation data collection system with real-time haptic feedback; we observe improvements in the collected data throughput and its quality for model training. Our experiment testbed was a mobile manipulator robot that opened doors with latch handles. Evaluation of teleoperated data collection on eight real world conference room doors found that adding the haptic feedback improved the data throughput by 6%. We additionally used the collected data to train six image-based deep imitation learning models, three with haptic feedback and three without it. These models were used to implement autonomous door-opening with the same type of robot used during data collection. Our results show that a policy from a behavior cloning model trained with haptic data performed on average 11% better than its counterpart with no haptic feedback data, indicating that haptic feedback resulted in collection of a higher quality dataset.
Bayesian Imitation Learning for End-to-End Mobile Manipulation
Feb 15, 2022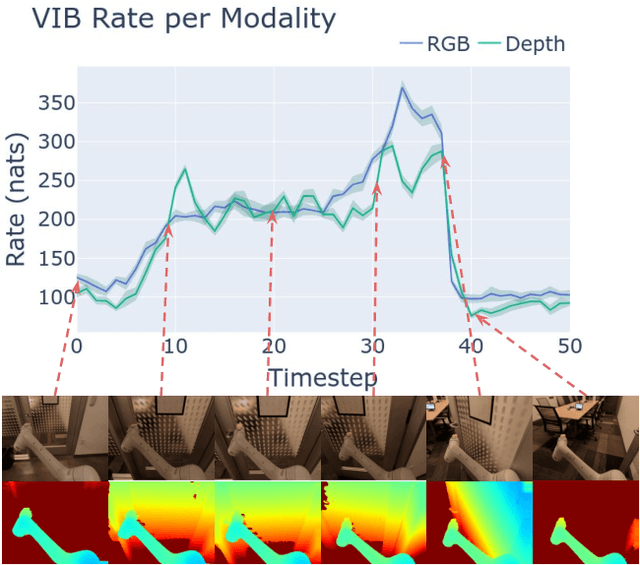
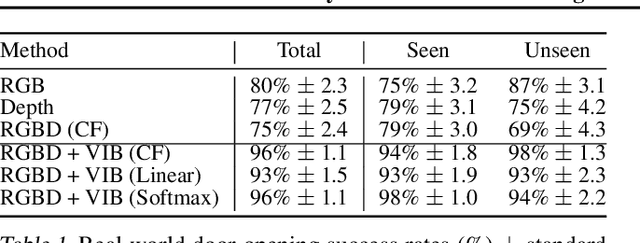
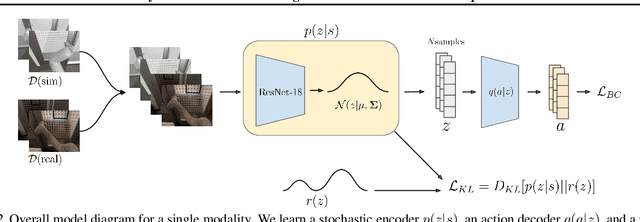
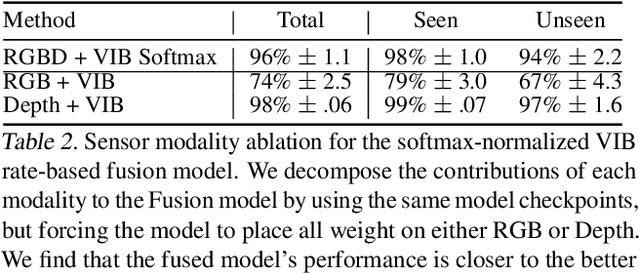
In this work we investigate and demonstrate benefits of a Bayesian approach to imitation learning from multiple sensor inputs, as applied to the task of opening office doors with a mobile manipulator. Augmenting policies with additional sensor inputs, such as RGB + depth cameras, is a straightforward approach to improving robot perception capabilities, especially for tasks that may favor different sensors in different situations. As we scale multi-sensor robotic learning to unstructured real-world settings (e.g. offices, homes) and more complex robot behaviors, we also increase reliance on simulators for cost, efficiency, and safety. Consequently, the sim-to-real gap across multiple sensor modalities also increases, making simulated validation more difficult. We show that using the Variational Information Bottleneck (Alemi et al., 2016) to regularize convolutional neural networks improves generalization to held-out domains and reduces the sim-to-real gap in a sensor-agnostic manner. As a side effect, the learned embeddings also provide useful estimates of model uncertainty for each sensor. We demonstrate that our method is able to help close the sim-to-real gap and successfully fuse RGB and depth modalities based on understanding of the situational uncertainty of each sensor. In a real-world office environment, we achieve 96% task success, improving upon the baseline by +16%.
BC-Z: Zero-Shot Task Generalization with Robotic Imitation Learning
Feb 04, 2022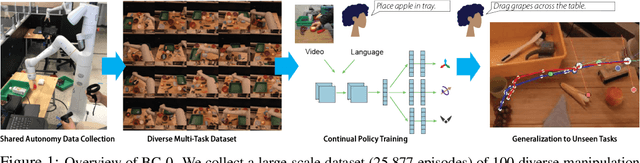

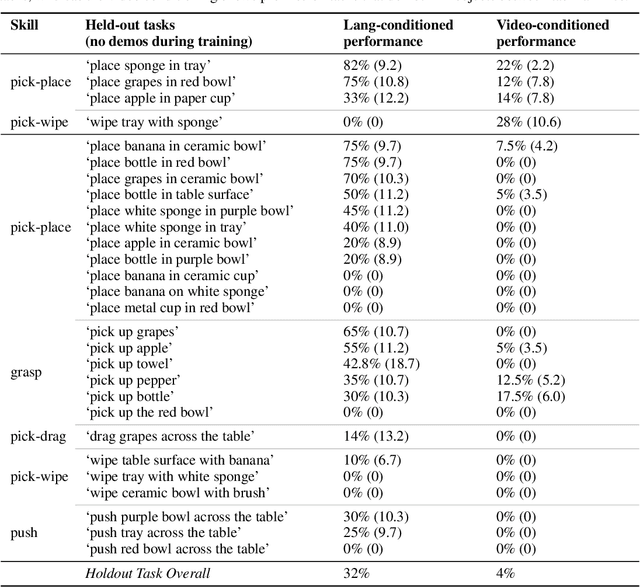
In this paper, we study the problem of enabling a vision-based robotic manipulation system to generalize to novel tasks, a long-standing challenge in robot learning. We approach the challenge from an imitation learning perspective, aiming to study how scaling and broadening the data collected can facilitate such generalization. To that end, we develop an interactive and flexible imitation learning system that can learn from both demonstrations and interventions and can be conditioned on different forms of information that convey the task, including pre-trained embeddings of natural language or videos of humans performing the task. When scaling data collection on a real robot to more than 100 distinct tasks, we find that this system can perform 24 unseen manipulation tasks with an average success rate of 44%, without any robot demonstrations for those tasks.
* CoRL 2021, 23 pages
Practical Imitation Learning in the Real World via Task Consistency Loss
Feb 03, 2022

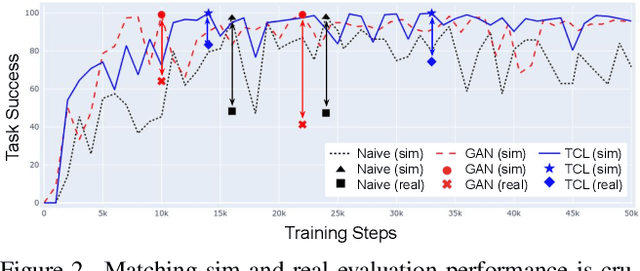
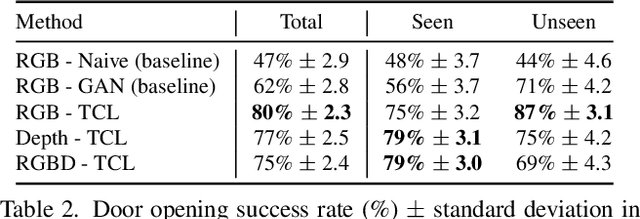
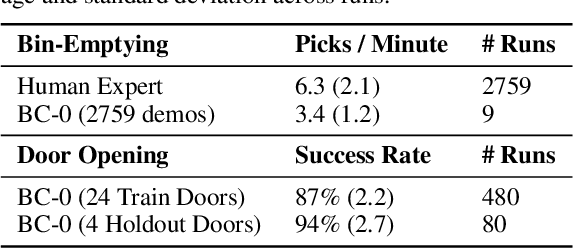
Recent work in visual end-to-end learning for robotics has shown the promise of imitation learning across a variety of tasks. Such approaches are expensive both because they require large amounts of real world training demonstrations and because identifying the best model to deploy in the real world requires time-consuming real-world evaluations. These challenges can be mitigated by simulation: by supplementing real world data with simulated demonstrations and using simulated evaluations to identify high performing policies. However, this introduces the well-known "reality gap" problem, where simulator inaccuracies decorrelate performance in simulation from that of reality. In this paper, we build on top of prior work in GAN-based domain adaptation and introduce the notion of a Task Consistency Loss (TCL), a self-supervised loss that encourages sim and real alignment both at the feature and action-prediction levels. We demonstrate the effectiveness of our approach by teaching a mobile manipulator to autonomously approach a door, turn the handle to open the door, and enter the room. The policy performs control from RGB and depth images and generalizes to doors not encountered in training data. We achieve 80% success across ten seen and unseen scenes using only ~16.2 hours of teleoperated demonstrations in sim and real. To the best of our knowledge, this is the first work to tackle latched door opening from a purely end-to-end learning approach, where the task of navigation and manipulation are jointly modeled by a single neural network.
AW-Opt: Learning Robotic Skills with Imitation and Reinforcement at Scale
Nov 11, 2021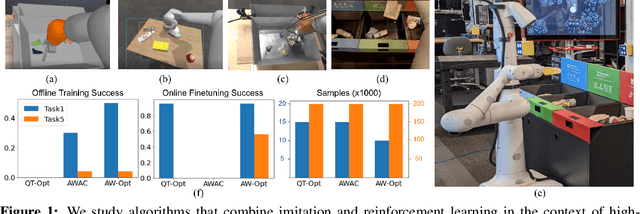
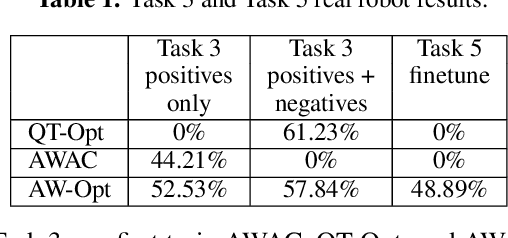
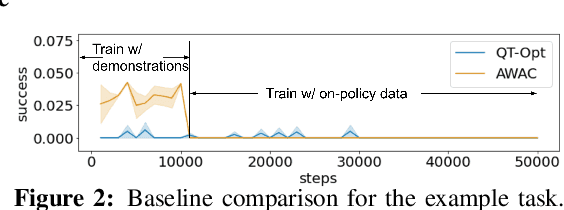
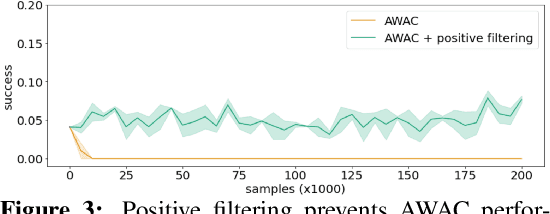
Robotic skills can be learned via imitation learning (IL) using user-provided demonstrations, or via reinforcement learning (RL) using large amountsof autonomously collected experience.Both methods have complementarystrengths and weaknesses: RL can reach a high level of performance, but requiresexploration, which can be very time consuming and unsafe; IL does not requireexploration, but only learns skills that are as good as the provided demonstrations.Can a single method combine the strengths of both approaches? A number ofprior methods have aimed to address this question, proposing a variety of tech-niques that integrate elements of IL and RL. However, scaling up such methodsto complex robotic skills that integrate diverse offline data and generalize mean-ingfully to real-world scenarios still presents a major challenge. In this paper, ouraim is to test the scalability of prior IL + RL algorithms and devise a system basedon detailed empirical experimentation that combines existing components in themost effective and scalable way. To that end, we present a series of experimentsaimed at understanding the implications of each design decision, so as to develop acombined approach that can utilize demonstrations and heterogeneous prior datato attain the best performance on a range of real-world and realistic simulatedrobotic problems. Our complete method, which we call AW-Opt, combines ele-ments of advantage-weighted regression [1, 2] and QT-Opt [3], providing a unifiedapproach for integrating demonstrations and offline data for robotic manipulation.Please see https://awopt.github.io for more details.
RetinaGAN: An Object-aware Approach to Sim-to-Real Transfer
Nov 06, 2020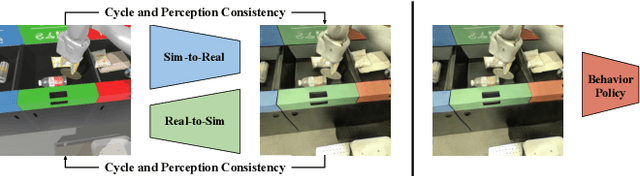

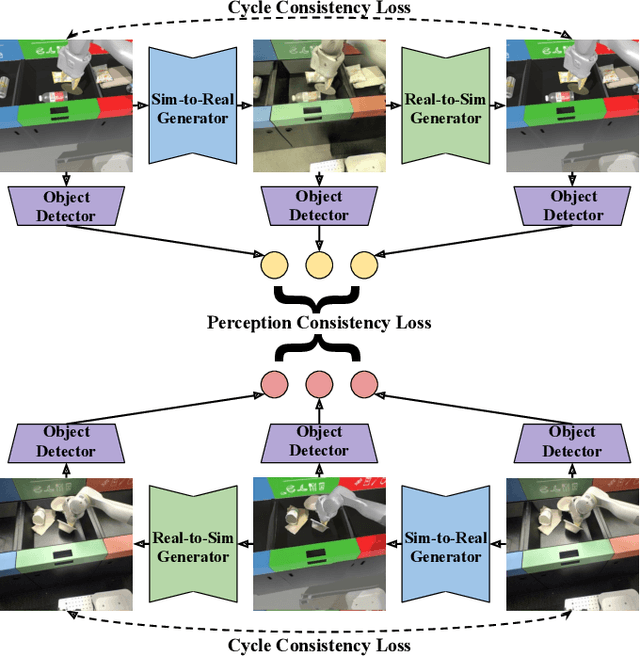
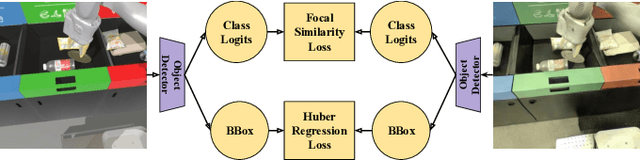
The success of deep reinforcement learning (RL) and imitation learning (IL) in vision-based robotic manipulation typically hinges on the expense of large scale data collection. With simulation, data to train a policy can be collected efficiently at scale, but the visual gap between sim and real makes deployment in the real world difficult. We introduce RetinaGAN, a generative adversarial network (GAN) approach to adapt simulated images to realistic ones with object-detection consistency. RetinaGAN is trained in an unsupervised manner without task loss dependencies, and preserves general object structure and texture in adapted images. We evaluate our method on three real world tasks: grasping, pushing, and door opening. RetinaGAN improves upon the performance of prior sim-to-real methods for RL-based object instance grasping and continues to be effective even in the limited data regime. When applied to a pushing task in a similar visual domain, RetinaGAN demonstrates transfer with no additional real data requirements. We also show our method bridges the visual gap for a novel door opening task using imitation learning in a new visual domain. Visit the project website at https://retinagan.github.io/
RL-CycleGAN: Reinforcement Learning Aware Simulation-To-Real
Jun 16, 2020
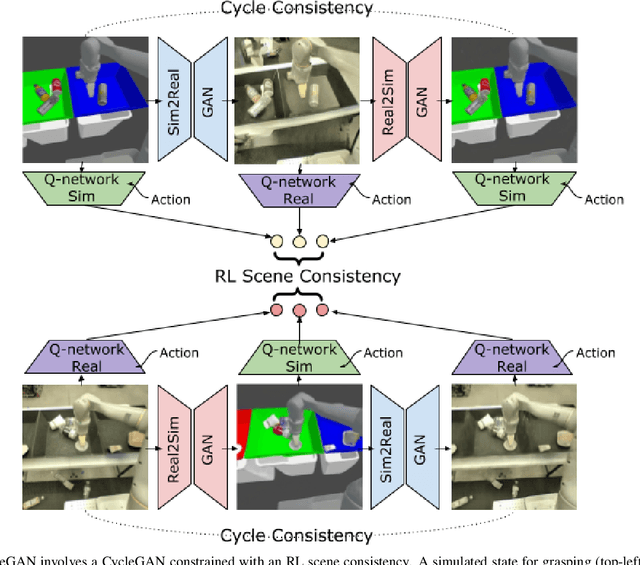


Deep neural network based reinforcement learning (RL) can learn appropriate visual representations for complex tasks like vision-based robotic grasping without the need for manually engineering or prior learning a perception system. However, data for RL is collected via running an agent in the desired environment, and for applications like robotics, running a robot in the real world may be extremely costly and time consuming. Simulated training offers an appealing alternative, but ensuring that policies trained in simulation can transfer effectively into the real world requires additional machinery. Simulations may not match reality, and typically bridging the simulation-to-reality gap requires domain knowledge and task-specific engineering. We can automate this process by employing generative models to translate simulated images into realistic ones. However, this sort of translation is typically task-agnostic, in that the translated images may not preserve all features that are relevant to the task. In this paper, we introduce the RL-scene consistency loss for image translation, which ensures that the translation operation is invariant with respect to the Q-values associated with the image. This allows us to learn a task-aware translation. Incorporating this loss into unsupervised domain translation, we obtain RL-CycleGAN, a new approach for simulation-to-real-world transfer for reinforcement learning. In evaluations of RL-CycleGAN on two vision-based robotics grasping tasks, we show that RL-CycleGAN offers a substantial improvement over a number of prior methods for sim-to-real transfer, attaining excellent real-world performance with only a modest number of real-world observations.
Modeling Long-horizon Tasks as Sequential Interaction Landscapes
Jun 08, 2020

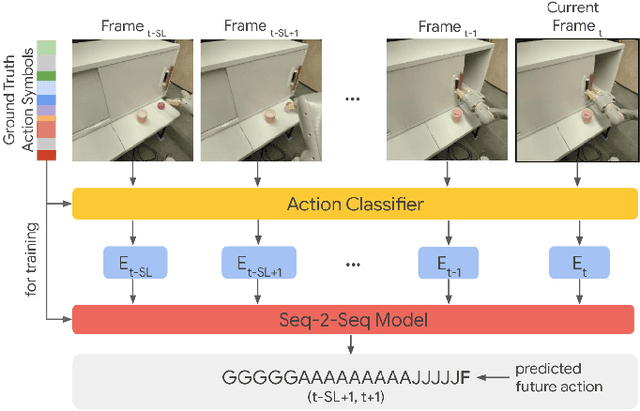
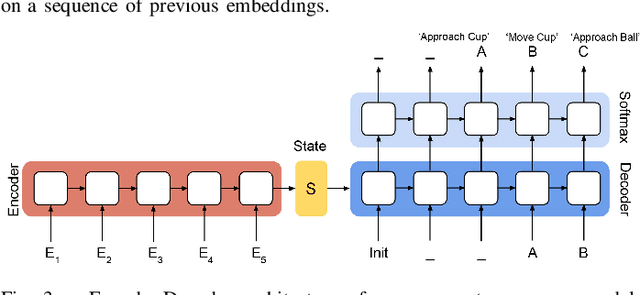
Complex object manipulation tasks often span over long sequences of operations. Task planning over long-time horizons is a challenging and open problem in robotics, and its complexity grows exponentially with an increasing number of subtasks. In this paper we present a deep learning network that learns dependencies and transitions across subtasks solely from a set of demonstration videos. We represent each subtask as an action symbol (e.g. move cup), and show that these symbols can be learned and predicted directly from image observations. Learning from demonstrations and visual observations are two main pillars of our approach. The former makes the learning tractable as it provides the network with information about the most frequent transitions and relevant dependency between subtasks (instead of exploring all possible combination), while the latter allows the network to continuously monitor the task progress and thus to interactively adapt to changes in the environment. We evaluate our framework on two long horizon tasks: (1) block stacking of puzzle pieces being executed by humans, and (2) a robot manipulation task involving pick and place of objects and sliding a cabinet door on a 7-DoF robot arm. We show that complex plans can be carried out when executing the robotic task and the robot can interactively adapt to changes in the environment and recover from failure cases.