 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Exponents Across Parameterizations and Optimizers
Jul 08, 2024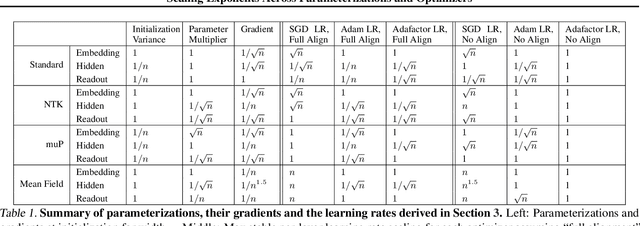



Robust and effective scaling of models from small to large width typically requires the precise adjustment of many algorithmic and architectural details, such as parameterization and optimizer choices. In this work, we propose a new perspective on parameterization by investigating a key assumption in prior work about the alignment between parameters and data and derive new theoretical results under weaker assumptions and a broader set of optimizers. Our extensive empirical investigation includes tens of thousands of models trained with all combinations of three optimizers, four parameterizations, several alignment assumptions, more than a dozen learning rates, and fourteen model sizes up to 26.8B parameters. We find that the best learning rate scaling prescription would often have been excluded by the assumptions in prior work. Our results show that all parameterizations, not just maximal update parameterization (muP), can achieve hyperparameter transfer; moreover, our novel per-layer learning rate prescription for standard parameterization outperforms muP. Finally, we demonstrate that an overlooked aspect of parameterization, the epsilon parameter in Adam, must be scaled correctly to avoid gradient underflow and propose Adam-atan2, a new numerically stable, scale-invariant version of Adam that eliminates the epsilon hyperparameter entirely.
Speed Limits for Deep Learning
Jul 27, 2023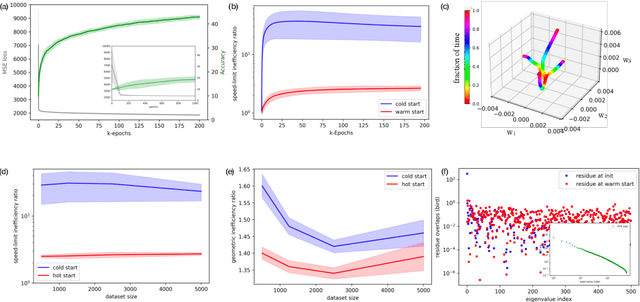
State-of-the-art neural networks require extreme computational power to train. It is therefore natural to wonder whether they are optimally trained. Here we apply a recent advancement in stochastic thermodynamics which allows bounding the speed at which one can go from the initial weight distribution to the final distribution of the fully trained network, based on the ratio of their Wasserstein-2 distance and the entropy production rate of the dynamical process connecting them. Considering both gradient-flow and Langevin training dynamics, we provide analytical expressions for these speed limits for linear and linearizable neural networks e.g. Neural Tangent Kernel (NTK). Remarkably, given some plausible scaling assumptions on the NTK spectra and spectral decomposition of the labels -- learning is optimal in a scaling sense. Our results are consistent with small-scale experiments with Convolutional Neural Networks (CNNs) and Fully Connected Neural networks (FCNs) on CIFAR-10, showing a short highly non-optimal regime followed by a longer optimal regime.
Variational Prediction
Jul 14, 2023Bayesian inference offers benefits over maximum likelihood, but it also comes with computational costs. Computing the posterior is typically intractable, as is marginalizing that posterior to form the posterior predictive distribution. In this paper, we present variational prediction, a technique for directly learning a variational approximation to the posterior predictive distribution using a variational bound. This approach can provide good predictive distributions without test time marginalization costs. We demonstrate Variational Prediction on an illustrative toy example.
Weighted Ensemble Self-Supervised Learning
Nov 18, 2022


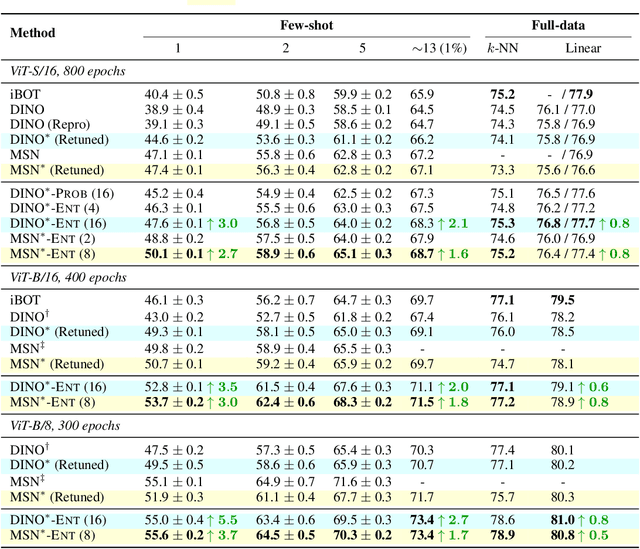
Ensembling has proven to be a powerful technique for boosting model performance, uncertainty estimation, and robustness in supervised learning. Advances in self-supervised learning (SSL) enable leveraging large unlabeled corpora for state-of-the-art few-shot and supervised learning performance. In this paper, we explore how ensemble methods can improve recent SSL techniques by developing a framework that permits data-dependent weighted cross-entropy losses. We refrain from ensembling the representation backbone; this choice yields an efficient ensemble method that incurs a small training cost and requires no architectural changes or computational overhead to downstream evaluation. The effectiveness of our method is demonstrated with two state-of-the-art SSL methods, DINO (Caron et al., 2021) and MSN (Assran et al., 2022). Our method outperforms both in multiple evaluation metrics on ImageNet-1K, particularly in the few-shot setting. We explore several weighting schemes and find that those which increase the diversity of ensemble heads lead to better downstream evaluation results. Thorough experiments yield improved prior art baselines which our method still surpasses; e.g., our overall improvement with MSN ViT-B/16 is 3.9 p.p. for 1-shot learning.
Bayesian Imitation Learning for End-to-End Mobile Manipulation
Feb 15, 2022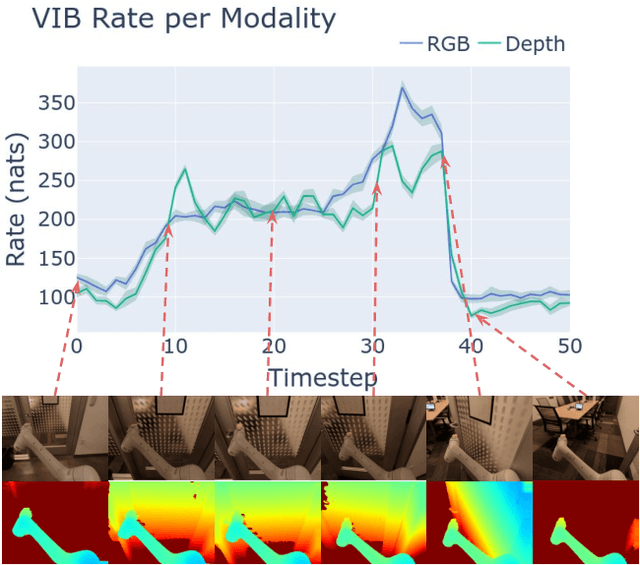
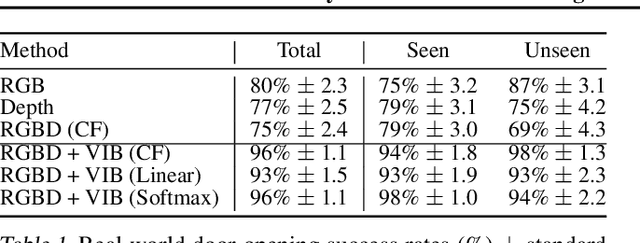
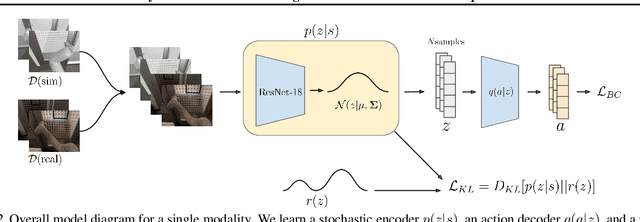
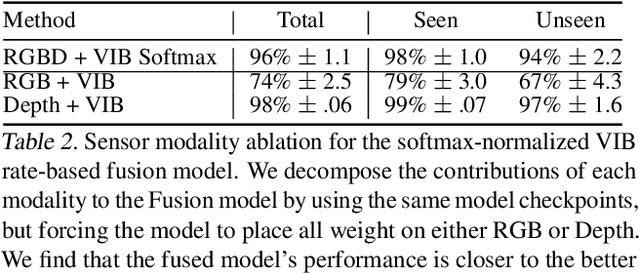
In this work we investigate and demonstrate benefits of a Bayesian approach to imitation learning from multiple sensor inputs, as applied to the task of opening office doors with a mobile manipulator. Augmenting policies with additional sensor inputs, such as RGB + depth cameras, is a straightforward approach to improving robot perception capabilities, especially for tasks that may favor different sensors in different situations. As we scale multi-sensor robotic learning to unstructured real-world settings (e.g. offices, homes) and more complex robot behaviors, we also increase reliance on simulators for cost, efficiency, and safety. Consequently, the sim-to-real gap across multiple sensor modalities also increases, making simulated validation more difficult. We show that using the Variational Information Bottleneck (Alemi et al., 2016) to regularize convolutional neural networks improves generalization to held-out domains and reduces the sim-to-real gap in a sensor-agnostic manner. As a side effect, the learned embeddings also provide useful estimates of model uncertainty for each sensor. We demonstrate that our method is able to help close the sim-to-real gap and successfully fuse RGB and depth modalities based on understanding of the situational uncertainty of each sensor. In a real-world office environment, we achieve 96% task success, improving upon the baseline by +16%.
A Closer Look at the Adversarial Robustness of Information Bottleneck Models
Jul 12, 2021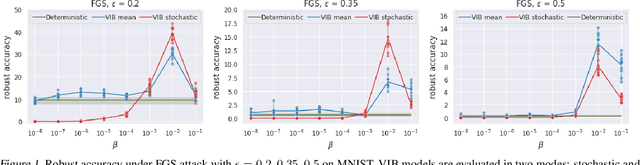
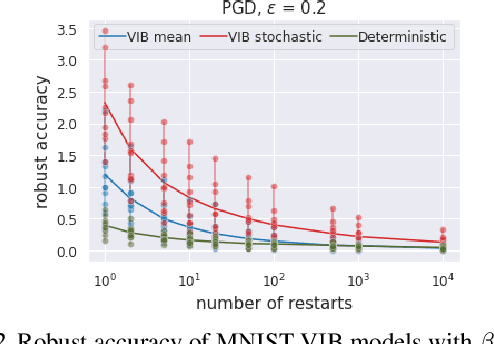
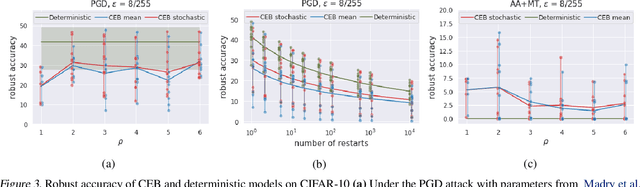
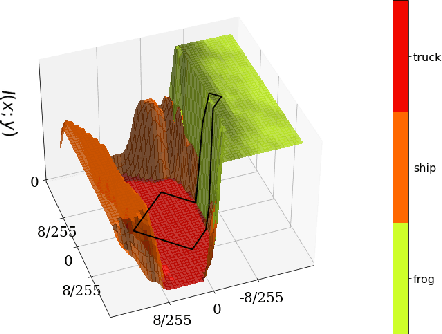
We study the adversarial robustness of information bottleneck models for classification. Previous works showed that the robustness of models trained with information bottlenecks can improve upon adversarial training. Our evaluation under a diverse range of white-box $l_{\infty}$ attacks suggests that information bottlenecks alone are not a strong defense strategy, and that previous results were likely influenced by gradient obfuscation.
Does Knowledge Distillation Really Work?
Jun 10, 2021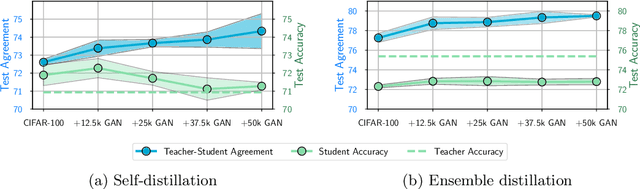
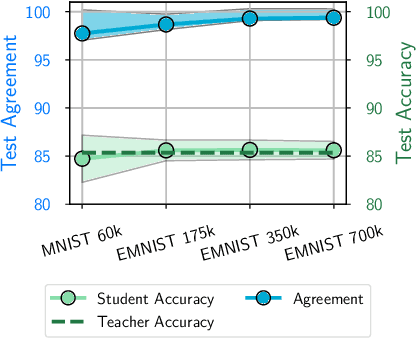

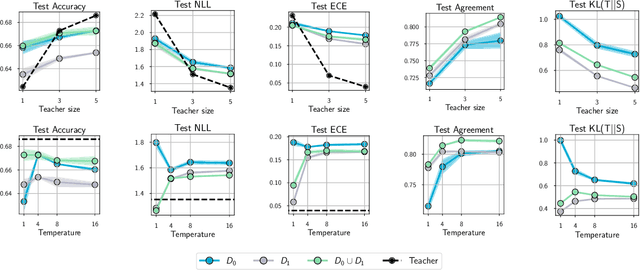
Knowledge distillation is a popular technique for training a small student network to emulate a larger teacher model, such as an ensemble of networks. We show that while knowledge distillation can improve student generalization, it does not typically work as it is commonly understood: there often remains a surprisingly large discrepancy between the predictive distributions of the teacher and the student, even in cases when the student has the capacity to perfectly match the teacher. We identify difficulties in optimization as a key reason for why the student is unable to match the teacher. We also show how the details of the dataset used for distillation play a role in how closely the student matches the teacher -- and that more closely matching the teacher paradoxically does not always lead to better student generalization.
PAC$^m$-Bayes: Narrowing the Empirical Risk Gap in the Misspecified Bayesian Regime
Oct 19, 2020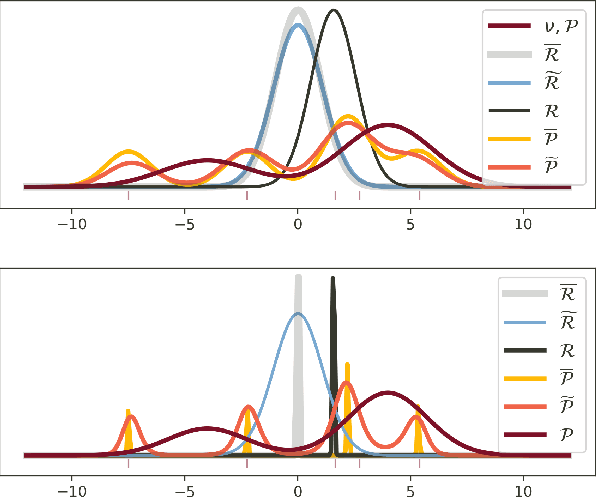
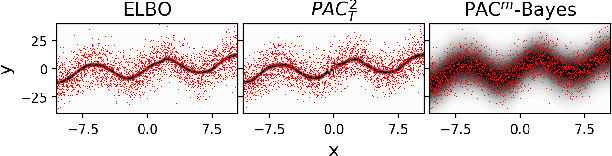
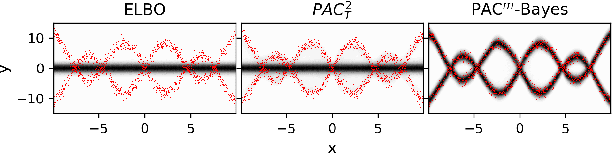
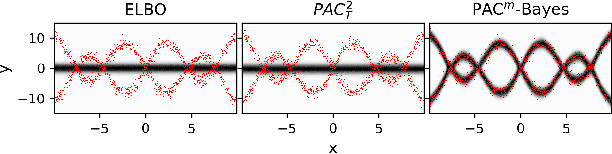
While the decision-theoretic optimality of the Bayesian formalism under correct model specification is well-known (Berger 2013), the Bayesian case becomes less clear under model misspecification (Grunwald 2017; Ramamoorthi 2015; Fushiki 2005). To formally understand the consequences of Bayesian misspecification, this work examines the relationship between posterior predictive risk and its sensitivity to correct model assumptions, i.e., choice of likelihood and prior. We present the multisample PAC$^m$-Bayes risk. This risk is justified by theoretical analysis based on PAC-Bayes as well as empirical study on a number of toy problems. The PAC$^m$-Bayes risk is appealing in that it entails direct minimization of the Monte-Carlo approximated posterior predictive risk yet recovers both the Bayesian formalism as well as the MLE in its limits. Our work is heavily influenced by Masegosa (2019); our contributions are to align training and generalization risks while offering a tighter bound which empirically performs at least as well and sometimes much better.
Density of States Estimation for Out-of-Distribution Detection
Jun 22, 2020
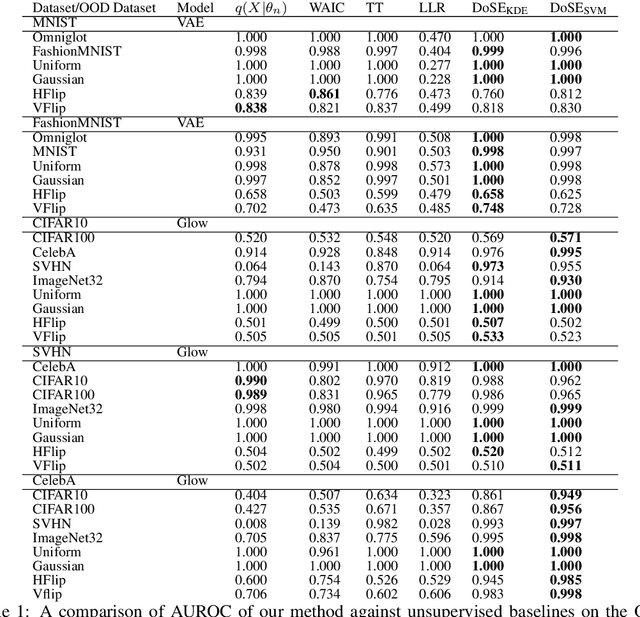
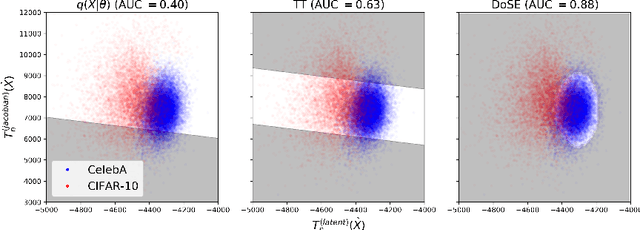
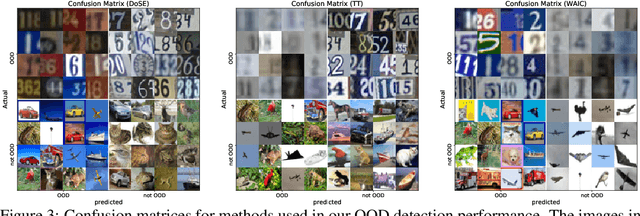
Perhaps surprisingly, recent studies have shown probabilistic model likelihoods have poor specificity for out-of-distribution (OOD) detection and often assign higher likelihoods to OOD data than in-distribution data. To ameliorate this issue we propose DoSE, the density of states estimator. Drawing on the statistical physics notion of ``density of states,'' the DoSE decision rule avoids direct comparison of model probabilities, and instead utilizes the ``probability of the model probability,'' or indeed the frequency of any reasonable statistic. The frequency is calculated using nonparametric density estimators (e.g., KDE and one-class SVM) which measure the typicality of various model statistics given the training data and from which we can flag test points with low typicality as anomalous. Unlike many other methods, DoSE requires neither labeled data nor OOD examples. DoSE is modular and can be trivially applied to any existing, trained model. We demonstrate DoSE's state-of-the-art performance against other unsupervised OOD detectors on previously established ``hard'' benchmarks.
CEB Improves Model Robustness
Feb 13, 2020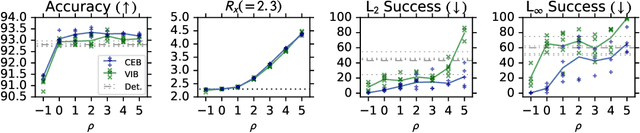
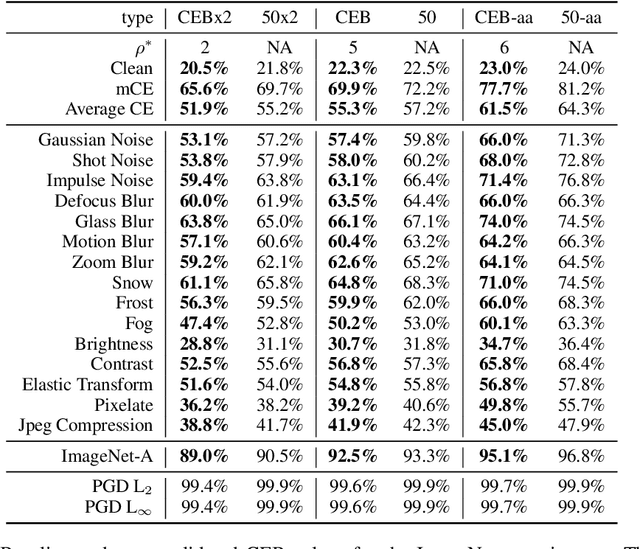
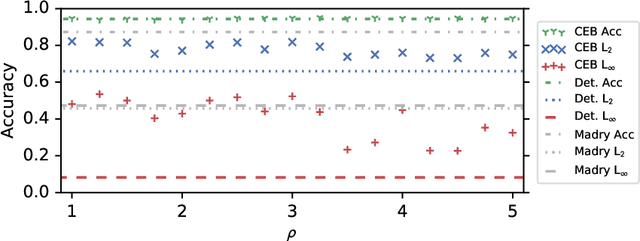
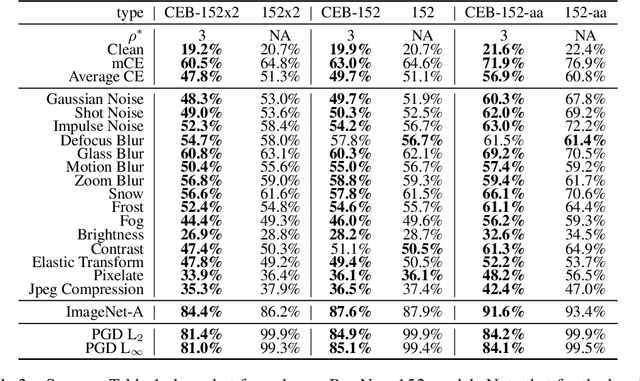
We demonstrate that the Conditional Entropy Bottleneck (CEB) can improve model robustness. CEB is an easy strategy to implement and works in tandem with data augmentation procedures. We report results of a large scale adversarial robustness study on CIFAR-10, as well as the ImageNet-C Common Corruptions Benchmark, ImageNet-A, and PGD attacks.