 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSchrödinger Bridge Flow for Unpaired Data Translation
Sep 14, 2024Mass transport problems arise in many areas of machine learning whereby one wants to compute a map transporting one distribution to another. Generative modeling techniques like Generative Adversarial Networks (GANs) and Denoising Diffusion Models (DDMs) have been successfully adapted to solve such transport problems, resulting in CycleGAN and Bridge Matching respectively. However, these methods do not approximate Optimal Transport (OT) maps, which are known to have desirable properties. Existing techniques approximating OT maps for high-dimensional data-rich problems, such as DDM-based Rectified Flow and Schr\"odinger Bridge procedures, require fully training a DDM-type model at each iteration, or use mini-batch techniques which can introduce significant errors. We propose a novel algorithm to compute the Schr\"odinger Bridge, a dynamic entropy-regularised version of OT, that eliminates the need to train multiple DDM-like models. This algorithm corresponds to a discretisation of a flow of path measures, which we call the Schr\"odinger Bridge Flow, whose only stationary point is the Schr\"odinger Bridge. We demonstrate the performance of our algorithm on a variety of unpaired data translation tasks.
A Closer Look at the Adversarial Robustness of Information Bottleneck Models
Jul 12, 2021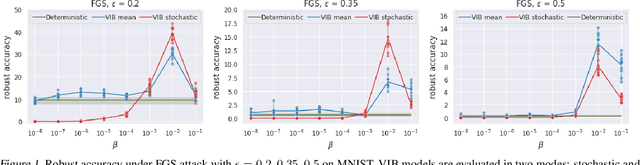
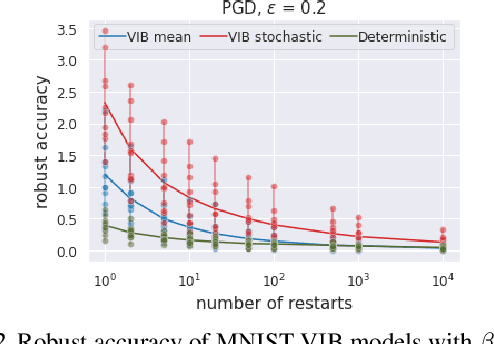
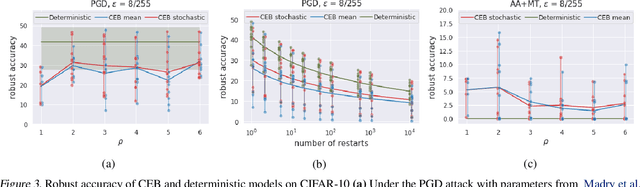
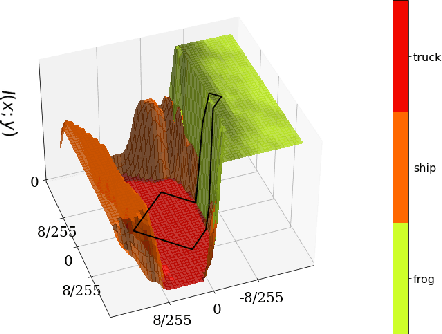
We study the adversarial robustness of information bottleneck models for classification. Previous works showed that the robustness of models trained with information bottlenecks can improve upon adversarial training. Our evaluation under a diverse range of white-box $l_{\infty}$ attacks suggests that information bottlenecks alone are not a strong defense strategy, and that previous results were likely influenced by gradient obfuscation.
Discriminative Topic Modeling with Logistic LDA
Sep 03, 2019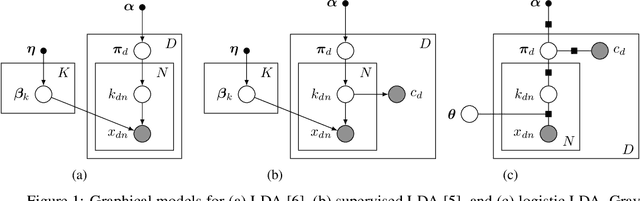


Despite many years of research into latent Dirichlet allocation (LDA), applying LDA to collections of non-categorical items is still challenging. Yet many problems with much richer data share a similar structure and could benefit from the vast literature on LDA. We propose logistic LDA, a novel discriminative variant of latent Dirichlet allocation which is easy to apply to arbitrary inputs. In particular, our model can easily be applied to groups of images, arbitrary text embeddings, and integrate well with deep neural networks. Although it is a discriminative model, we show that logistic LDA can learn from unlabeled data in an unsupervised manner by exploiting the group structure present in the data. In contrast to other recent topic models designed to handle arbitrary inputs, our model does not sacrifice the interpretability and principled motivation of LDA.
BRUNO: A Deep Recurrent Model for Exchangeable Data
Oct 16, 2018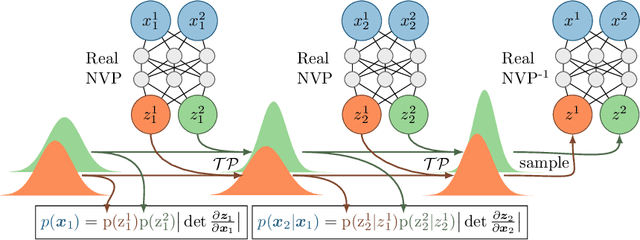
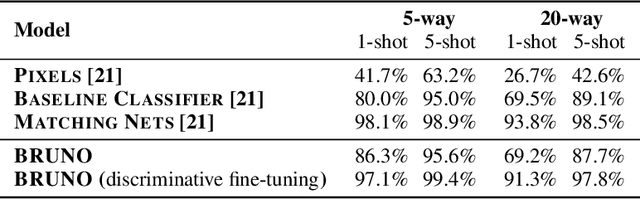

We present a novel model architecture which leverages deep learning tools to perform exact Bayesian inference on sets of high dimensional, complex observations. Our model is provably exchangeable, meaning that the joint distribution over observations is invariant under permutation: this property lies at the heart of Bayesian inference. The model does not require variational approximations to train, and new samples can be generated conditional on previous samples, with cost linear in the size of the conditioning set. The advantages of our architecture are demonstrated on learning tasks that require generalisation from short observed sequences while modelling sequence variability, such as conditional image generation, few-shot learning, and anomaly detection.
Faster gaze prediction with dense networks and Fisher pruning
Jul 09, 2018
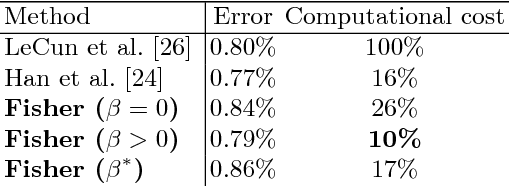

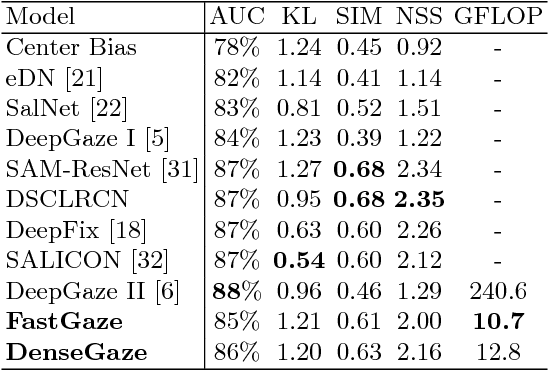
Predicting human fixations from images has recently seen large improvements by leveraging deep representations which were pretrained for object recognition. However, as we show in this paper, these networks are highly overparameterized for the task of fixation prediction. We first present a simple yet principled greedy pruning method which we call Fisher pruning. Through a combination of knowledge distillation and Fisher pruning, we obtain much more runtime-efficient architectures for saliency prediction, achieving a 10x speedup for the same AUC performance as a state of the art network on the CAT2000 dataset. Speeding up single-image gaze prediction is important for many real-world applications, but it is also a crucial step in the development of video saliency models, where the amount of data to be processed is substantially larger.
Fast Face-swap Using Convolutional Neural Networks
Jul 27, 2017
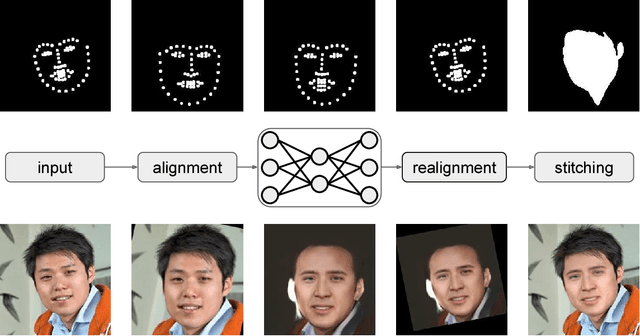
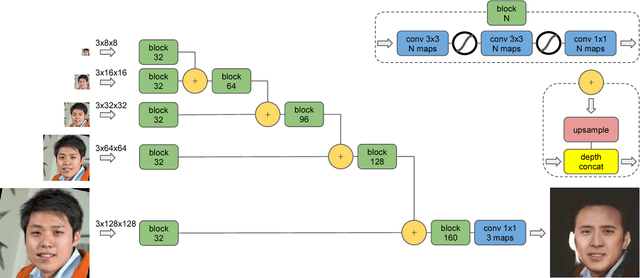

We consider the problem of face swapping in images, where an input identity is transformed into a target identity while preserving pose, facial expression, and lighting. To perform this mapping, we use convolutional neural networks trained to capture the appearance of the target identity from an unstructured collection of his/her photographs.This approach is enabled by framing the face swapping problem in terms of style transfer, where the goal is to render an image in the style of another one. Building on recent advances in this area, we devise a new loss function that enables the network to produce highly photorealistic results. By combining neural networks with simple pre- and post-processing steps, we aim at making face swap work in real-time with no input from the user.
Music transcription modelling and composition using deep learning
Apr 29, 2016



We apply deep learning methods, specifically long short-term memory (LSTM) networks, to music transcription modelling and composition. We build and train LSTM networks using approximately 23,000 music transcriptions expressed with a high-level vocabulary (ABC notation), and use them to generate new transcriptions. Our practical aim is to create music transcription models useful in particular contexts of music composition. We present results from three perspectives: 1) at the population level, comparing descriptive statistics of the set of training transcriptions and generated transcriptions; 2) at the individual level, examining how a generated transcription reflects the conventions of a music practice in the training transcriptions (Celtic folk); 3) at the application level, using the system for idea generation in music composition. We make our datasets, software and sound examples open and available: \url{https://github.com/IraKorshunova/folk-rnn}.