 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffort and Size Estimation in Software Projects with Large Language Model-based Intelligent Interfaces
Feb 11, 2024The advancement of Large Language Models (LLM) has also resulted in an equivalent proliferation in its applications. Software design, being one, has gained tremendous benefits in using LLMs as an interface component that extends fixed user stories. However, inclusion of LLM-based AI agents in software design often poses unexpected challenges, especially in the estimation of development efforts. Through the example of UI-based user stories, we provide a comparison against traditional methods and propose a new way to enhance specifications of natural language-based questions that allows for the estimation of development effort by taking into account data sources, interfaces and algorithms.
Discriminative Topic Modeling with Logistic LDA
Sep 03, 2019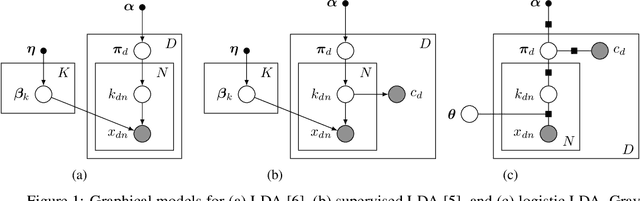


Despite many years of research into latent Dirichlet allocation (LDA), applying LDA to collections of non-categorical items is still challenging. Yet many problems with much richer data share a similar structure and could benefit from the vast literature on LDA. We propose logistic LDA, a novel discriminative variant of latent Dirichlet allocation which is easy to apply to arbitrary inputs. In particular, our model can easily be applied to groups of images, arbitrary text embeddings, and integrate well with deep neural networks. Although it is a discriminative model, we show that logistic LDA can learn from unlabeled data in an unsupervised manner by exploiting the group structure present in the data. In contrast to other recent topic models designed to handle arbitrary inputs, our model does not sacrifice the interpretability and principled motivation of LDA.
Fighting Redundancy and Model Decay with Embeddings
Sep 18, 2018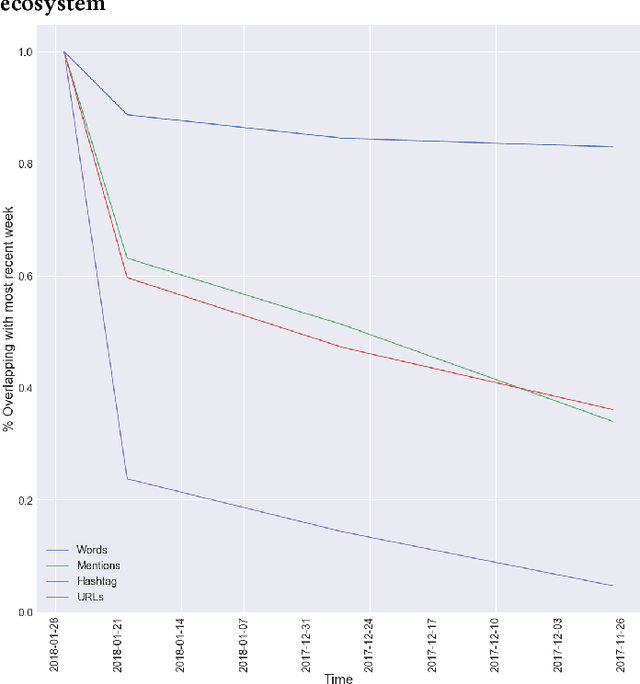

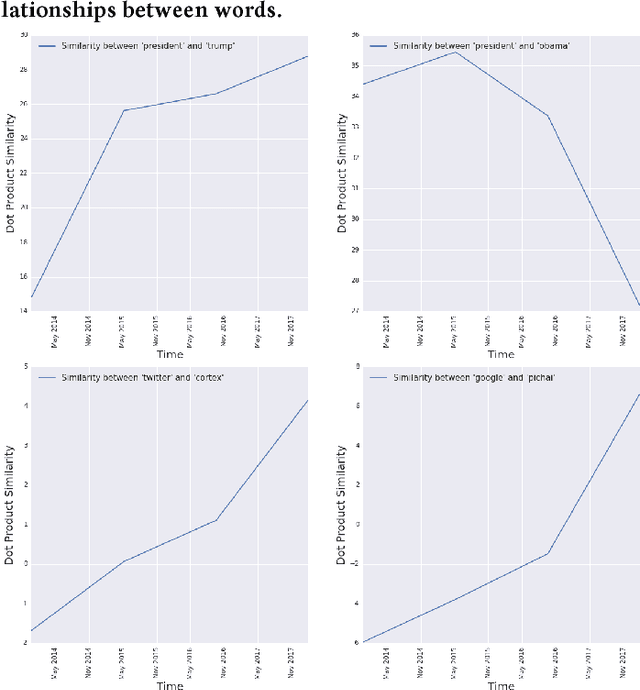

Every day, hundreds of millions of new Tweets containing over 40 languages of ever-shifting vernacular flow through Twitter. Models that attempt to extract insight from this firehose of information must face the torrential covariate shift that is endemic to the Twitter platform. While regularly-retrained algorithms can maintain performance in the face of this shift, fixed model features that fail to represent new trends and tokens can quickly become stale, resulting in performance degradation. To mitigate this problem we employ learned features, or embedding models, that can efficiently represent the most relevant aspects of a data distribution. Sharing these embedding models across teams can also reduce redundancy and multiplicatively increase cross-team modeling productivity. In this paper, we detail the commoditized tools, algorithms and pipelines that we have developed and are developing at Twitter to regularly generate high quality, up-to-date embeddings and share them broadly across the company.
Active and Transfer Learning of Grasps by Kernel Adaptive MCMC
Nov 19, 2016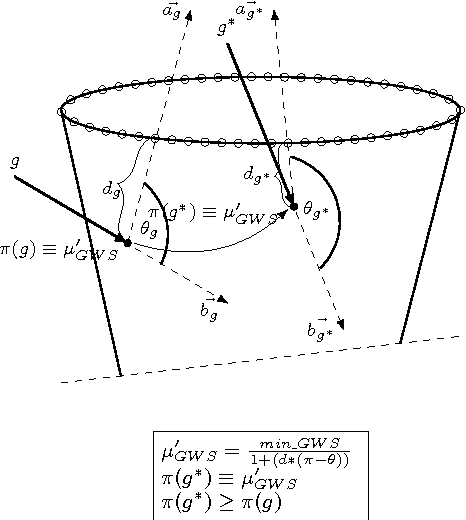


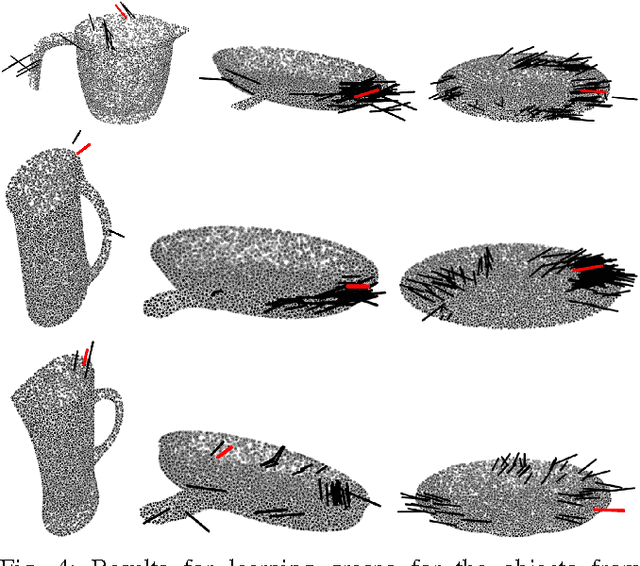
Human ability of both versatile grasping of given objects and grasping of novel (as of yet unseen) objects is truly remarkable. This probably arises from the experience infants gather by actively playing around with diverse objects. Moreover, knowledge acquired during this process is reused during learning of how to grasp novel objects. We conjecture that this combined process of active and transfer learning boils down to a random search around an object, suitably biased by prior experience, to identify promising grasps. In this paper we present an active learning method for learning of grasps for given objects, and a transfer learning method for learning of grasps for novel objects. Our learning methods apply a kernel adaptive Metropolis-Hastings sampler that learns an approximation of the grasps' probability density of an object while drawing grasp proposals from it. The sampler employs simulated annealing to search for globally-optimal grasps. Our empirical results show promising applicability of our proposed learning schemes.