 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFighting Redundancy and Model Decay with Embeddings
Sep 18, 2018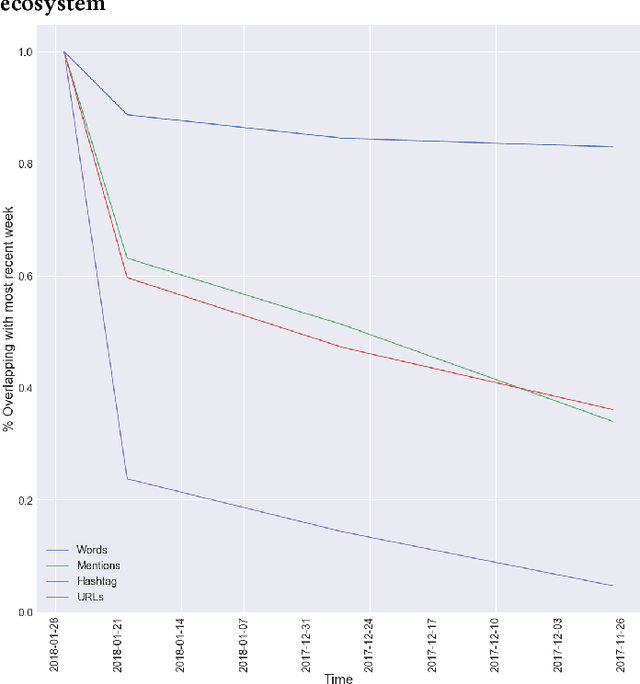

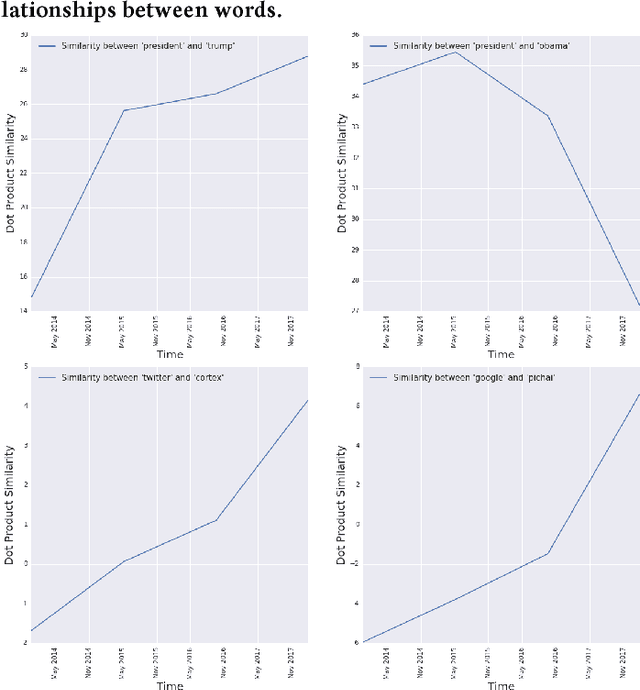

Every day, hundreds of millions of new Tweets containing over 40 languages of ever-shifting vernacular flow through Twitter. Models that attempt to extract insight from this firehose of information must face the torrential covariate shift that is endemic to the Twitter platform. While regularly-retrained algorithms can maintain performance in the face of this shift, fixed model features that fail to represent new trends and tokens can quickly become stale, resulting in performance degradation. To mitigate this problem we employ learned features, or embedding models, that can efficiently represent the most relevant aspects of a data distribution. Sharing these embedding models across teams can also reduce redundancy and multiplicatively increase cross-team modeling productivity. In this paper, we detail the commoditized tools, algorithms and pipelines that we have developed and are developing at Twitter to regularly generate high quality, up-to-date embeddings and share them broadly across the company.