 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLessons Learned Addressing Dataset Bias in Model-Based Candidate Generation at Twitter
May 13, 2021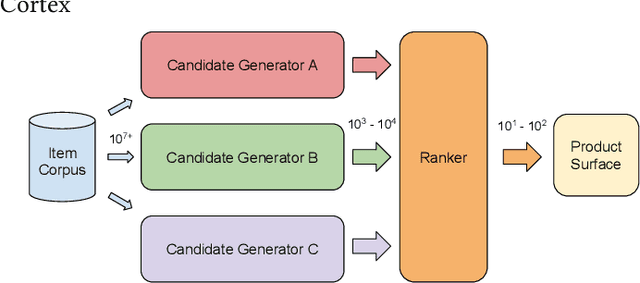
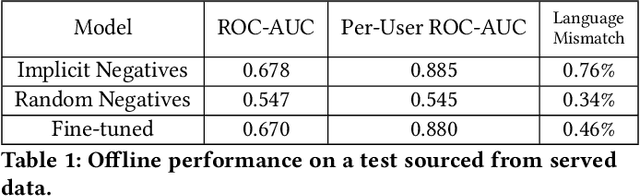
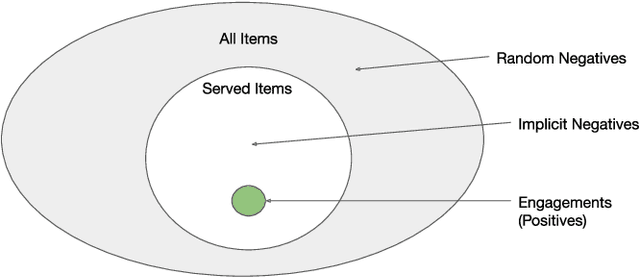
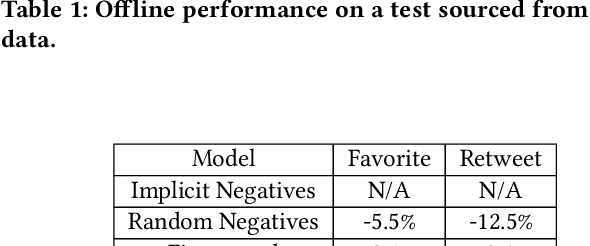
Traditionally, heuristic methods are used to generate candidates for large scale recommender systems. Model-based candidate generation promises multiple potential advantages, primarily that we can explicitly optimize the same objective as the downstream ranking model. However, large scale model-based candidate generation approaches suffer from dataset bias problems caused by the infeasibility of obtaining representative data on very irrelevant candidates. Popular techniques to correct dataset bias, such as inverse propensity scoring, do not work well in the context of candidate generation. We first explore the dynamics of the dataset bias problem and then demonstrate how to use random sampling techniques to mitigate it. Finally, in a novel application of fine-tuning, we show performance gains when applying our candidate generation system to Twitter's home timeline.
Fighting Redundancy and Model Decay with Embeddings
Sep 18, 2018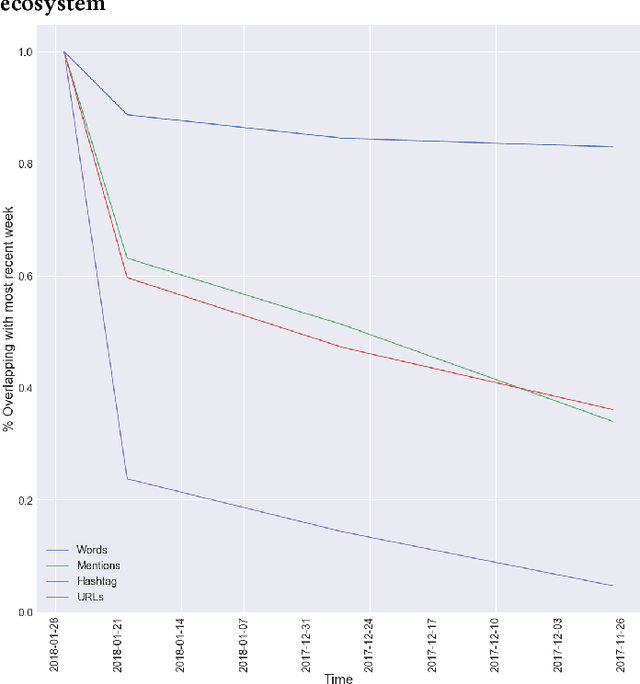

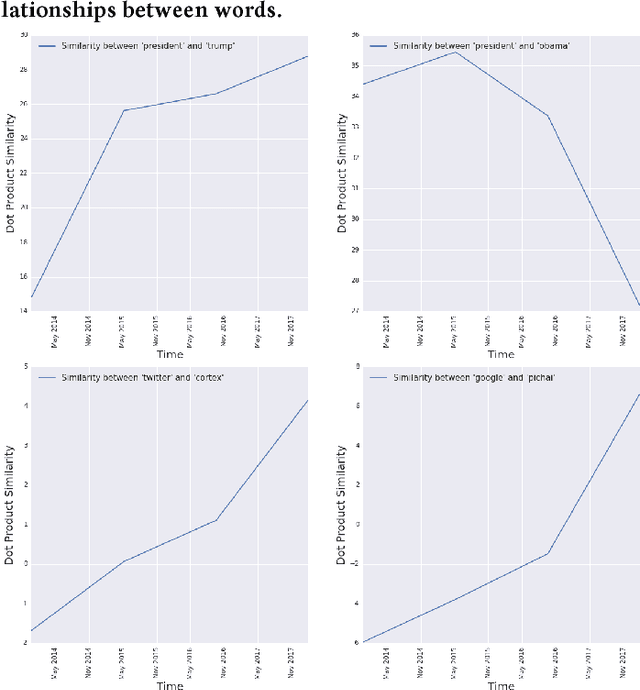

Every day, hundreds of millions of new Tweets containing over 40 languages of ever-shifting vernacular flow through Twitter. Models that attempt to extract insight from this firehose of information must face the torrential covariate shift that is endemic to the Twitter platform. While regularly-retrained algorithms can maintain performance in the face of this shift, fixed model features that fail to represent new trends and tokens can quickly become stale, resulting in performance degradation. To mitigate this problem we employ learned features, or embedding models, that can efficiently represent the most relevant aspects of a data distribution. Sharing these embedding models across teams can also reduce redundancy and multiplicatively increase cross-team modeling productivity. In this paper, we detail the commoditized tools, algorithms and pipelines that we have developed and are developing at Twitter to regularly generate high quality, up-to-date embeddings and share them broadly across the company.
BayesDB: A probabilistic programming system for querying the probable implications of data
Dec 15, 2015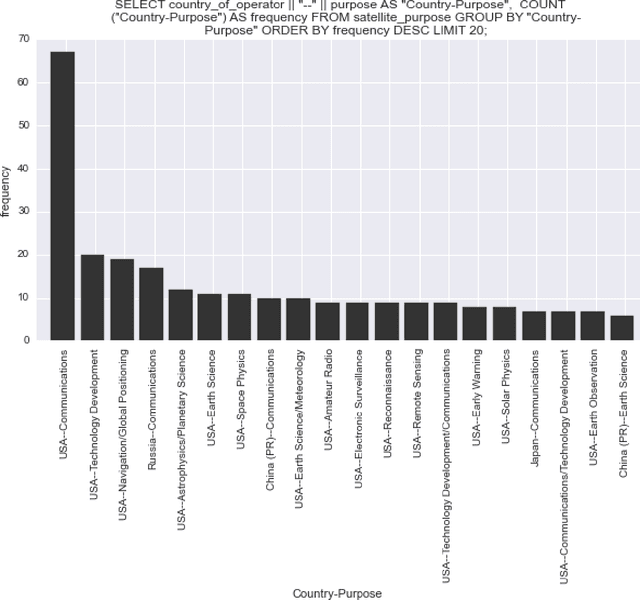
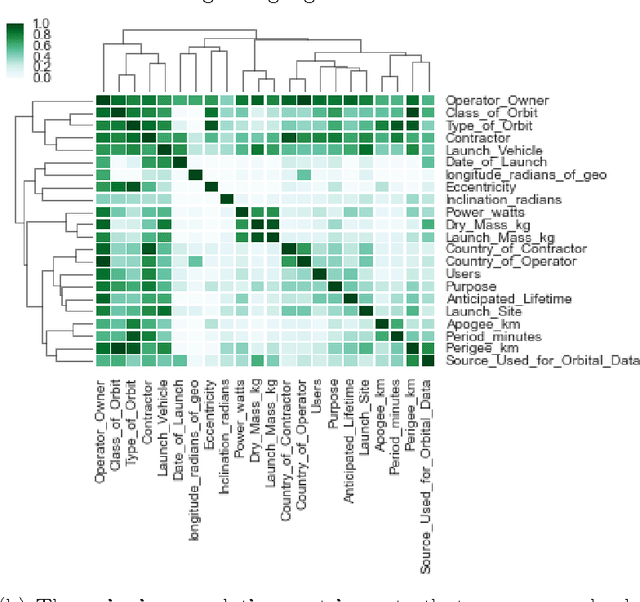
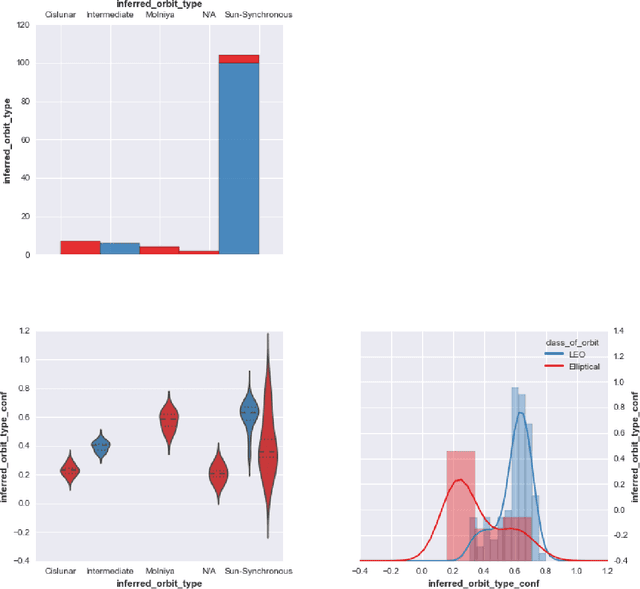
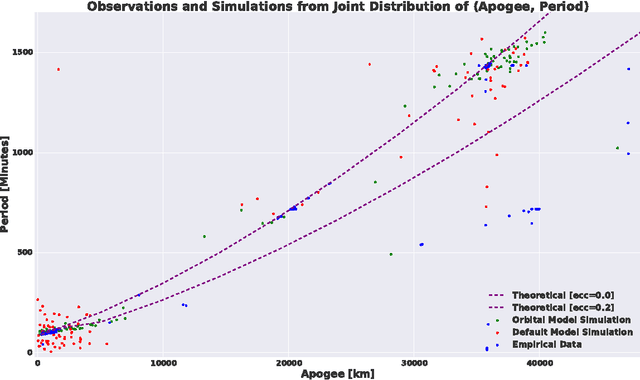
Is it possible to make statistical inference broadly accessible to non-statisticians without sacrificing mathematical rigor or inference quality? This paper describes BayesDB, a probabilistic programming platform that aims to enable users to query the probable implications of their data as directly as SQL databases enable them to query the data itself. This paper focuses on four aspects of BayesDB: (i) BQL, an SQL-like query language for Bayesian data analysis, that answers queries by averaging over an implicit space of probabilistic models; (ii) techniques for implementing BQL using a broad class of multivariate probabilistic models; (iii) a semi-parametric Bayesian model-builder that auomatically builds ensembles of factorial mixture models to serve as baselines; and (iv) MML, a "meta-modeling" language for imposing qualitative constraints on the model-builder and combining baseline models with custom algorithmic and statistical models that can be implemented in external software. BayesDB is illustrated using three applications: cleaning and exploring a public database of Earth satellites; assessing the evidence for temporal dependence between macroeconomic indicators; and analyzing a salary survey.