 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeURL-BERT: Training Webpage Representations via Social Media Engagements
Oct 25, 2023



Understanding and representing webpages is crucial to online social networks where users may share and engage with URLs. Common language model (LM) encoders such as BERT can be used to understand and represent the textual content of webpages. However, these representations may not model thematic information of web domains and URLs or accurately capture their appeal to social media users. In this work, we introduce a new pre-training objective that can be used to adapt LMs to understand URLs and webpages. Our proposed framework consists of two steps: (1) scalable graph embeddings to learn shallow representations of URLs based on user engagement on social media and (2) a contrastive objective that aligns LM representations with the aforementioned graph-based representation. We apply our framework to the multilingual version of BERT to obtain the model URL-BERT. We experimentally demonstrate that our continued pre-training approach improves webpage understanding on a variety of tasks and Twitter internal and external benchmarks.
Lessons Learned Addressing Dataset Bias in Model-Based Candidate Generation at Twitter
May 13, 2021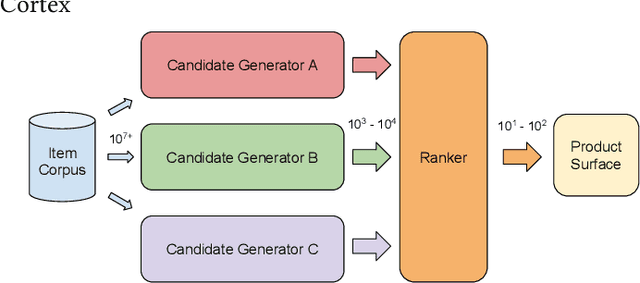
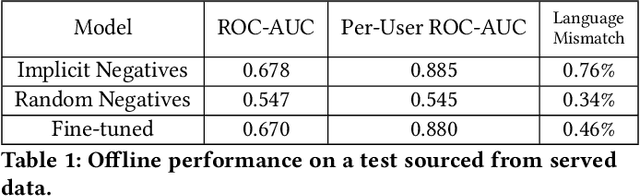
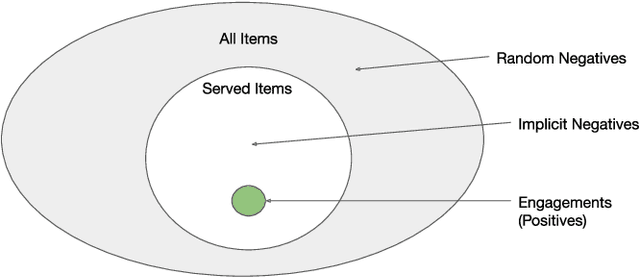
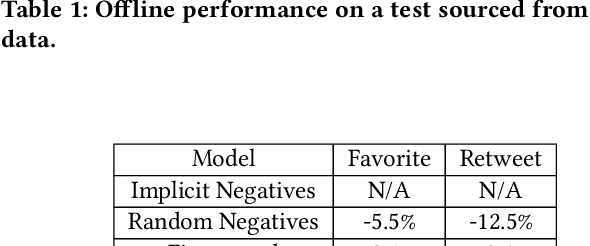
Traditionally, heuristic methods are used to generate candidates for large scale recommender systems. Model-based candidate generation promises multiple potential advantages, primarily that we can explicitly optimize the same objective as the downstream ranking model. However, large scale model-based candidate generation approaches suffer from dataset bias problems caused by the infeasibility of obtaining representative data on very irrelevant candidates. Popular techniques to correct dataset bias, such as inverse propensity scoring, do not work well in the context of candidate generation. We first explore the dynamics of the dataset bias problem and then demonstrate how to use random sampling techniques to mitigate it. Finally, in a novel application of fine-tuning, we show performance gains when applying our candidate generation system to Twitter's home timeline.