 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMONA: Event-level Moral Opinions in News Articles
Apr 02, 2024



Most previous research on moral frames has focused on social media short texts, little work has explored moral sentiment within news articles. In news articles, authors often express their opinions or political stance through moral judgment towards events, specifically whether the event is right or wrong according to social moral rules. This paper initiates a new task to understand moral opinions towards events in news articles. We have created a new dataset, EMONA, and annotated event-level moral opinions in news articles. This dataset consists of 400 news articles containing over 10k sentences and 45k events, among which 9,613 events received moral foundation labels. Extracting event morality is a challenging task, as moral judgment towards events can be very implicit. Baseline models were built for event moral identification and classification. In addition, we also conduct extrinsic evaluations to integrate event-level moral opinions into three downstream tasks. The statistical analysis and experiments show that moral opinions of events can serve as informative features for identifying ideological bias or subjective events.
URL-BERT: Training Webpage Representations via Social Media Engagements
Oct 25, 2023



Understanding and representing webpages is crucial to online social networks where users may share and engage with URLs. Common language model (LM) encoders such as BERT can be used to understand and represent the textual content of webpages. However, these representations may not model thematic information of web domains and URLs or accurately capture their appeal to social media users. In this work, we introduce a new pre-training objective that can be used to adapt LMs to understand URLs and webpages. Our proposed framework consists of two steps: (1) scalable graph embeddings to learn shallow representations of URLs based on user engagement on social media and (2) a contrastive objective that aligns LM representations with the aforementioned graph-based representation. We apply our framework to the multilingual version of BERT to obtain the model URL-BERT. We experimentally demonstrate that our continued pre-training approach improves webpage understanding on a variety of tasks and Twitter internal and external benchmarks.
Detecting Compliance of Privacy Policies with Data Protection Laws
Feb 21, 2021


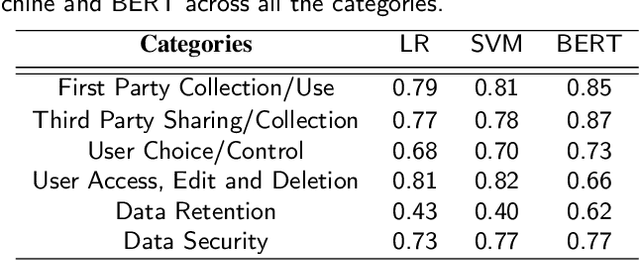
Privacy Policies are the legal documents that describe the practices that an organization or company has adopted in the handling of the personal data of its users. But as policies are a legal document, they are often written in extensive legal jargon that is difficult to understand. Though work has been done on privacy policies but none that caters to the problem of verifying if a given privacy policy adheres to the data protection laws of a given country or state. We aim to bridge that gap by providing a framework that analyzes privacy policies in light of various data protection laws, such as the General Data Protection Regulation (GDPR). To achieve that, firstly we labeled both the privacy policies and laws. Then a correlation scheme is developed to map the contents of a privacy policy to the appropriate segments of law that a policy must conform to. Then we check the compliance of privacy policy's text with the corresponding text of the law using NLP techniques. By using such a tool, users would be better equipped to understand how their personal data is managed. For now, we have provided a mapping for the GDPR and PDPA, but other laws can easily be incorporated in the already built pipeline.