 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
OpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
URL-BERT: Training Webpage Representations via Social Media Engagements
Oct 25, 2023



Understanding and representing webpages is crucial to online social networks where users may share and engage with URLs. Common language model (LM) encoders such as BERT can be used to understand and represent the textual content of webpages. However, these representations may not model thematic information of web domains and URLs or accurately capture their appeal to social media users. In this work, we introduce a new pre-training objective that can be used to adapt LMs to understand URLs and webpages. Our proposed framework consists of two steps: (1) scalable graph embeddings to learn shallow representations of URLs based on user engagement on social media and (2) a contrastive objective that aligns LM representations with the aforementioned graph-based representation. We apply our framework to the multilingual version of BERT to obtain the model URL-BERT. We experimentally demonstrate that our continued pre-training approach improves webpage understanding on a variety of tasks and Twitter internal and external benchmarks.
NTULM: Enriching Social Media Text Representations with Non-Textual Units
Oct 29, 2022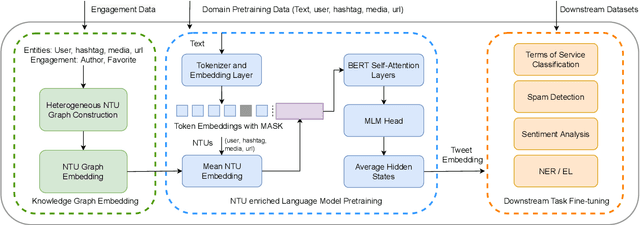

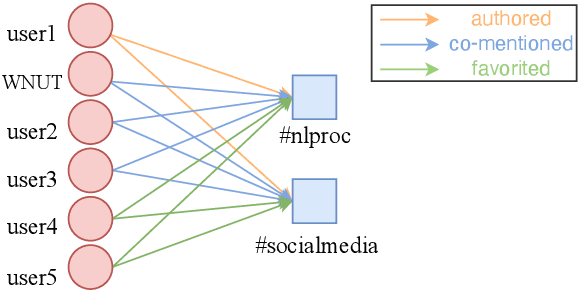
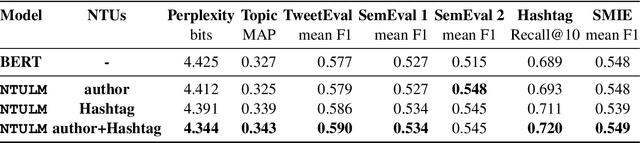
On social media, additional context is often present in the form of annotations and meta-data such as the post's author, mentions, Hashtags, and hyperlinks. We refer to these annotations as Non-Textual Units (NTUs). We posit that NTUs provide social context beyond their textual semantics and leveraging these units can enrich social media text representations. In this work we construct an NTU-centric social heterogeneous network to co-embed NTUs. We then principally integrate these NTU embeddings into a large pretrained language model by fine-tuning with these additional units. This adds context to noisy short-text social media. Experiments show that utilizing NTU-augmented text representations significantly outperforms existing text-only baselines by 2-5\% relative points on many downstream tasks highlighting the importance of context to social media NLP. We also highlight that including NTU context into the initial layers of language model alongside text is better than using it after the text embedding is generated. Our work leads to the generation of holistic general purpose social media content embedding.
MiCRO: Multi-interest Candidate Retrieval Online
Oct 28, 2022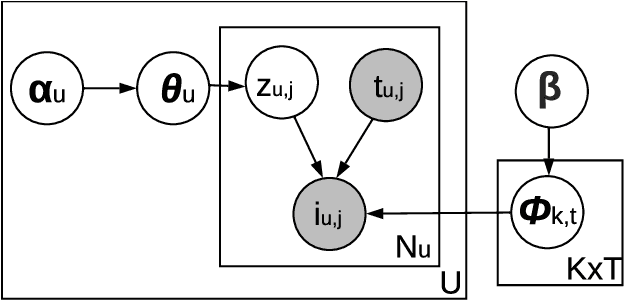
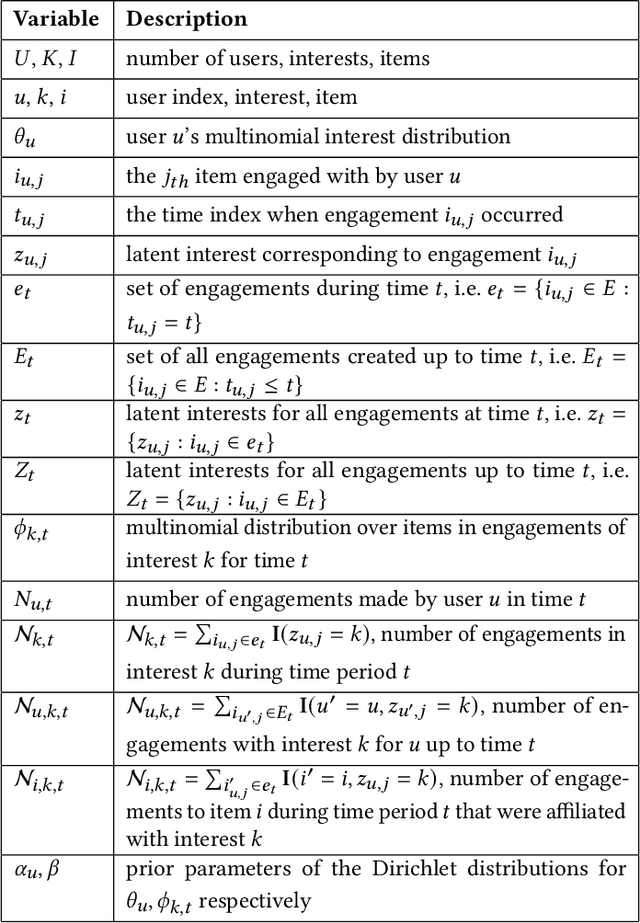
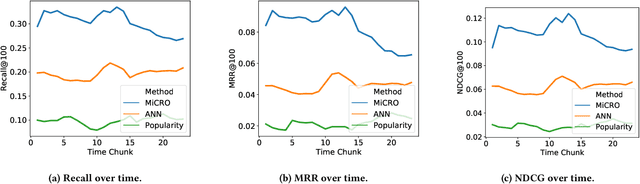
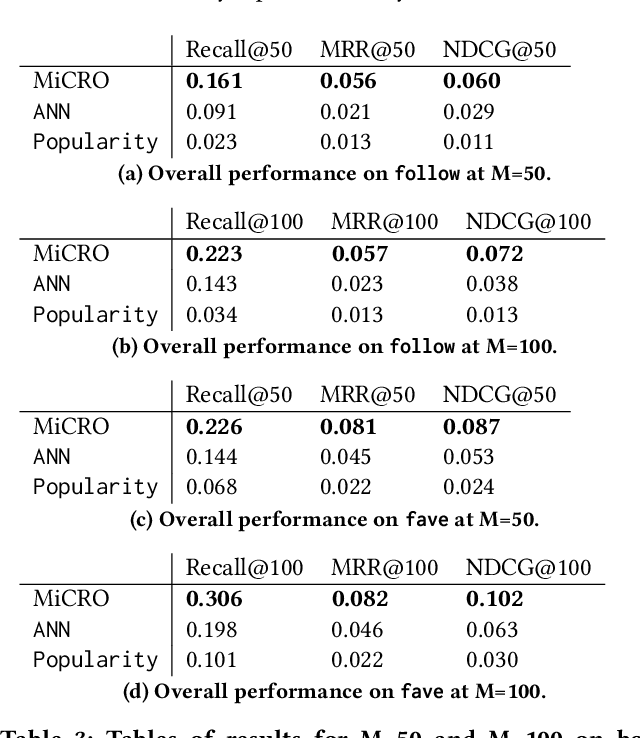
Providing personalized recommendations in an environment where items exhibit ephemerality and temporal relevancy (e.g. in social media) presents a few unique challenges: (1) inductively understanding ephemeral appeal for items in a setting where new items are created frequently, (2) adapting to trends within engagement patterns where items may undergo temporal shifts in relevance, (3) accurately modeling user preferences over this item space where users may express multiple interests. In this work we introduce MiCRO, a generative statistical framework that models multi-interest user preferences and temporal multi-interest item representations. Our framework is specifically formulated to adapt to both new items and temporal patterns of engagement. MiCRO demonstrates strong empirical performance on candidate retrieval experiments performed on two large scale user-item datasets: (1) an open-source temporal dataset of (User, User) follow interactions and (2) a temporal dataset of (User, Tweet) favorite interactions which we will open-source as an additional contribution to the community.
TwHIN-BERT: A Socially-Enriched Pre-trained Language Model for Multilingual Tweet Representations
Sep 15, 2022
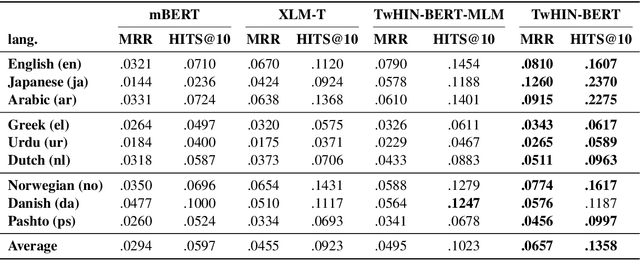

We present TwHIN-BERT, a multilingual language model trained on in-domain data from the popular social network Twitter. TwHIN-BERT differs from prior pre-trained language models as it is trained with not only text-based self-supervision, but also with a social objective based on the rich social engagements within a Twitter heterogeneous information network (TwHIN). Our model is trained on 7 billion tweets covering over 100 distinct languages providing a valuable representation to model short, noisy, user-generated text. We evaluate our model on a variety of multilingual social recommendation and semantic understanding tasks and demonstrate significant metric improvement over established pre-trained language models. We will freely open-source TwHIN-BERT and our curated hashtag prediction and social engagement benchmark datasets to the research community.
Non-Parametric Temporal Adaptation for Social Media Topic Classification
Sep 13, 2022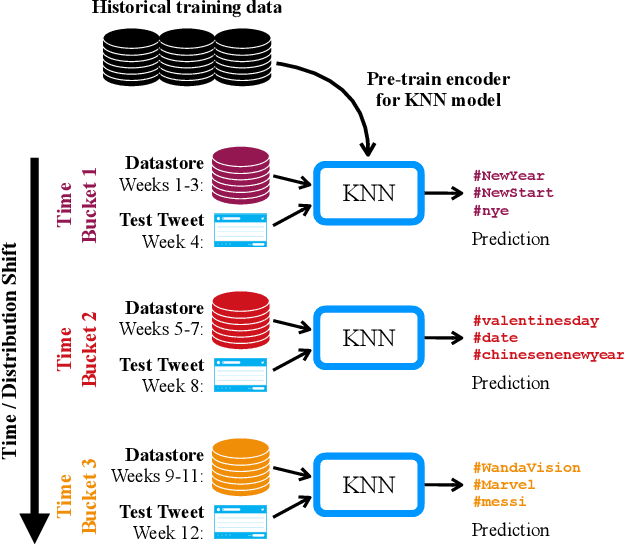
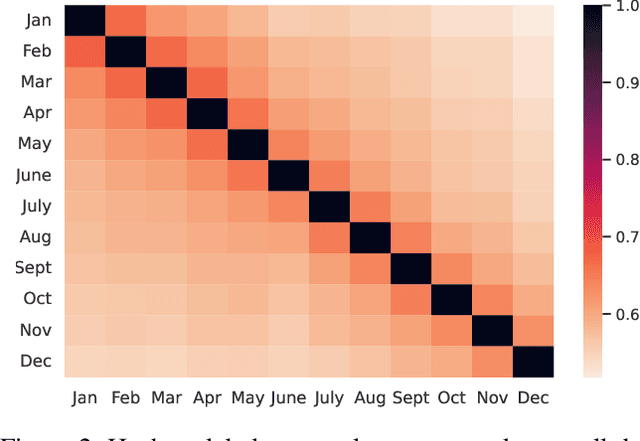
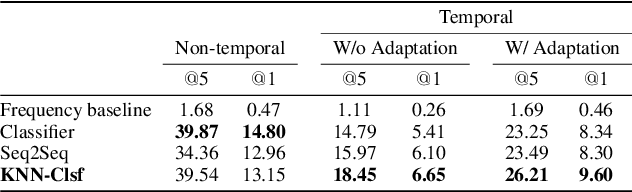
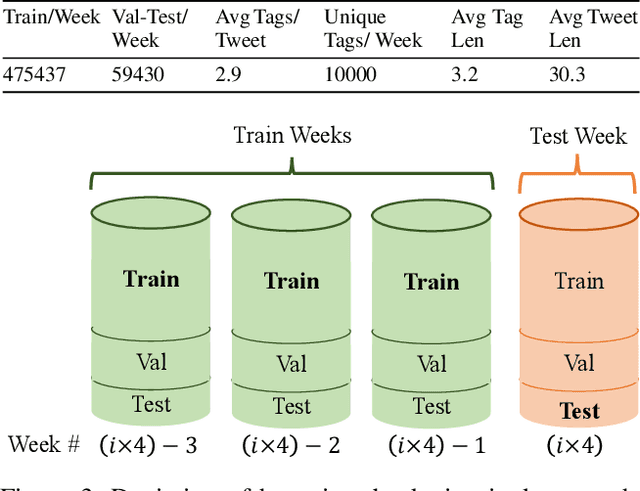
User-generated social media data is constantly changing as new trends influence online discussion, causing distribution shift in test data for social media NLP applications. In addition, training data is often subject to change as user data is deleted. Most current NLP systems are static and rely on fixed training data. As a result, they are unable to adapt to temporal change -- both test distribution shift and deleted training data -- without frequent, costly re-training. In this paper, we study temporal adaptation through the task of longitudinal hashtag prediction and propose a non-parametric technique as a simple but effective solution: non-parametric classifiers use datastores which can be updated, either to adapt to test distribution shift or training data deletion, without re-training. We release a new benchmark dataset comprised of 7.13M Tweets from 2021, along with their hashtags, broken into consecutive temporal buckets. We compare parametric neural hashtag classification and hashtag generation models, which need re-training for adaptation, with a non-parametric, training-free dense retrieval method that returns the nearest neighbor's hashtags based on text embedding distance. In experiments on our longitudinal Twitter dataset we find that dense nearest neighbor retrieval has a relative performance gain of 64.12% over the best parametric baseline on test sets that exhibit distribution shift without requiring gradient-based re-training. Furthermore, we show that our datastore approach is particularly well-suited to dynamically deleted user data, with negligible computational cost and performance loss. Our novel benchmark dataset and empirical analysis can support future inquiry into the important challenges presented by temporality in the deployment of AI systems on real-world user data.
kNN-Embed: Locally Smoothed Embedding Mixtures For Multi-interest Candidate Retrieval
May 13, 2022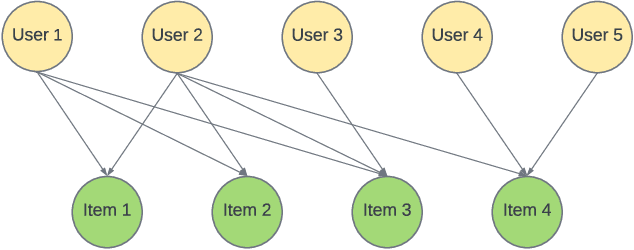

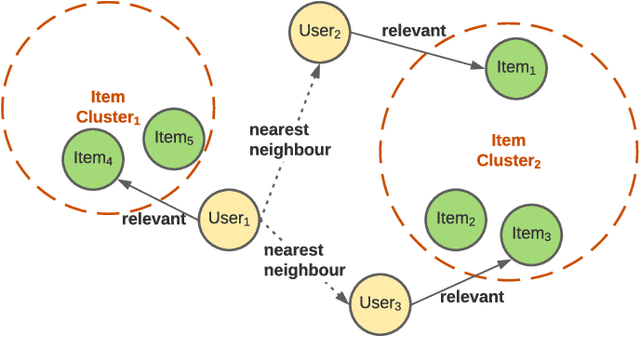
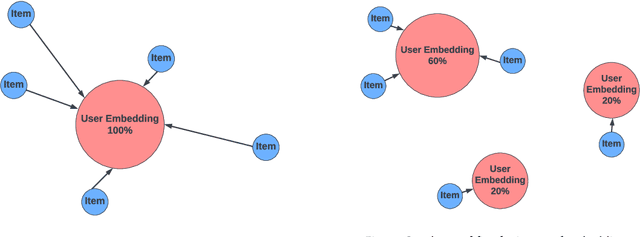
Candidate generation is the first stage in recommendation systems, where a light-weight system is used to retrieve potentially relevant items for an input user. These candidate items are then ranked and pruned in later stages of recommender systems using a more complex ranking model. Since candidate generation is the top of the recommendation funnel, it is important to retrieve a high-recall candidate set to feed into downstream ranking models. A common approach for candidate generation is to leverage approximate nearest neighbor (ANN) search from a single dense query embedding; however, this approach this can yield a low-diversity result set with many near duplicates. As users often have multiple interests, candidate retrieval should ideally return a diverse set of candidates reflective of the user's multiple interests. To this end, we introduce kNN-Embed, a general approach to improving diversity in dense ANN-based retrieval. kNN-Embed represents each user as a smoothed mixture over learned item clusters that represent distinct `interests' of the user. By querying each of a user's mixture component in proportion to their mixture weights, we retrieve a high-diversity set of candidates reflecting elements from each of a user's interests. We experimentally compare kNN-Embed to standard ANN candidate retrieval, and show significant improvements in overall recall and improved diversity across three datasets. Accompanying this work, we open source a large Twitter follow-graph dataset, to spur further research in graph-mining and representation learning for recommender systems.
Learning Stance Embeddings from Signed Social Graphs
Jan 27, 2022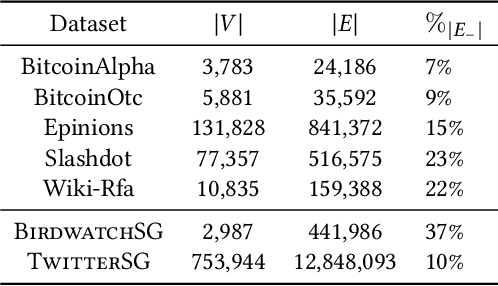
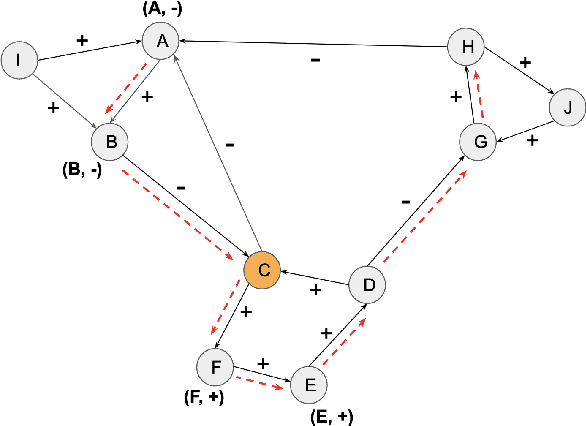
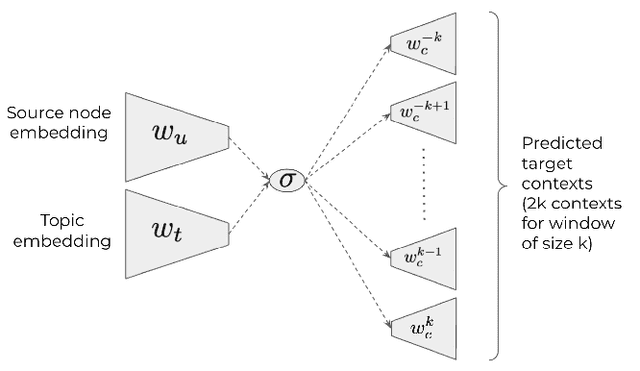
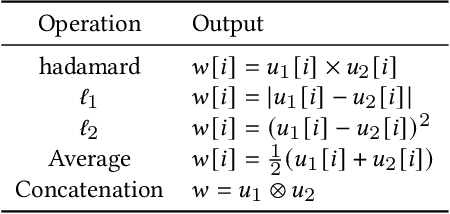
A key challenge in social network analysis is understanding the position, or stance, of people in the graph on a large set of topics. While past work has modeled (dis)agreement in social networks using signed graphs, these approaches have not modeled agreement patterns across a range of correlated topics. For instance, disagreement on one topic may make disagreement(or agreement) more likely for related topics. We propose the Stance Embeddings Model(SEM), which jointly learns embeddings for each user and topic in signed social graphs with distinct edge types for each topic. By jointly learning user and topic embeddings, SEM is able to perform cold-start topic stance detection, predicting the stance of a user on topics for which we have not observed their engagement. We demonstrate the effectiveness of SEM using two large-scale Twitter signed graph datasets we open-source. One dataset, TwitterSG, labels (dis)agreements using engagements between users via tweets to derive topic-informed, signed edges. The other, BirdwatchSG, leverages community reports on misinformation and misleading content. On TwitterSG and BirdwatchSG, SEM shows a 39% and 26% error reduction respectively against strong baselines.
Classification-based Quality Estimation: Small and Efficient Models for Real-world Applications
Sep 17, 2021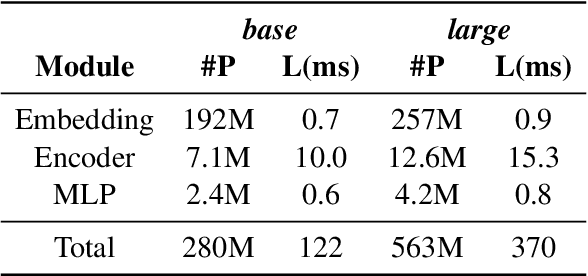
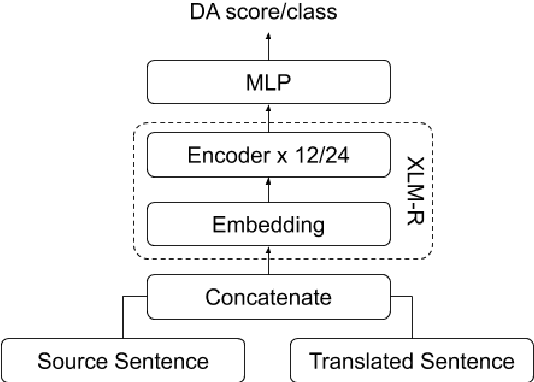
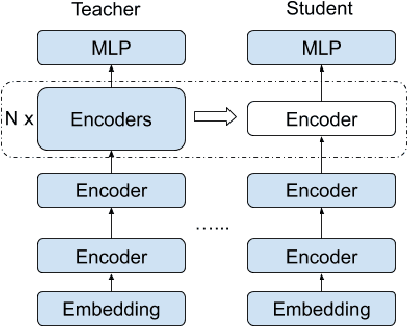
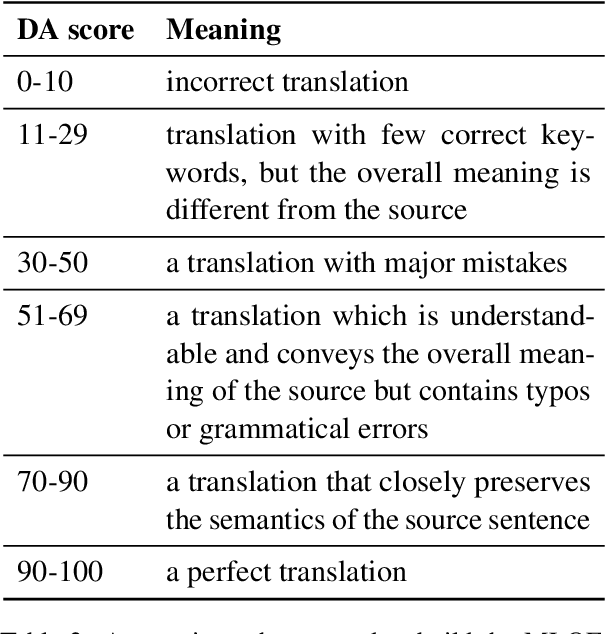
Sentence-level Quality estimation (QE) of machine translation is traditionally formulated as a regression task, and the performance of QE models is typically measured by Pearson correlation with human labels. Recent QE models have achieved previously-unseen levels of correlation with human judgments, but they rely on large multilingual contextualized language models that are computationally expensive and make them infeasible for real-world applications. In this work, we evaluate several model compression techniques for QE and find that, despite their popularity in other NLP tasks, they lead to poor performance in this regression setting. We observe that a full model parameterization is required to achieve SoTA results in a regression task. However, we argue that the level of expressiveness of a model in a continuous range is unnecessary given the downstream applications of QE, and show that reframing QE as a classification problem and evaluating QE models using classification metrics would better reflect their actual performance in real-world applications.