 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Parametric Temporal Adaptation for Social Media Topic Classification
Paper and Code
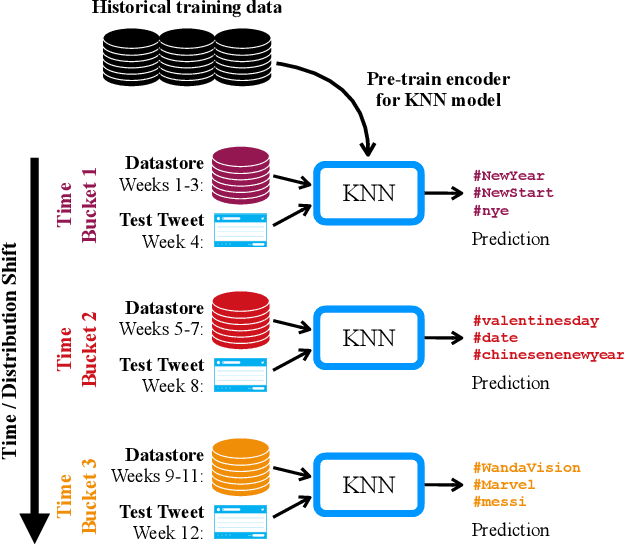
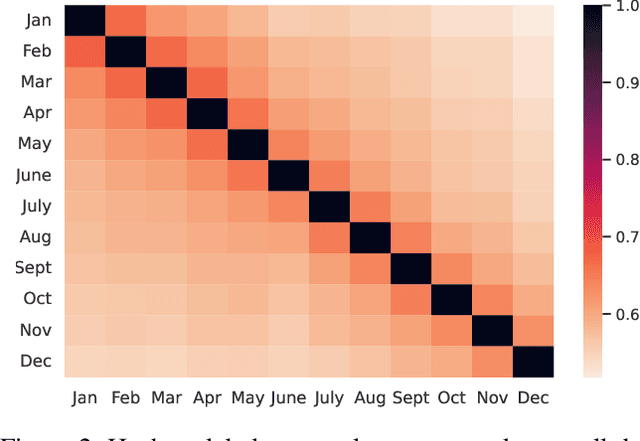
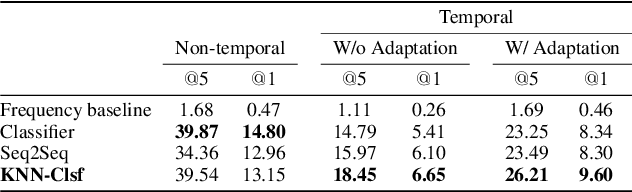
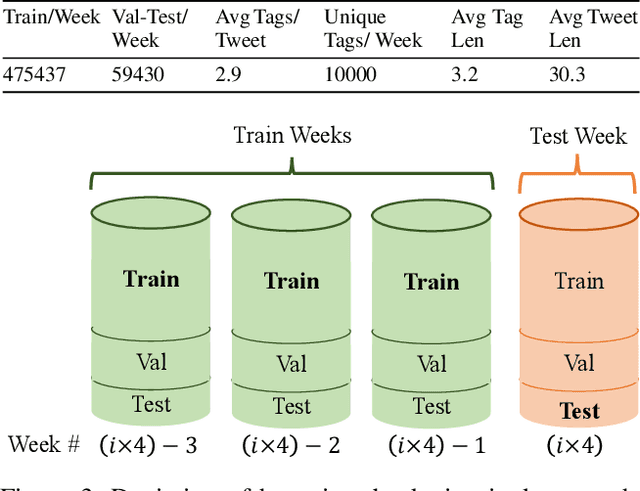
User-generated social media data is constantly changing as new trends influence online discussion, causing distribution shift in test data for social media NLP applications. In addition, training data is often subject to change as user data is deleted. Most current NLP systems are static and rely on fixed training data. As a result, they are unable to adapt to temporal change -- both test distribution shift and deleted training data -- without frequent, costly re-training. In this paper, we study temporal adaptation through the task of longitudinal hashtag prediction and propose a non-parametric technique as a simple but effective solution: non-parametric classifiers use datastores which can be updated, either to adapt to test distribution shift or training data deletion, without re-training. We release a new benchmark dataset comprised of 7.13M Tweets from 2021, along with their hashtags, broken into consecutive temporal buckets. We compare parametric neural hashtag classification and hashtag generation models, which need re-training for adaptation, with a non-parametric, training-free dense retrieval method that returns the nearest neighbor's hashtags based on text embedding distance. In experiments on our longitudinal Twitter dataset we find that dense nearest neighbor retrieval has a relative performance gain of 64.12% over the best parametric baseline on test sets that exhibit distribution shift without requiring gradient-based re-training. Furthermore, we show that our datastore approach is particularly well-suited to dynamically deleted user data, with negligible computational cost and performance loss. Our novel benchmark dataset and empirical analysis can support future inquiry into the important challenges presented by temporality in the deployment of AI systems on real-world user data.