 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
Sparse Distillation: Speeding Up Text Classification by Using Bigger Models
Oct 16, 2021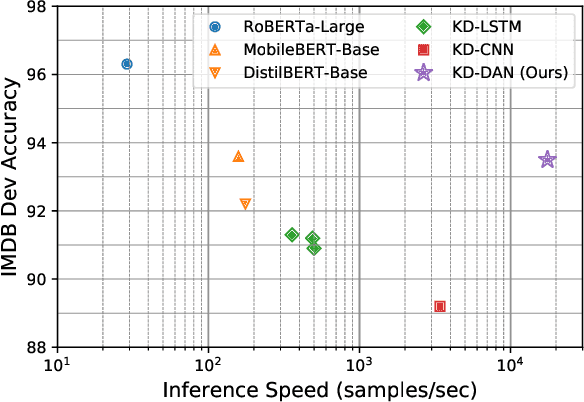
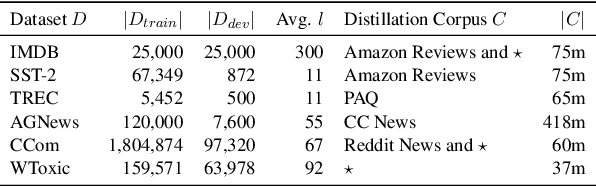
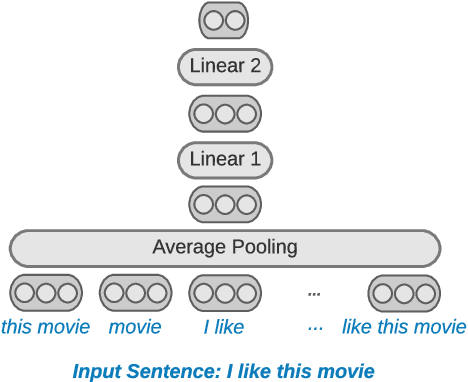
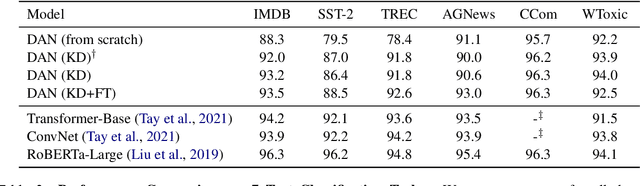
Distilling state-of-the-art transformer models into lightweight student models is an effective way to reduce computation cost at inference time. However, the improved inference speed may be still unsatisfactory for certain time-sensitive applications. In this paper, we aim to further push the limit of inference speed by exploring a new area in the design space of the student model. More specifically, we consider distilling a transformer-based text classifier into a billion-parameter, sparsely-activated student model with a embedding-averaging architecture. Our experiments show that the student models retain 97% of the RoBERTa-Large teacher performance on a collection of six text classification tasks. Meanwhile, the student model achieves up to 600x speed-up on both GPUs and CPUs, compared to the teacher models. Further investigation shows that our pipeline is also effective in privacy-preserving and domain generalization settings.
Autoregressive Modeling is Misspecified for Some Sequence Distributions
Oct 22, 2020
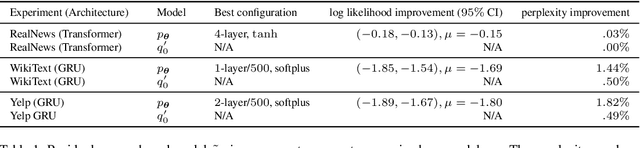
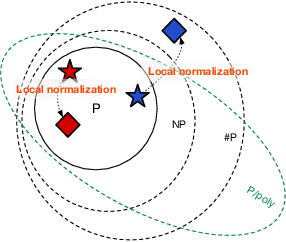
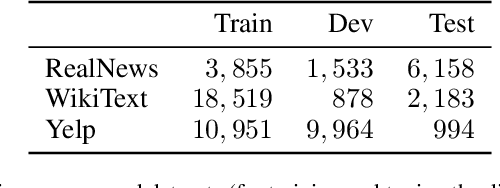
Should sequences be modeled autoregressively---one symbol at a time? How much computation is needed to predict the next symbol? While local normalization is cheap, this also limits its power. We point out that some probability distributions over discrete sequences cannot be well-approximated by any autoregressive model whose runtime and parameter size grow polynomially in the sequence length---even though their unnormalized sequence probabilities are efficient to compute exactly. Intuitively, the probability of the next symbol can be expensive to compute or approximate (even via randomized algorithms) when it marginalizes over exponentially many possible futures, which is in general $\mathrm{NP}$-hard. Our result is conditional on the widely believed hypothesis that $\mathrm{NP} \nsubseteq \mathrm{P/poly}$ (without which the polynomial hierarchy would collapse at the second level). This theoretical observation serves as a caution to the viewpoint that pumping up parameter size is a straightforward way to improve autoregressive models (e.g., in language modeling). It also suggests that globally normalized (energy-based) models may sometimes outperform locally normalized (autoregressive) models, as we demonstrate experimentally for language modeling.
Real-Time Prediction of the Duration of Distribution System Outages
Jul 30, 2018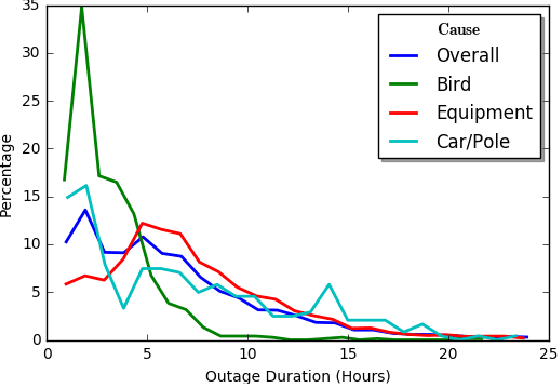
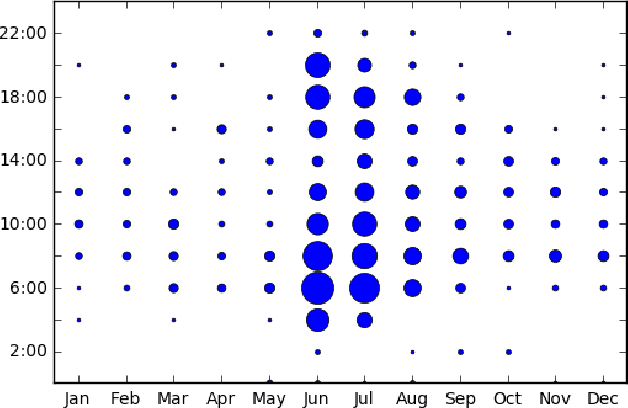
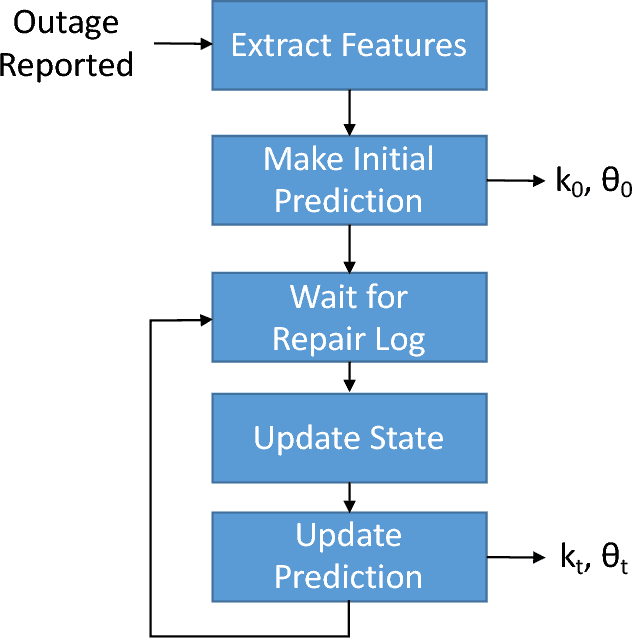
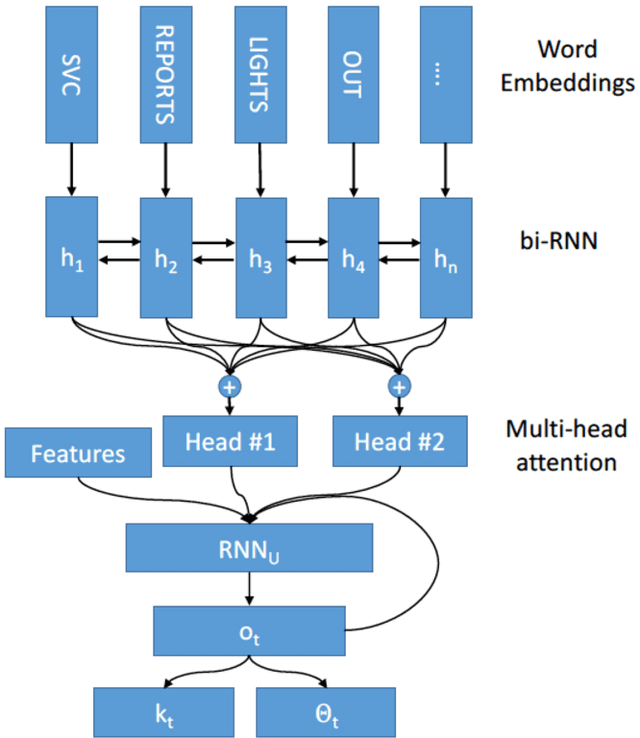
This paper addresses the problem of predicting duration of unplanned power outages, using historical outage records to train a series of neural network predictors. The initial duration prediction is made based on environmental factors, and it is updated based on incoming field reports using natural language processing to automatically analyze the text. Experiments using 15 years of outage records show good initial results and improved performance leveraging text. Case studies show that the language processing identifies phrases that point to outage causes and repair steps.
Low-Rank RNN Adaptation for Context-Aware Language Modeling
May 04, 2018A context-aware language model uses location, user and/or domain metadata (context) to adapt its predictions. In neural language models, context information is typically represented as an embedding and it is given to the RNN as an additional input, which has been shown to be useful in many applications. We introduce a more powerful mechanism for using context to adapt an RNN by letting the context vector control a low-rank transformation of the recurrent layer weight matrix. Experiments show that allowing a greater fraction of the model parameters to be adjusted has benefits in terms of perplexity and classification for several different types of context.
Personalized Language Model for Query Auto-Completion
Apr 25, 2018
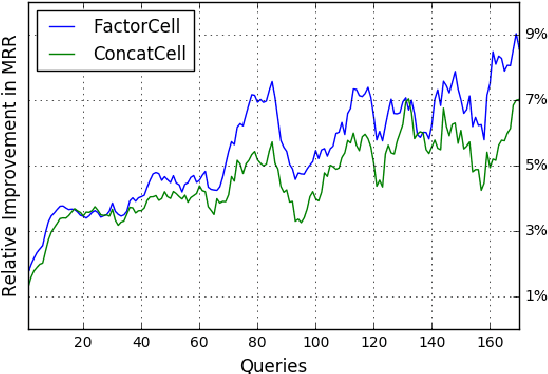
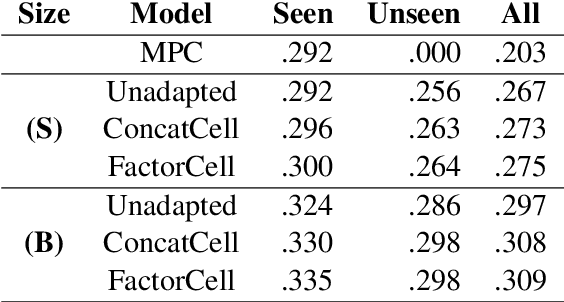
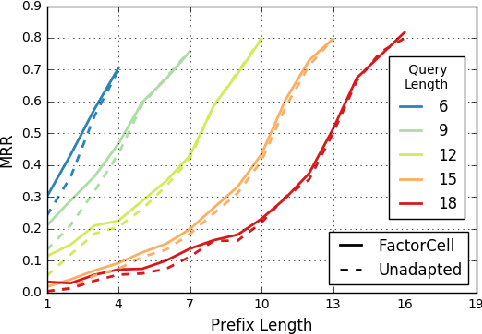
Query auto-completion is a search engine feature whereby the system suggests completed queries as the user types. Recently, the use of a recurrent neural network language model was suggested as a method of generating query completions. We show how an adaptable language model can be used to generate personalized completions and how the model can use online updating to make predictions for users not seen during training. The personalized predictions are significantly better than a baseline that uses no user information.
Community Member Retrieval on Social Media using Textual Information
Apr 16, 2018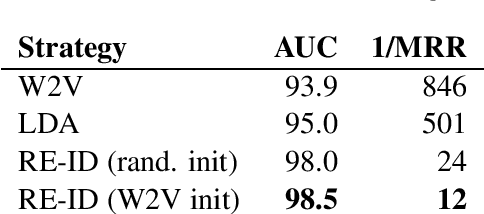
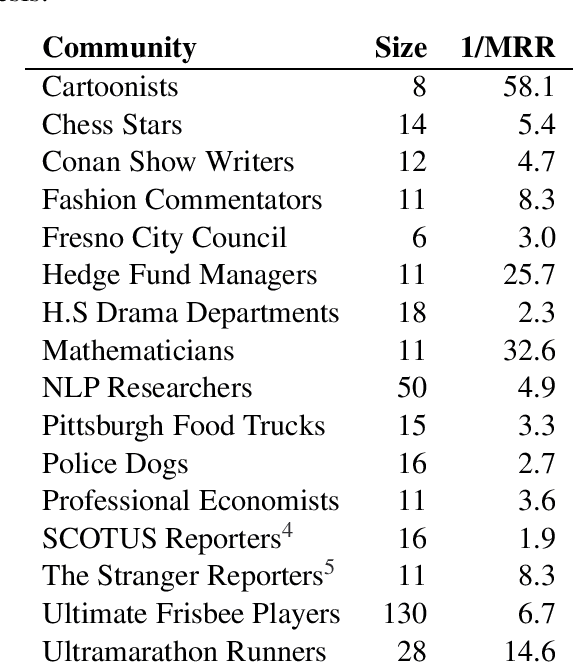

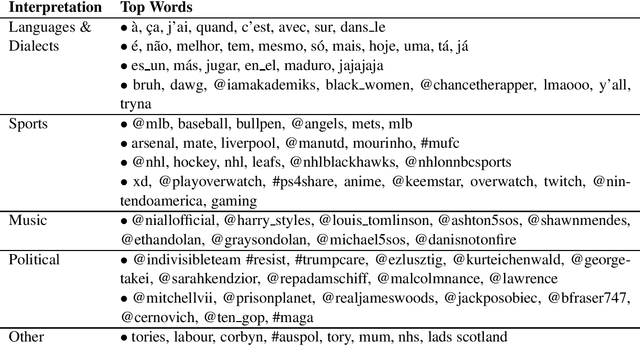
This paper addresses the problem of community membership detection using only text features in a scenario where a small number of positive labeled examples defines the community. The solution introduces an unsupervised proxy task for learning user embeddings: user re-identification. Experiments with 16 different communities show that the resulting embeddings are more effective for community membership identification than common unsupervised representations.
Improving Context Aware Language Models
Apr 21, 2017



Increased adaptability of RNN language models leads to improved predictions that benefit many applications. However, current methods do not take full advantage of the RNN structure. We show that the most widely-used approach to adaptation (concatenating the context with the word embedding at the input to the recurrent layer) is outperformed by a model that has some low-cost improvements: adaptation of both the hidden and output layers. and a feature hashing bias term to capture context idiosyncrasies. Experiments on language modeling and classification tasks using three different corpora demonstrate the advantages of the proposed techniques.
Match-Tensor: a Deep Relevance Model for Search
Jan 26, 2017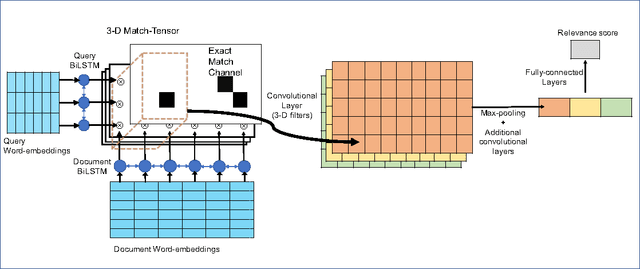
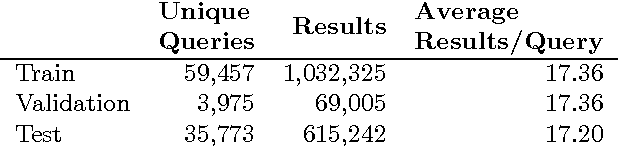
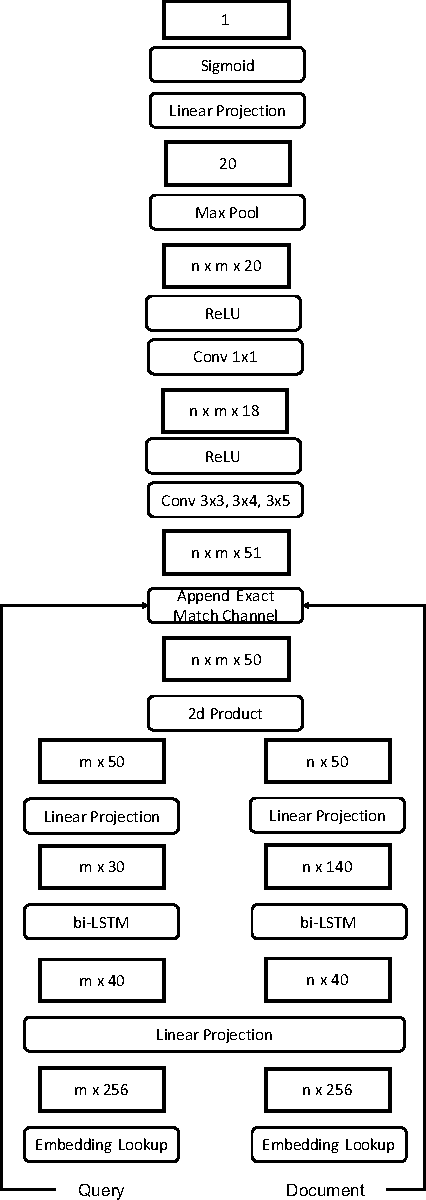
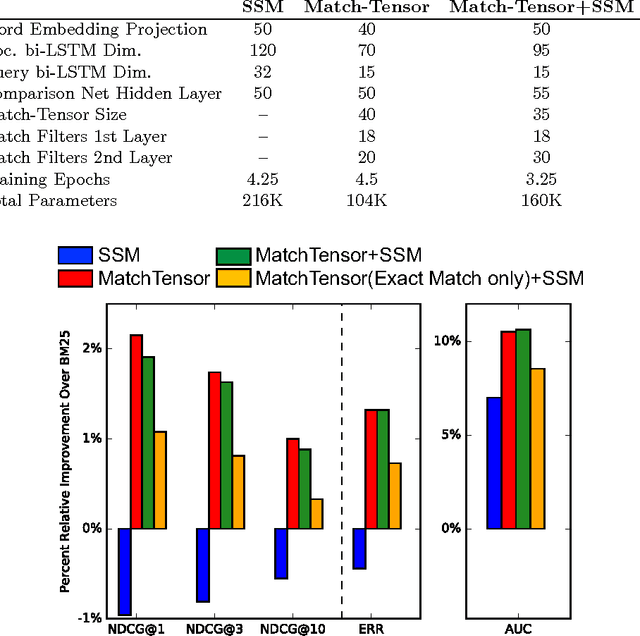
The application of Deep Neural Networks for ranking in search engines may obviate the need for the extensive feature engineering common to current learning-to-rank methods. However, we show that combining simple relevance matching features like BM25 with existing Deep Neural Net models often substantially improves the accuracy of these models, indicating that they do not capture essential local relevance matching signals. We describe a novel deep Recurrent Neural Net-based model that we call Match-Tensor. The architecture of the Match-Tensor model simultaneously accounts for both local relevance matching and global topicality signals allowing for a rich interplay between them when computing the relevance of a document to a query. On a large held-out test set consisting of social media documents, we demonstrate not only that Match-Tensor outperforms BM25 and other classes of DNNs but also that it largely subsumes signals present in these models.
Hierarchical Character-Word Models for Language Identification
Aug 10, 2016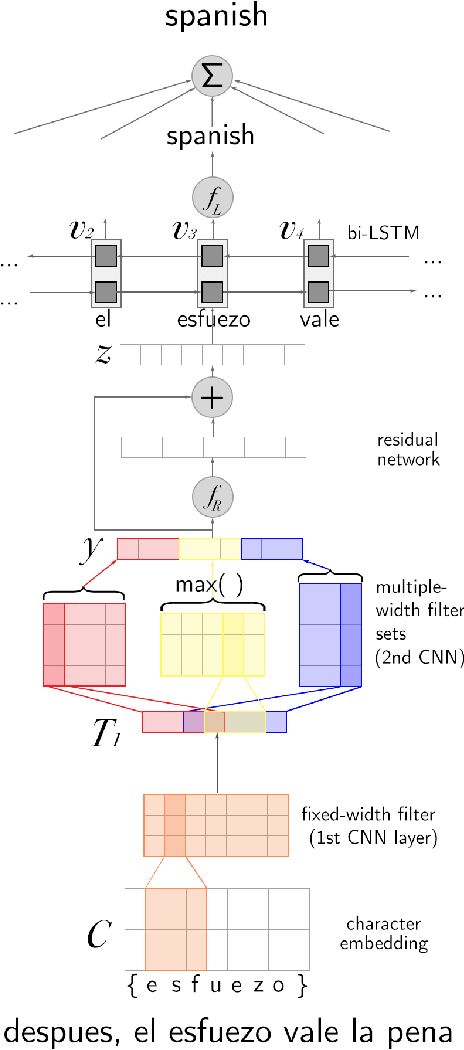
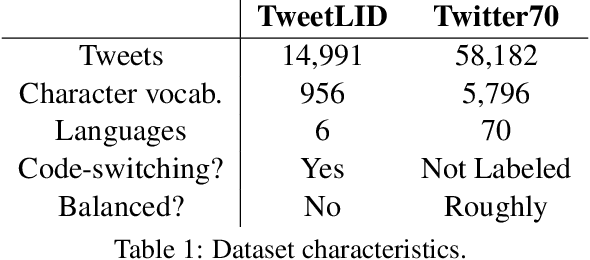
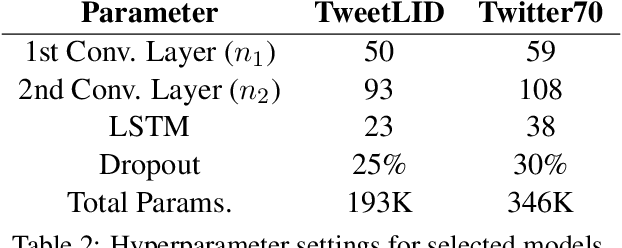
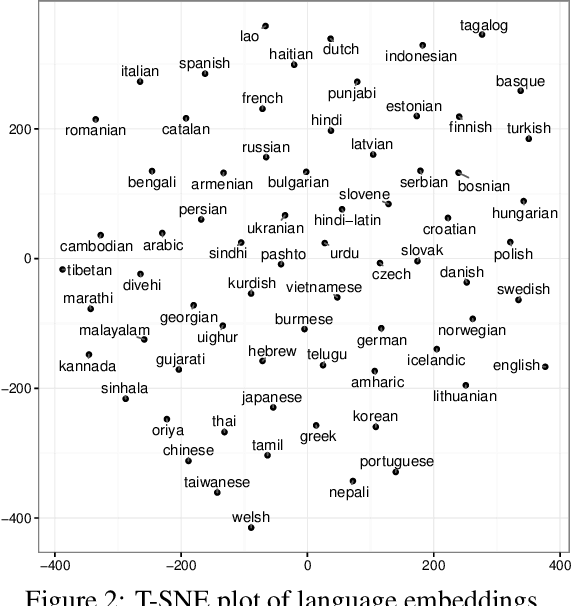
Social media messages' brevity and unconventional spelling pose a challenge to language identification. We introduce a hierarchical model that learns character and contextualized word-level representations for language identification. Our method performs well against strong base- lines, and can also reveal code-switching.