Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Context Aware Language Models
Paper and Code
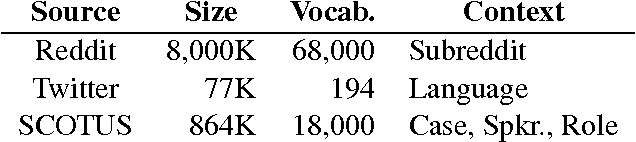



Increased adaptability of RNN language models leads to improved predictions that benefit many applications. However, current methods do not take full advantage of the RNN structure. We show that the most widely-used approach to adaptation (concatenating the context with the word embedding at the input to the recurrent layer) is outperformed by a model that has some low-cost improvements: adaptation of both the hidden and output layers. and a feature hashing bias term to capture context idiosyncrasies. Experiments on language modeling and classification tasks using three different corpora demonstrate the advantages of the proposed techniques.
View paper on