 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs Know More About Numbers than They Can Say
Feb 08, 2026Although state-of-the-art LLMs can solve math problems, we find that they make errors on numerical comparisons with mixed notation: "Which is larger, $5.7 \times 10^2$ or $580$?" This raises a fundamental question: Do LLMs even know how big these numbers are? We probe the hidden states of several smaller open-source LLMs. A single linear projection of an appropriate hidden layer encodes the log-magnitudes of both kinds of numerals, allowing us to recover the numbers with relative error of about 2.3% (on restricted synthetic text) or 19.06% (on scientific papers). Furthermore, the hidden state after reading a pair of numerals encodes their ranking, with a linear classifier achieving over 90% accuracy. Yet surprisingly, when explicitly asked to rank the same pairs of numerals, these LLMs achieve only 50-70% accuracy, with worse performance for models whose probes are less effective. Finally, we show that incorporating the classifier probe's log-loss as an auxiliary objective during finetuning brings an additional 3.22% improvement in verbalized accuracy over base models, demonstrating that improving models' internal magnitude representations can enhance their numerical reasoning capabilities.
Fine-Tuning LLMs with Fine-Grained Human Feedback on Text Spans
Dec 29, 2025We present a method and dataset for fine-tuning language models with preference supervision using feedback-driven improvement chains. Given a model response, an annotator provides fine-grained feedback by marking ``liked'' and ``disliked'' spans and specifying what they liked or disliked about them. The base model then rewrites the disliked spans accordingly, proceeding from left to right, forming a sequence of incremental improvements. We construct preference pairs for direct alignment from each adjacent step in the chain, enabling the model to learn from localized, targeted edits. We find that our approach outperforms direct alignment methods based on standard A/B preference ranking or full contrastive rewrites, demonstrating that structured, revision-based supervision leads to more efficient and effective preference tuning.
Accelerating Language Model Workflows with Prompt Choreography
Dec 28, 2025Large language models are increasingly deployed in multi-agent workflows. We introduce Prompt Choreography, a framework that efficiently executes LLM workflows by maintaining a dynamic, global KV cache. Each LLM call can attend to an arbitrary, reordered subset of previously encoded messages. Parallel calls are supported. Though caching messages' encodings sometimes gives different results from re-encoding them in a new context, we show in diverse settings that fine-tuning the LLM to work with the cache can help it mimic the original results. Prompt Choreography significantly reduces per-message latency (2.0--6.2$\times$ faster time-to-first-token) and achieves substantial end-to-end speedups ($>$2.2$\times$) in some workflows dominated by redundant computation.
MICE for CATs: Model-Internal Confidence Estimation for Calibrating Agents with Tools
Apr 28, 2025



Tool-using agents that act in the world need to be both useful and safe. Well-calibrated model confidences can be used to weigh the risk versus reward of potential actions, but prior work shows that many models are poorly calibrated. Inspired by interpretability literature exploring the internals of models, we propose a novel class of model-internal confidence estimators (MICE) to better assess confidence when calling tools. MICE first decodes from each intermediate layer of the language model using logitLens and then computes similarity scores between each layer's generation and the final output. These features are fed into a learned probabilistic classifier to assess confidence in the decoded output. On the simulated trial and error (STE) tool-calling dataset using Llama3 models, we find that MICE beats or matches the baselines on smoothed expected calibration error. Using MICE confidences to determine whether to call a tool significantly improves over strong baselines on a new metric, expected tool-calling utility. Further experiments show that MICE is sample-efficient, can generalize zero-shot to unseen APIs, and results in higher tool-calling utility in scenarios with varying risk levels. Our code is open source, available at https://github.com/microsoft/mice_for_cats.
Syntactic and Semantic Control of Large Language Models via Sequential Monte Carlo
Apr 18, 2025



A wide range of LM applications require generating text that conforms to syntactic or semantic constraints. Imposing such constraints can be naturally framed as probabilistic conditioning, but exact generation from the resulting distribution -- which can differ substantially from the LM's base distribution -- is generally intractable. In this work, we develop an architecture for controlled LM generation based on sequential Monte Carlo (SMC). Our SMC framework allows us to flexibly incorporate domain- and problem-specific constraints at inference time, and efficiently reallocate computational resources in light of new information during the course of generation. By comparing to a number of alternatives and ablations on four challenging domains -- Python code generation for data science, text-to-SQL, goal inference, and molecule synthesis -- we demonstrate that, with little overhead, our approach allows small open-source language models to outperform models over 8x larger, as well as closed-source, fine-tuned ones. In support of the probabilistic perspective, we show that these performance improvements are driven by better approximation to the posterior distribution. Our system builds on the framework of Lew et al. (2023) and integrates with its language model probabilistic programming language, giving users a simple, programmable way to apply SMC to a broad variety of controlled generation problems.
Fast Controlled Generation from Language Models with Adaptive Weighted Rejection Sampling
Apr 07, 2025The dominant approach to generating from language models subject to some constraint is locally constrained decoding (LCD), incrementally sampling tokens at each time step such that the constraint is never violated. Typically, this is achieved through token masking: looping over the vocabulary and excluding non-conforming tokens. There are two important problems with this approach. (i) Evaluating the constraint on every token can be prohibitively expensive -- LM vocabularies often exceed $100,000$ tokens. (ii) LCD can distort the global distribution over strings, sampling tokens based only on local information, even if they lead down dead-end paths. This work introduces a new algorithm that addresses both these problems. First, to avoid evaluating a constraint on the full vocabulary at each step of generation, we propose an adaptive rejection sampling algorithm that typically requires orders of magnitude fewer constraint evaluations. Second, we show how this algorithm can be extended to produce low-variance, unbiased estimates of importance weights at a very small additional cost -- estimates that can be soundly used within previously proposed sequential Monte Carlo algorithms to correct for the myopic behavior of local constraint enforcement. Through extensive empirical evaluation in text-to-SQL, molecular synthesis, goal inference, pattern matching, and JSON domains, we show that our approach is superior to state-of-the-art baselines, supporting a broader class of constraints and improving both runtime and performance. Additional theoretical and empirical analyses show that our method's runtime efficiency is driven by its dynamic use of computation, scaling with the divergence between the unconstrained and constrained LM, and as a consequence, runtime improvements are greater for better models.
LLM-Rubric: A Multidimensional, Calibrated Approach to Automated Evaluation of Natural Language Texts
Dec 31, 2024This paper introduces a framework for the automated evaluation of natural language texts. A manually constructed rubric describes how to assess multiple dimensions of interest. To evaluate a text, a large language model (LLM) is prompted with each rubric question and produces a distribution over potential responses. The LLM predictions often fail to agree well with human judges -- indeed, the humans do not fully agree with one another. However, the multiple LLM distributions can be $\textit{combined}$ to $\textit{predict}$ each human judge's annotations on all questions, including a summary question that assesses overall quality or relevance. LLM-Rubric accomplishes this by training a small feed-forward neural network that includes both judge-specific and judge-independent parameters. When evaluating dialogue systems in a human-AI information-seeking task, we find that LLM-Rubric with 9 questions (assessing dimensions such as naturalness, conciseness, and citation quality) predicts human judges' assessment of overall user satisfaction, on a scale of 1--4, with RMS error $< 0.5$, a $2\times$ improvement over the uncalibrated baseline.
* Updated version of 17 June 2024
Let's Think Var-by-Var: Large Language Models Enable Ad Hoc Probabilistic Reasoning
Dec 03, 2024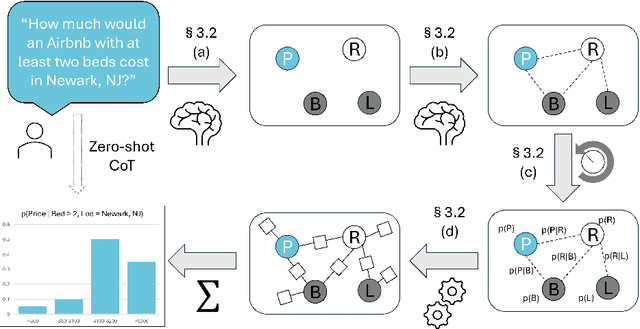

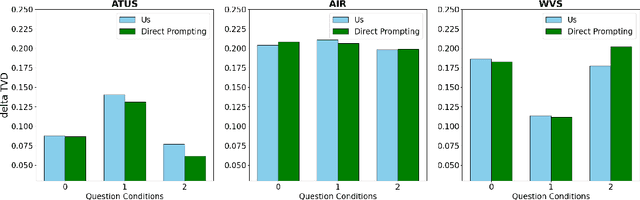

A hallmark of intelligence is the ability to flesh out underspecified situations using "common sense." We propose to extract that common sense from large language models (LLMs), in a form that can feed into probabilistic inference. We focus our investigation on $\textit{guesstimation}$ questions such as "How much are Airbnb listings in Newark, NJ?" Formulating a sensible answer without access to data requires drawing on, and integrating, bits of common knowledge about how $\texttt{Price}$ and $\texttt{Location}$ may relate to other variables, such as $\texttt{Property Type}$. Our framework answers such a question by synthesizing an $\textit{ad hoc}$ probabilistic model. First we prompt an LLM to propose a set of random variables relevant to the question, followed by moment constraints on their joint distribution. We then optimize the joint distribution $p$ within a log-linear family to maximize the overall constraint satisfaction. Our experiments show that LLMs can successfully be prompted to propose reasonable variables, and while the proposed numerical constraints can be noisy, jointly optimizing for their satisfaction reconciles them. When evaluated on probabilistic questions derived from three real-world tabular datasets, we find that our framework performs comparably to a direct prompting baseline in terms of total variation distance from the dataset distribution, and is similarly robust to noise.
Learning to Retrieve Iteratively for In-Context Learning
Jun 20, 2024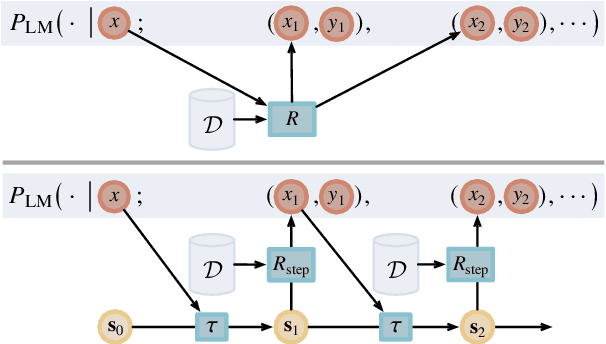
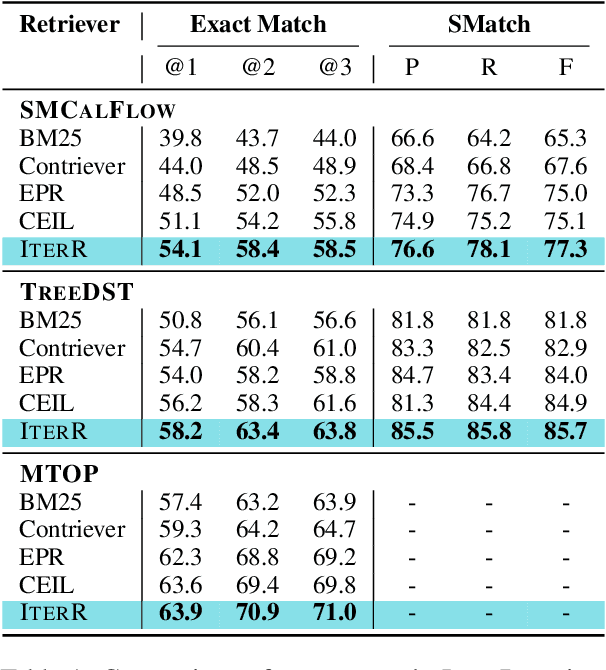
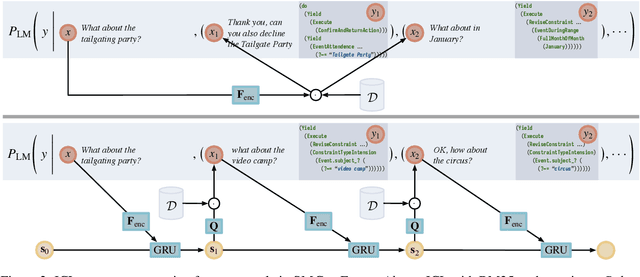
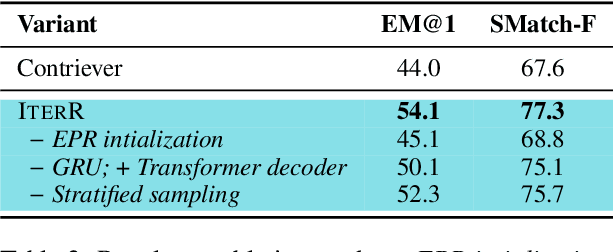
We introduce iterative retrieval, a novel framework that empowers retrievers to make iterative decisions through policy optimization. Finding an optimal portfolio of retrieved items is a combinatorial optimization problem, generally considered NP-hard. This approach provides a learned approximation to such a solution, meeting specific task requirements under a given family of large language models (LLMs). We propose a training procedure based on reinforcement learning, incorporating feedback from LLMs. We instantiate an iterative retriever for composing in-context learning (ICL) exemplars and apply it to various semantic parsing tasks that demand synthesized programs as outputs. By adding only 4M additional parameters for state encoding, we convert an off-the-shelf dense retriever into a stateful iterative retriever, outperforming previous methods in selecting ICL exemplars on semantic parsing datasets such as CalFlow, TreeDST, and MTOP. Additionally, the trained iterative retriever generalizes across different inference LLMs beyond the one used during training.
LLMs in the Imaginarium: Tool Learning through Simulated Trial and Error
Mar 07, 2024

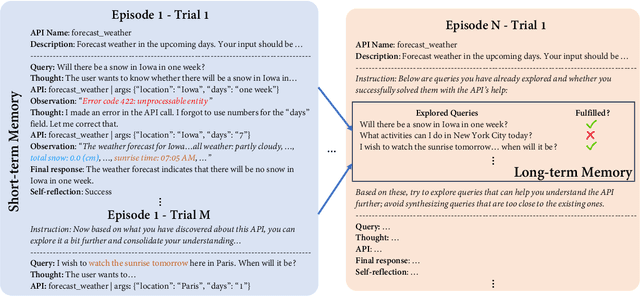

Tools are essential for large language models (LLMs) to acquire up-to-date information and take consequential actions in external environments. Existing work on tool-augmented LLMs primarily focuses on the broad coverage of tools and the flexibility of adding new tools. However, a critical aspect that has surprisingly been understudied is simply how accurately an LLM uses tools for which it has been trained. We find that existing LLMs, including GPT-4 and open-source LLMs specifically fine-tuned for tool use, only reach a correctness rate in the range of 30% to 60%, far from reliable use in practice. We propose a biologically inspired method for tool-augmented LLMs, simulated trial and error (STE), that orchestrates three key mechanisms for successful tool use behaviors in the biological system: trial and error, imagination, and memory. Specifically, STE leverages an LLM's 'imagination' to simulate plausible scenarios for using a tool, after which the LLM interacts with the tool to learn from its execution feedback. Both short-term and long-term memory are employed to improve the depth and breadth of the exploration, respectively. Comprehensive experiments on ToolBench show that STE substantially improves tool learning for LLMs under both in-context learning and fine-tuning settings, bringing a boost of 46.7% to Mistral-Instruct-7B and enabling it to outperform GPT-4. We also show effective continual learning of tools via a simple experience replay strategy.