 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyntactic and Semantic Control of Large Language Models via Sequential Monte Carlo
Apr 18, 2025



A wide range of LM applications require generating text that conforms to syntactic or semantic constraints. Imposing such constraints can be naturally framed as probabilistic conditioning, but exact generation from the resulting distribution -- which can differ substantially from the LM's base distribution -- is generally intractable. In this work, we develop an architecture for controlled LM generation based on sequential Monte Carlo (SMC). Our SMC framework allows us to flexibly incorporate domain- and problem-specific constraints at inference time, and efficiently reallocate computational resources in light of new information during the course of generation. By comparing to a number of alternatives and ablations on four challenging domains -- Python code generation for data science, text-to-SQL, goal inference, and molecule synthesis -- we demonstrate that, with little overhead, our approach allows small open-source language models to outperform models over 8x larger, as well as closed-source, fine-tuned ones. In support of the probabilistic perspective, we show that these performance improvements are driven by better approximation to the posterior distribution. Our system builds on the framework of Lew et al. (2023) and integrates with its language model probabilistic programming language, giving users a simple, programmable way to apply SMC to a broad variety of controlled generation problems.
Models Can and Should Embrace the Communicative Nature of Human-Generated Math
Sep 25, 2024
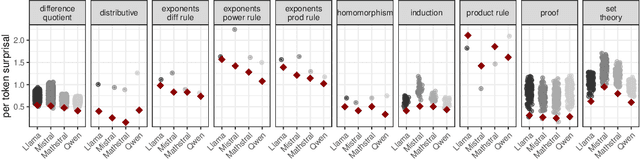
Math is constructed by people for people: just as natural language corpora reflect not just propositions but the communicative goals of language users, the math data that models are trained on reflects not just idealized mathematical entities but rich communicative intentions. While there are important advantages to treating math in a purely symbolic manner, we here hypothesize that there are benefits to treating math as situated linguistic communication and that language models are well suited for this goal, in ways that are not fully appreciated. We illustrate these points with two case studies. First, we ran an experiment in which we found that language models interpret the equals sign in a humanlike way -- generating systematically different word problems for the same underlying equation arranged in different ways. Second, we found that language models prefer proofs to be ordered in naturalistic ways, even though other orders would be logically equivalent. We advocate for AI systems that learn from and represent the communicative intentions latent in human-generated math.