 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiBLiMP 1.0: A Massively Multilingual Benchmark of Linguistic Minimal Pairs
Apr 03, 2025We introduce MultiBLiMP 1.0, a massively multilingual benchmark of linguistic minimal pairs, covering 101 languages, 6 linguistic phenomena and containing more than 125,000 minimal pairs. Our minimal pairs are created using a fully automated pipeline, leveraging the large-scale linguistic resources of Universal Dependencies and UniMorph. MultiBLiMP 1.0 evaluates abilities of LLMs at an unprecedented multilingual scale, and highlights the shortcomings of the current state-of-the-art in modelling low-resource languages.
Both Direct and Indirect Evidence Contribute to Dative Alternation Preferences in Language Models
Mar 26, 2025



Language models (LMs) tend to show human-like preferences on a number of syntactic phenomena, but the extent to which these are attributable to direct exposure to the phenomena or more general properties of language is unclear. We explore this with the English dative alternation (DO: "gave Y the X" vs. PO: "gave the X to Y"), using a controlled rearing paradigm wherein we iteratively train small LMs on systematically manipulated input. We focus on properties that affect the choice of alternant: length and animacy. Both properties are directly present in datives but also reflect more global tendencies for shorter elements to precede longer ones and animates to precede inanimates. First, by manipulating and ablating datives for these biases in the input, we show that direct evidence of length and animacy matters, but easy-first preferences persist even without such evidence. Then, using LMs trained on systematically perturbed datasets to manipulate global length effects (re-linearizing sentences globally while preserving dependency structure), we find that dative preferences can emerge from indirect evidence. We conclude that LMs' emergent syntactic preferences come from a mix of direct and indirect sources.
Constructions are Revealed in Word Distributions
Mar 08, 2025



Construction grammar posits that constructions (form-meaning pairings) are acquired through experience with language (the distributional learning hypothesis). But how much information about constructions does this distribution actually contain? Corpus-based analyses provide some answers, but text alone cannot answer counterfactual questions about what caused a particular word to occur. For that, we need computable models of the distribution over strings -- namely, pretrained language models (PLMs). Here we treat a RoBERTa model as a proxy for this distribution and hypothesize that constructions will be revealed within it as patterns of statistical affinity. We support this hypothesis experimentally: many constructions are robustly distinguished, including (i) hard cases where semantically distinct constructions are superficially similar, as well as (ii) schematic constructions, whose "slots" can be filled by abstract word classes. Despite this success, we also provide qualitative evidence that statistical affinity alone may be insufficient to identify all constructions from text. Thus, statistical affinity is likely an important, but partial, signal available to learners.
Linguistic Generalizations are not Rules: Impacts on Evaluation of LMs
Feb 18, 2025

Linguistic evaluations of how well LMs generalize to produce or understand novel text often implicitly take for granted that natural languages are generated by symbolic rules. Grammaticality is thought to be determined by whether or not sentences obey such rules. Interpretation is believed to be compositionally generated by syntactic rules operating on meaningful words. Semantic parsing is intended to map sentences into formal logic. Failures of LMs to obey strict rules have been taken to reveal that LMs do not produce or understand language like humans. Here we suggest that LMs' failures to obey symbolic rules may be a feature rather than a bug, because natural languages are not based on rules. New utterances are produced and understood by a combination of flexible interrelated and context-dependent schemata or constructions. We encourage researchers to reimagine appropriate benchmarks and analyses that acknowledge the rich flexible generalizations that comprise natural languages.
Derivational Morphology Reveals Analogical Generalization in Large Language Models
Nov 12, 2024



What mechanisms underlie linguistic generalization in large language models (LLMs)? This question has attracted considerable attention, with most studies analyzing the extent to which the language skills of LLMs resemble rules. As of yet, it is not known whether linguistic generalization in LLMs could equally well be explained as the result of analogical processes, which can be formalized as similarity operations on stored exemplars. A key shortcoming of prior research is its focus on linguistic phenomena with a high degree of regularity, for which rule-based and analogical approaches make the same predictions. Here, we instead examine derivational morphology, specifically English adjective nominalization, which displays notable variability. We introduce a new method for investigating linguistic generalization in LLMs: focusing on GPT-J, we fit cognitive models that instantiate rule-based and analogical learning to the LLM training data and compare their predictions on a set of nonce adjectives with those of the LLM, allowing us to draw direct conclusions regarding underlying mechanisms. As expected, rule-based and analogical models explain the predictions of GPT-J equally well for adjectives with regular nominalization patterns. However, for adjectives with variable nominalization patterns, the analogical model provides a much better match. Furthermore, GPT-J's behavior is sensitive to the individual word frequencies, even for regular forms, a behavior that is consistent with an analogical account of regular forms but not a rule-based one. These findings refute the hypothesis that GPT-J's linguistic generalization on adjective nominalization involves rules, suggesting similarity operations on stored exemplars as the underlying mechanism. Overall, our study suggests that analogical processes play a bigger role in the linguistic generalization of LLMs than previously thought.
Models Can and Should Embrace the Communicative Nature of Human-Generated Math
Sep 25, 2024
Math is constructed by people for people: just as natural language corpora reflect not just propositions but the communicative goals of language users, the math data that models are trained on reflects not just idealized mathematical entities but rich communicative intentions. While there are important advantages to treating math in a purely symbolic manner, we here hypothesize that there are benefits to treating math as situated linguistic communication and that language models are well suited for this goal, in ways that are not fully appreciated. We illustrate these points with two case studies. First, we ran an experiment in which we found that language models interpret the equals sign in a humanlike way -- generating systematically different word problems for the same underlying equation arranged in different ways. Second, we found that language models prefer proofs to be ordered in naturalistic ways, even though other orders would be logically equivalent. We advocate for AI systems that learn from and represent the communicative intentions latent in human-generated math.
SYNTHEVAL: Hybrid Behavioral Testing of NLP Models with Synthetic CheckLists
Aug 30, 2024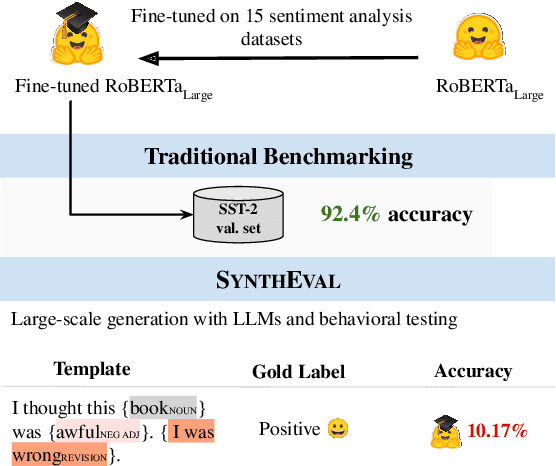

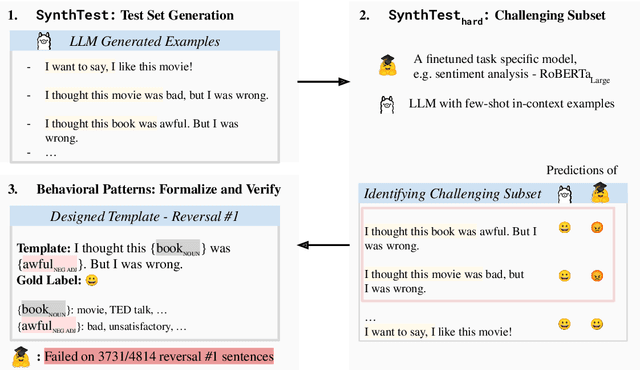

Traditional benchmarking in NLP typically involves using static held-out test sets. However, this approach often results in an overestimation of performance and lacks the ability to offer comprehensive, interpretable, and dynamic assessments of NLP models. Recently, works like DynaBench (Kiela et al., 2021) and CheckList (Ribeiro et al., 2020) have addressed these limitations through behavioral testing of NLP models with test types generated by a multistep human-annotated pipeline. Unfortunately, manually creating a variety of test types requires much human labor, often at prohibitive cost. In this work, we propose SYNTHEVAL, a hybrid behavioral testing framework that leverages large language models (LLMs) to generate a wide range of test types for a comprehensive evaluation of NLP models. SYNTHEVAL first generates sentences via LLMs using controlled generation, and then identifies challenging examples by comparing the predictions made by LLMs with task-specific NLP models. In the last stage, human experts investigate the challenging examples, manually design templates, and identify the types of failures the taskspecific models consistently exhibit. We apply SYNTHEVAL to two classification tasks, sentiment analysis and toxic language detection, and show that our framework is effective in identifying weaknesses of strong models on these tasks. We share our code in https://github.com/Loreley99/SynthEval_CheckList.
UCxn: Typologically Informed Annotation of Constructions Atop Universal Dependencies
Mar 26, 2024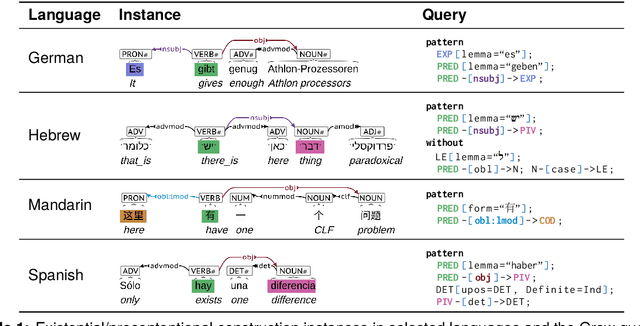
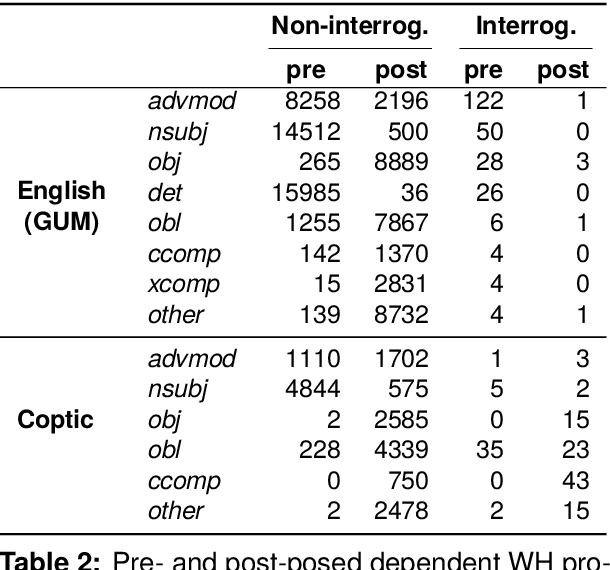
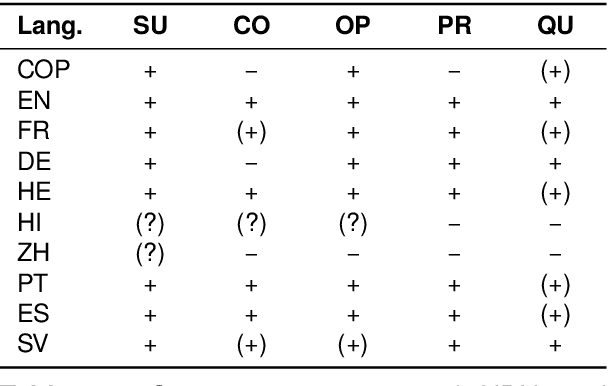
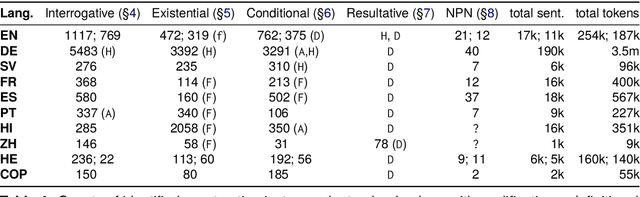
The Universal Dependencies (UD) project has created an invaluable collection of treebanks with contributions in over 140 languages. However, the UD annotations do not tell the full story. Grammatical constructions that convey meaning through a particular combination of several morphosyntactic elements -- for example, interrogative sentences with special markers and/or word orders -- are not labeled holistically. We argue for (i) augmenting UD annotations with a 'UCxn' annotation layer for such meaning-bearing grammatical constructions, and (ii) approaching this in a typologically informed way so that morphosyntactic strategies can be compared across languages. As a case study, we consider five construction families in ten languages, identifying instances of each construction in UD treebanks through the use of morphosyntactic patterns. In addition to findings regarding these particular constructions, our study yields important insights on methodology for describing and identifying constructions in language-general and language-particular ways, and lays the foundation for future constructional enrichment of UD treebanks.
Verbing Weirds Language (Models): Evaluation of English Zero-Derivation in Five LLMs
Mar 26, 2024



Lexical-syntactic flexibility, in the form of conversion (or zero-derivation) is a hallmark of English morphology. In conversion, a word with one part of speech is placed in a non-prototypical context, where it is coerced to behave as if it had a different part of speech. However, while this process affects a large part of the English lexicon, little work has been done to establish the degree to which language models capture this type of generalization. This paper reports the first study on the behavior of large language models with reference to conversion. We design a task for testing lexical-syntactic flexibility -- the degree to which models can generalize over words in a construction with a non-prototypical part of speech. This task is situated within a natural language inference paradigm. We test the abilities of five language models -- two proprietary models (GPT-3.5 and GPT-4), three open-source models (Mistral 7B, Falcon 40B, and Llama 2 70B). We find that GPT-4 performs best on the task, followed by GPT-3.5, but that the open source language models are also able to perform it and that the 7B parameter Mistral displays as little difference between its baseline performance on the natural language inference task and the non-prototypical syntactic category task, as the massive GPT-4.
Constructions Are So Difficult That Even Large Language Models Get Them Right for the Wrong Reasons
Mar 26, 2024
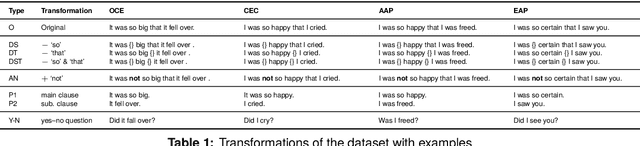
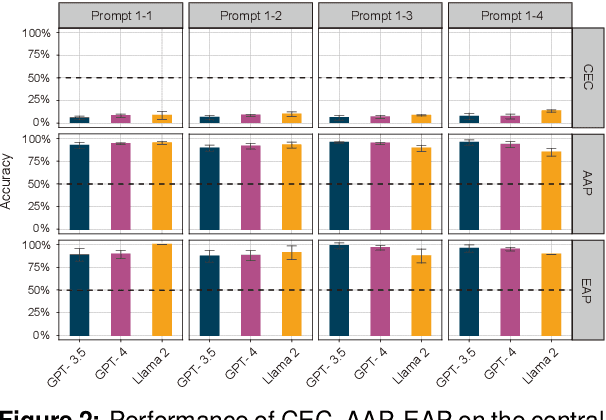
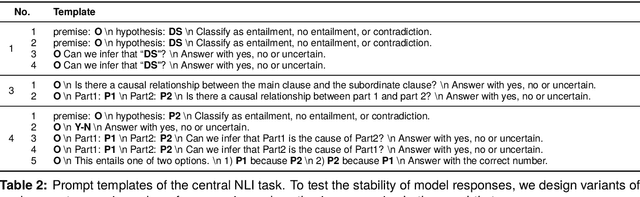
In this paper, we make a contribution that can be understood from two perspectives: from an NLP perspective, we introduce a small challenge dataset for NLI with large lexical overlap, which minimises the possibility of models discerning entailment solely based on token distinctions, and show that GPT-4 and Llama 2 fail it with strong bias. We then create further challenging sub-tasks in an effort to explain this failure. From a Computational Linguistics perspective, we identify a group of constructions with three classes of adjectives which cannot be distinguished by surface features. This enables us to probe for LLM's understanding of these constructions in various ways, and we find that they fail in a variety of ways to distinguish between them, suggesting that they don't adequately represent their meaning or capture the lexical properties of phrasal heads.