 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Reasoning Models Are (Not Yet) Multilingual Latent Reasoners
Jan 06, 2026Large reasoning models (LRMs) achieve strong performance on mathematical reasoning tasks, often attributed to their capability to generate explicit chain-of-thought (CoT) explanations. However, recent work shows that LRMs often arrive at the correct answer before completing these textual reasoning steps, indicating the presence of latent reasoning -- internal, non-verbal computation encoded in hidden states. While this phenomenon has been explored in English, its multilingual behavior remains largely unknown. In this paper, we conduct a systematic investigation of multilingual latent reasoning in LRMs across 11 languages. Using a truncation-based strategy, we examine how the correct answer emerges as the model is given only partial reasoning traces, allowing us to measure stepwise latent prediction formation. Our results reveal clear evidence of multilingual latent reasoning, though unevenly: strong in resource-rich languages, weaker in low-resource ones, and broadly less observable on harder benchmarks. To understand whether these differences reflect distinct internal mechanisms, we further perform representational analyses. Despite surface-level disparities, we find that the internal evolution of predictions is highly consistent across languages and broadly aligns with English -- a pattern suggesting an English-centered latent reasoning pathway.
Evaluating Robustness of Large Language Models Against Multilingual Typographical Errors
Oct 10, 2025Large language models (LLMs) are increasingly deployed in multilingual, real-world applications with user inputs -- naturally introducing typographical errors (typos). Yet most benchmarks assume clean input, leaving the robustness of LLMs to typos across languages largely underexplored. To address this gap, we introduce MulTypo, a multilingual typo generation algorithm that simulates human-like errors based on language-specific keyboard layouts and typing behavior. We evaluate 18 open-source LLMs across three model families and five downstream tasks spanning language inference, multi-choice question answering, mathematical reasoning, and machine translation tasks. Our results show that typos consistently degrade performance, particularly in generative tasks and those requiring reasoning -- while the natural language inference task is comparatively more robust. Instruction tuning improves clean-input performance but may increase brittleness under noise. We also observe language-dependent robustness: high-resource languages are generally more robust than low-resource ones, and translation from English is more robust than translation into English. Our findings underscore the need for noise-aware training and multilingual robustness evaluation. We make our code and data publicly available.
A Comprehensive Evaluation of Multilingual Chain-of-Thought Reasoning: Performance, Consistency, and Faithfulness Across Languages
Oct 10, 2025Large reasoning models (LRMs) increasingly rely on step-by-step Chain-of-Thought (CoT) reasoning to improve task performance, particularly in high-resource languages such as English. While recent work has examined final-answer accuracy in multilingual settings, the thinking traces themselves, i.e., the intermediate steps that lead to the final answer, remain underexplored. In this paper, we present the first comprehensive study of multilingual CoT reasoning, evaluating three key dimensions: performance, consistency, and faithfulness. We begin by measuring language compliance, answer accuracy, and answer consistency when LRMs are explicitly instructed or prompt-hacked to think in a target language, revealing strong language preferences and divergent performance across languages. Next, we assess crosslingual consistency of thinking traces by interchanging them between languages. We find that the quality and effectiveness of thinking traces vary substantially depending on the prompt language. Finally, we adapt perturbation-based techniques -- i.e., truncation and error injection -- to probe the faithfulness of thinking traces across languages, showing that models rely on traces to varying degrees. We release our code and data to support future research.
Do We Know What LLMs Don't Know? A Study of Consistency in Knowledge Probing
May 27, 2025The reliability of large language models (LLMs) is greatly compromised by their tendency to hallucinate, underscoring the need for precise identification of knowledge gaps within LLMs. Various methods for probing such gaps exist, ranging from calibration-based to prompting-based methods. To evaluate these probing methods, in this paper, we propose a new process based on using input variations and quantitative metrics. Through this, we expose two dimensions of inconsistency in knowledge gap probing. (1) Intra-method inconsistency: Minimal non-semantic perturbations in prompts lead to considerable variance in detected knowledge gaps within the same probing method; e.g., the simple variation of shuffling answer options can decrease agreement to around 40%. (2) Cross-method inconsistency: Probing methods contradict each other on whether a model knows the answer. Methods are highly inconsistent -- with decision consistency across methods being as low as 7% -- even though the model, dataset, and prompt are all the same. These findings challenge existing probing methods and highlight the urgent need for perturbation-robust probing frameworks.
MAKIEval: A Multilingual Automatic WiKidata-based Framework for Cultural Awareness Evaluation for LLMs
May 27, 2025Large language models (LLMs) are used globally across many languages, but their English-centric pretraining raises concerns about cross-lingual disparities for cultural awareness, often resulting in biased outputs. However, comprehensive multilingual evaluation remains challenging due to limited benchmarks and questionable translation quality. To better assess these disparities, we introduce MAKIEval, an automatic multilingual framework for evaluating cultural awareness in LLMs across languages, regions, and topics. MAKIEval evaluates open-ended text generation, capturing how models express culturally grounded knowledge in natural language. Leveraging Wikidata's multilingual structure as a cross-lingual anchor, it automatically identifies cultural entities in model outputs and links them to structured knowledge, enabling scalable, language-agnostic evaluation without manual annotation or translation. We then introduce four metrics that capture complementary dimensions of cultural awareness: granularity, diversity, cultural specificity, and consensus across languages. We assess 7 LLMs developed from different parts of the world, encompassing both open-source and proprietary systems, across 13 languages, 19 countries and regions, and 6 culturally salient topics (e.g., food, clothing). Notably, we find that models tend to exhibit stronger cultural awareness in English, suggesting that English prompts more effectively activate culturally grounded knowledge. We publicly release our code and data.
What's the Difference? Supporting Users in Identifying the Effects of Prompt and Model Changes Through Token Patterns
Apr 22, 2025



Prompt engineering for large language models is challenging, as even small prompt perturbations or model changes can significantly impact the generated output texts. Existing evaluation methods, either automated metrics or human evaluation, have limitations, such as providing limited insights or being labor-intensive. We propose Spotlight, a new approach that combines both automation and human analysis. Based on data mining techniques, we automatically distinguish between random (decoding) variations and systematic differences in language model outputs. This process provides token patterns that describe the systematic differences and guide the user in manually analyzing the effects of their prompt and model changes efficiently. We create three benchmarks to quantitatively test the reliability of token pattern extraction methods and demonstrate that our approach provides new insights into established prompt data. From a human-centric perspective, through demonstration studies and a user study, we show that our token pattern approach helps users understand the systematic differences of language model outputs, and we are able to discover relevant differences caused by prompt and model changes (e.g. related to gender or culture), thus supporting the prompt engineering process and human-centric model behavior research.
SYNTHEVAL: Hybrid Behavioral Testing of NLP Models with Synthetic CheckLists
Aug 30, 2024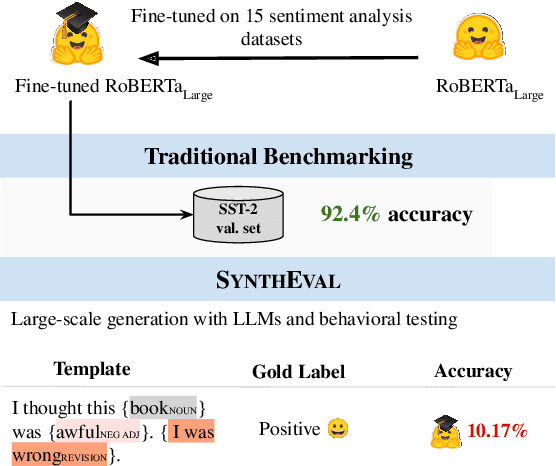

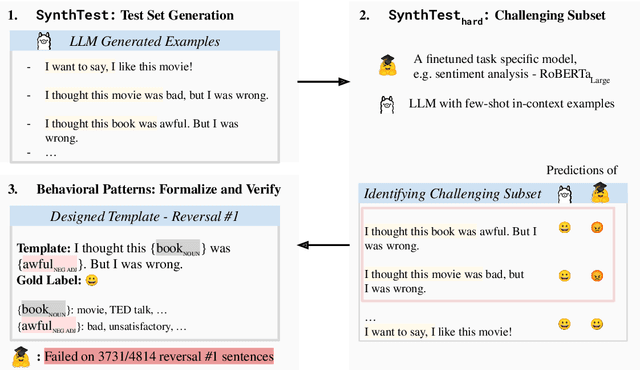

Traditional benchmarking in NLP typically involves using static held-out test sets. However, this approach often results in an overestimation of performance and lacks the ability to offer comprehensive, interpretable, and dynamic assessments of NLP models. Recently, works like DynaBench (Kiela et al., 2021) and CheckList (Ribeiro et al., 2020) have addressed these limitations through behavioral testing of NLP models with test types generated by a multistep human-annotated pipeline. Unfortunately, manually creating a variety of test types requires much human labor, often at prohibitive cost. In this work, we propose SYNTHEVAL, a hybrid behavioral testing framework that leverages large language models (LLMs) to generate a wide range of test types for a comprehensive evaluation of NLP models. SYNTHEVAL first generates sentences via LLMs using controlled generation, and then identifies challenging examples by comparing the predictions made by LLMs with task-specific NLP models. In the last stage, human experts investigate the challenging examples, manually design templates, and identify the types of failures the taskspecific models consistently exhibit. We apply SYNTHEVAL to two classification tasks, sentiment analysis and toxic language detection, and show that our framework is effective in identifying weaknesses of strong models on these tasks. We share our code in https://github.com/Loreley99/SynthEval_CheckList.