 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupling the Effect of Chain-of-Thought Reasoning: A Human Label Variation Perspective
Jan 06, 2026Reasoning-tuned LLMs utilizing long Chain-of-Thought (CoT) excel at single-answer tasks, yet their ability to model Human Label Variation--which requires capturing probabilistic ambiguity rather than resolving it--remains underexplored. We investigate this through systematic disentanglement experiments on distribution-based tasks, employing Cross-CoT experiments to isolate the effect of reasoning text from intrinsic model priors. We observe a distinct "decoupled mechanism": while CoT improves distributional alignment, final accuracy is dictated by CoT content (99% variance contribution), whereas distributional ranking is governed by model priors (over 80%). Step-wise analysis further shows that while CoT's influence on accuracy grows monotonically during the reasoning process, distributional structure is largely determined by LLM's intrinsic priors. These findings suggest that long CoT serves as a decisive LLM decision-maker for the top option but fails to function as a granular distribution calibrator for ambiguous tasks.
Threading the Needle: Reweaving Chain-of-Thought Reasoning to Explain Human Label Variation
May 29, 2025



The recent rise of reasoning-tuned Large Language Models (LLMs)--which generate chains of thought (CoTs) before giving the final answer--has attracted significant attention and offers new opportunities for gaining insights into human label variation, which refers to plausible differences in how multiple annotators label the same data instance. Prior work has shown that LLM-generated explanations can help align model predictions with human label distributions, but typically adopt a reverse paradigm: producing explanations based on given answers. In contrast, CoTs provide a forward reasoning path that may implicitly embed rationales for each answer option, before generating the answers. We thus propose a novel LLM-based pipeline enriched with linguistically-grounded discourse segmenters to extract supporting and opposing statements for each answer option from CoTs with improved accuracy. We also propose a rank-based HLV evaluation framework that prioritizes the ranking of answers over exact scores, which instead favor direct comparison of label distributions. Our method outperforms a direct generation method as well as baselines on three datasets, and shows better alignment of ranking methods with humans, highlighting the effectiveness of our approach.
LiTEx: A Linguistic Taxonomy of Explanations for Understanding Within-Label Variation in Natural Language Inference
May 28, 2025



There is increasing evidence of Human Label Variation (HLV) in Natural Language Inference (NLI), where annotators assign different labels to the same premise-hypothesis pair. However, within-label variation--cases where annotators agree on the same label but provide divergent reasoning--poses an additional and mostly overlooked challenge. Several NLI datasets contain highlighted words in the NLI item as explanations, but the same spans on the NLI item can be highlighted for different reasons, as evidenced by free-text explanations, which offer a window into annotators' reasoning. To systematically understand this problem and gain insight into the rationales behind NLI labels, we introduce LITEX, a linguistically-informed taxonomy for categorizing free-text explanations. Using this taxonomy, we annotate a subset of the e-SNLI dataset, validate the taxonomy's reliability, and analyze how it aligns with NLI labels, highlights, and explanations. We further assess the taxonomy's usefulness in explanation generation, demonstrating that conditioning generation on LITEX yields explanations that are linguistically closer to human explanations than those generated using only labels or highlights. Our approach thus not only captures within-label variation but also shows how taxonomy-guided generation for reasoning can bridge the gap between human and model explanations more effectively than existing strategies.
MAKIEval: A Multilingual Automatic WiKidata-based Framework for Cultural Awareness Evaluation for LLMs
May 27, 2025Large language models (LLMs) are used globally across many languages, but their English-centric pretraining raises concerns about cross-lingual disparities for cultural awareness, often resulting in biased outputs. However, comprehensive multilingual evaluation remains challenging due to limited benchmarks and questionable translation quality. To better assess these disparities, we introduce MAKIEval, an automatic multilingual framework for evaluating cultural awareness in LLMs across languages, regions, and topics. MAKIEval evaluates open-ended text generation, capturing how models express culturally grounded knowledge in natural language. Leveraging Wikidata's multilingual structure as a cross-lingual anchor, it automatically identifies cultural entities in model outputs and links them to structured knowledge, enabling scalable, language-agnostic evaluation without manual annotation or translation. We then introduce four metrics that capture complementary dimensions of cultural awareness: granularity, diversity, cultural specificity, and consensus across languages. We assess 7 LLMs developed from different parts of the world, encompassing both open-source and proprietary systems, across 13 languages, 19 countries and regions, and 6 culturally salient topics (e.g., food, clothing). Notably, we find that models tend to exhibit stronger cultural awareness in English, suggesting that English prompts more effectively activate culturally grounded knowledge. We publicly release our code and data.
A Rose by Any Other Name: LLM-Generated Explanations Are Good Proxies for Human Explanations to Collect Label Distributions on NLI
Dec 18, 2024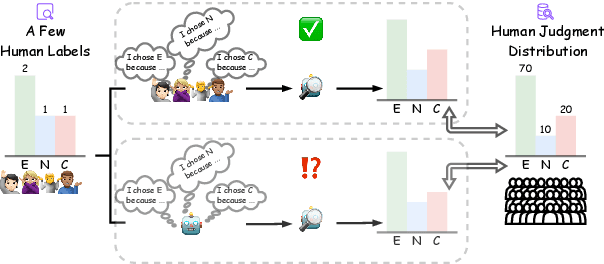
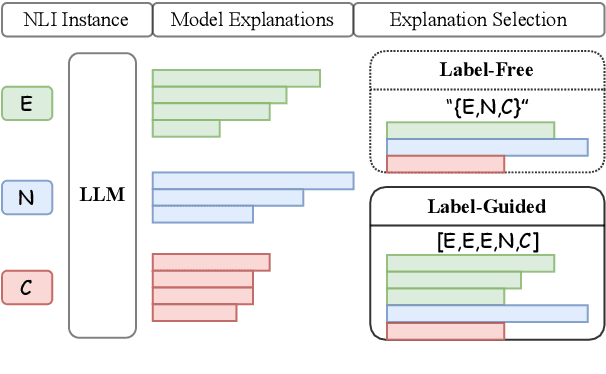
Disagreement in human labeling is ubiquitous, and can be captured in human judgment distributions (HJDs). Recent research has shown that explanations provide valuable information for understanding human label variation (HLV) and large language models (LLMs) can approximate HJD from a few human-provided label-explanation pairs. However, collecting explanations for every label is still time-consuming. This paper examines whether LLMs can be used to replace humans in generating explanations for approximating HJD. Specifically, we use LLMs as annotators to generate model explanations for a few given human labels. We test ways to obtain and combine these label-explanations with the goal to approximate human judgment distribution. We further compare the resulting human with model-generated explanations, and test automatic and human explanation selection. Our experiments show that LLM explanations are promising for NLI: to estimate HJD, generated explanations yield comparable results to human's when provided with human labels. Importantly, our results generalize from datasets with human explanations to i) datasets where they are not available and ii) challenging out-of-distribution test sets.
"Seeing the Big through the Small": Can LLMs Approximate Human Judgment Distributions on NLI from a Few Explanations?
Jun 25, 2024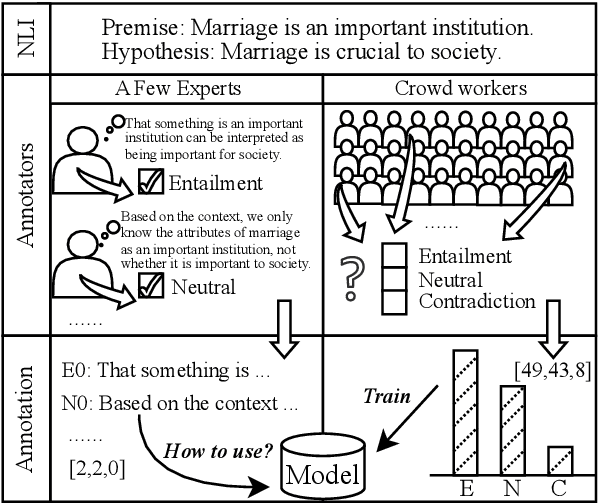

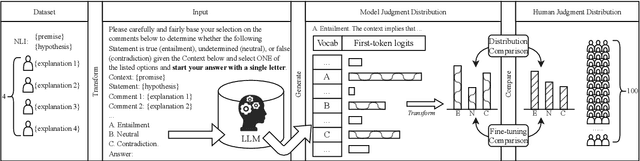
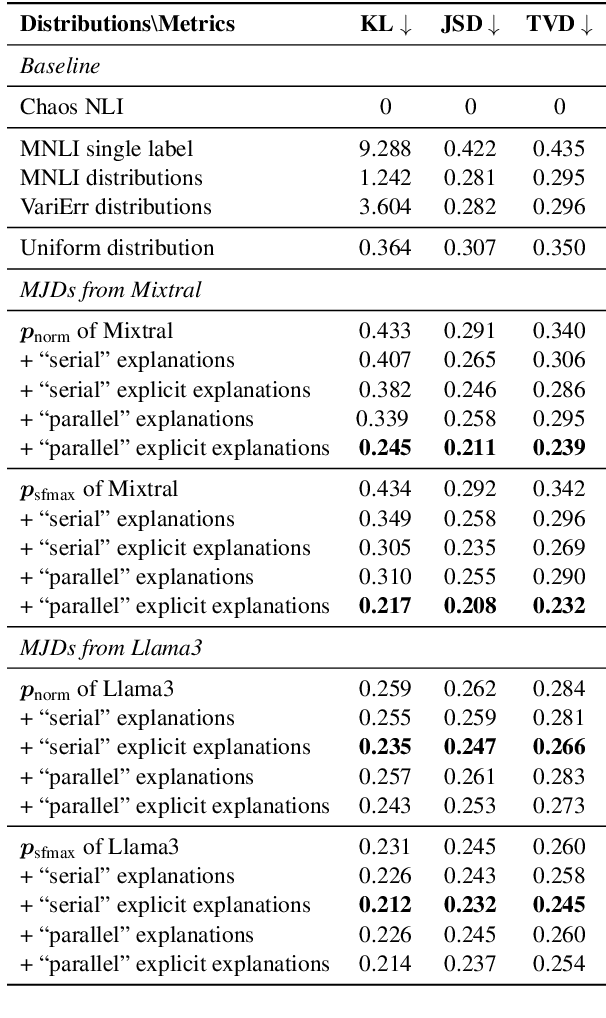
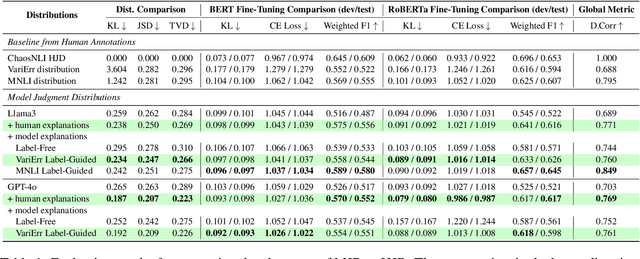
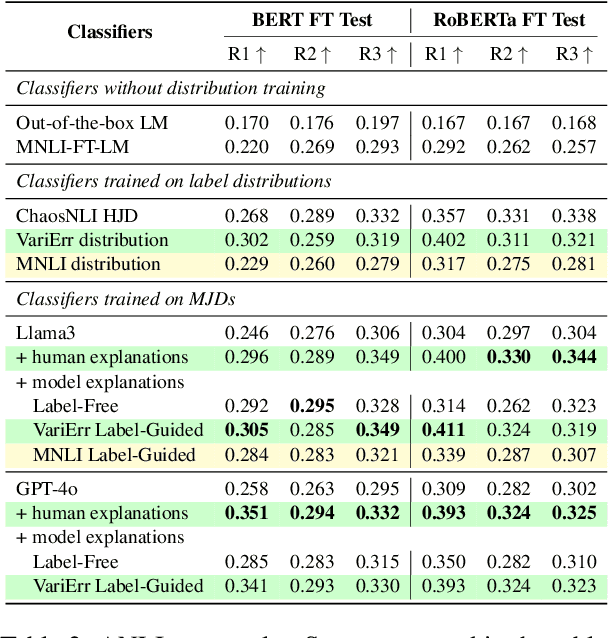
Human label variation (HLV) is a valuable source of information that arises when multiple human annotators provide different labels for valid reasons. In Natural Language Inference (NLI) earlier approaches to capturing HLV involve either collecting annotations from many crowd workers to represent human judgment distribution (HJD) or use expert linguists to provide detailed explanations for their chosen labels. While the former method provides denser HJD information, obtaining it is resource-intensive. In contrast, the latter offers richer textual information but it is challenging to scale up to many human judges. Besides, large language models (LLMs) are increasingly used as evaluators (``LLM judges'') but with mixed results, and few works aim to study HJDs. This study proposes to exploit LLMs to approximate HJDs using a small number of expert labels and explanations. Our experiments show that a few explanations significantly improve LLMs' ability to approximate HJDs with and without explicit labels, thereby providing a solution to scale up annotations for HJD. However, fine-tuning smaller soft-label aware models with the LLM-generated model judgment distributions (MJDs) presents partially inconsistent results: while similar in distance, their resulting fine-tuned models and visualized distributions differ substantially. We show the importance of complementing instance-level distance measures with a global-level shape metric and visualization to more effectively evaluate MJDs against human judgment distributions.
Pre-training Language Model as a Multi-perspective Course Learner
May 06, 2023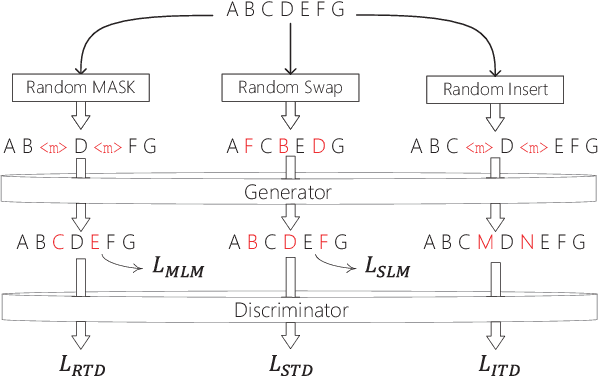

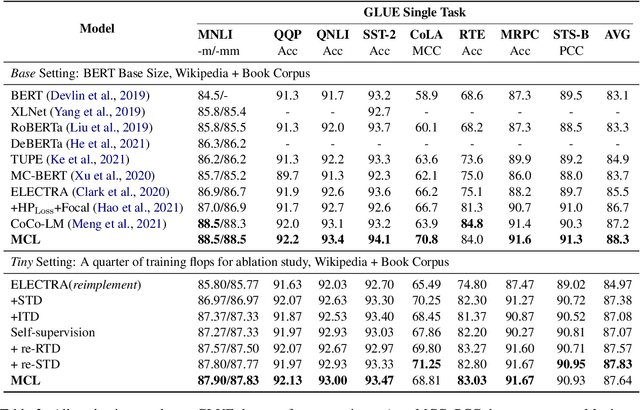
ELECTRA, the generator-discriminator pre-training framework, has achieved impressive semantic construction capability among various downstream tasks. Despite the convincing performance, ELECTRA still faces the challenges of monotonous training and deficient interaction. Generator with only masked language modeling (MLM) leads to biased learning and label imbalance for discriminator, decreasing learning efficiency; no explicit feedback loop from discriminator to generator results in the chasm between these two components, underutilizing the course learning. In this study, a multi-perspective course learning (MCL) method is proposed to fetch a many degrees and visual angles for sample-efficient pre-training, and to fully leverage the relationship between generator and discriminator. Concretely, three self-supervision courses are designed to alleviate inherent flaws of MLM and balance the label in a multi-perspective way. Besides, two self-correction courses are proposed to bridge the chasm between the two encoders by creating a "correction notebook" for secondary-supervision. Moreover, a course soups trial is conducted to solve the "tug-of-war" dynamics problem of MCL, evolving a stronger pre-trained model. Experimental results show that our method significantly improves ELECTRA's average performance by 2.8% and 3.2% absolute points respectively on GLUE and SQuAD 2.0 benchmarks, and overshadows recent advanced ELECTRA-style models under the same settings. The pre-trained MCL model is available at https://huggingface.co/McmanusChen/MCL-base.
WIDER & CLOSER: Mixture of Short-channel Distillers for Zero-shot Cross-lingual Named Entity Recognition
Dec 07, 2022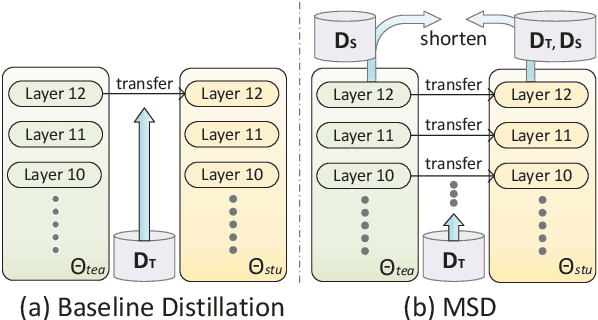
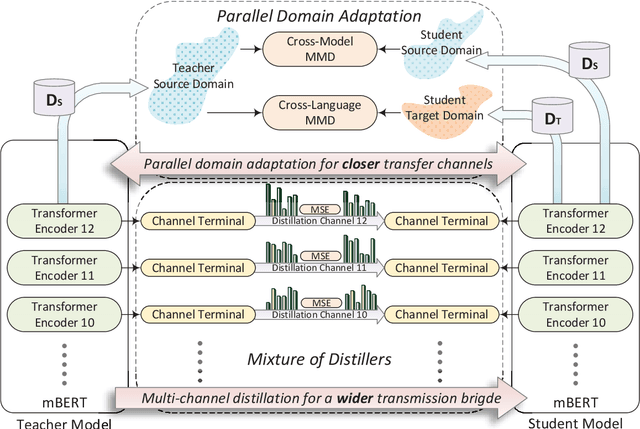
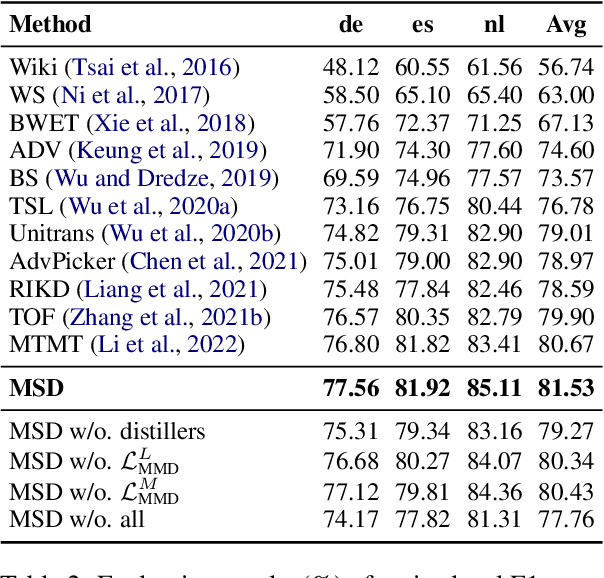
Zero-shot cross-lingual named entity recognition (NER) aims at transferring knowledge from annotated and rich-resource data in source languages to unlabeled and lean-resource data in target languages. Existing mainstream methods based on the teacher-student distillation framework ignore the rich and complementary information lying in the intermediate layers of pre-trained language models, and domain-invariant information is easily lost during transfer. In this study, a mixture of short-channel distillers (MSD) method is proposed to fully interact the rich hierarchical information in the teacher model and to transfer knowledge to the student model sufficiently and efficiently. Concretely, a multi-channel distillation framework is designed for sufficient information transfer by aggregating multiple distillers as a mixture. Besides, an unsupervised method adopting parallel domain adaptation is proposed to shorten the channels between the teacher and student models to preserve domain-invariant features. Experiments on four datasets across nine languages demonstrate that the proposed method achieves new state-of-the-art performance on zero-shot cross-lingual NER and shows great generalization and compatibility across languages and fields.
Feature Aggregation in Zero-Shot Cross-Lingual Transfer Using Multilingual BERT
May 17, 2022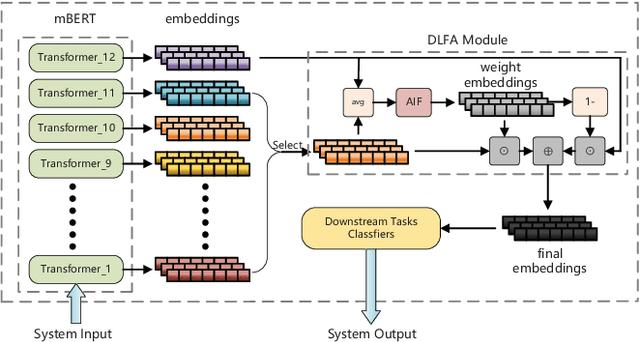
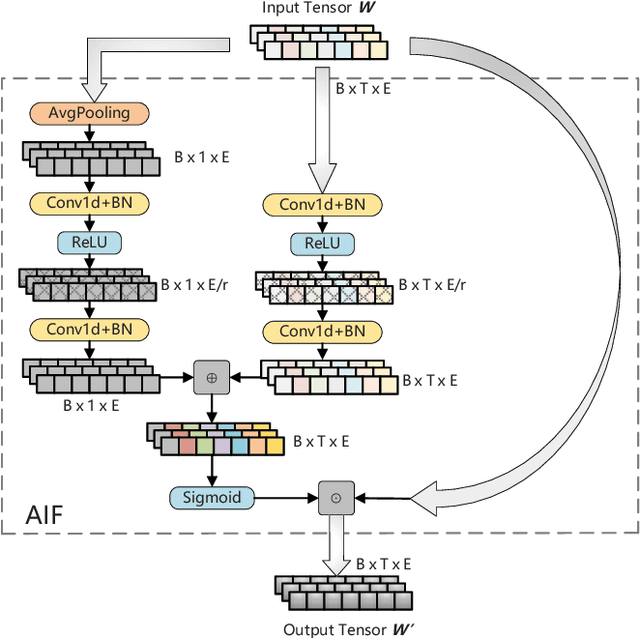
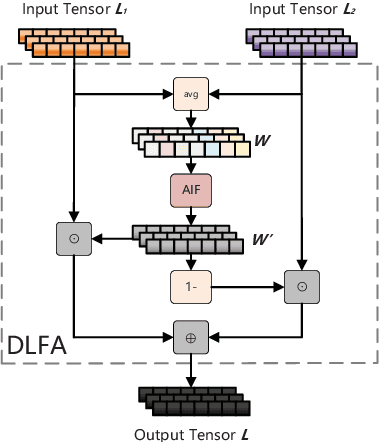
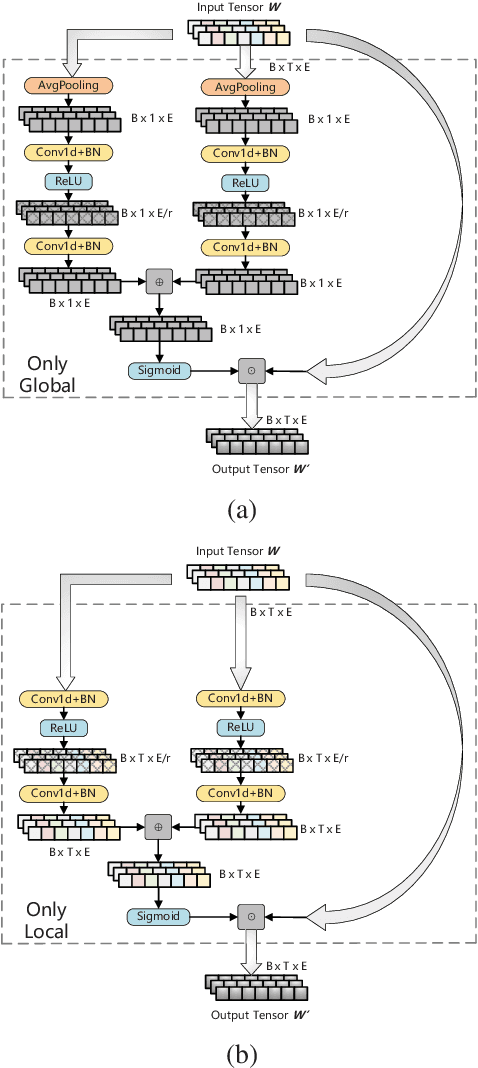
Multilingual BERT (mBERT), a language model pre-trained on large multilingual corpora, has impressive zero-shot cross-lingual transfer capabilities and performs surprisingly well on zero-shot POS tagging and Named Entity Recognition (NER), as well as on cross-lingual model transfer. At present, the mainstream methods to solve the cross-lingual downstream tasks are always using the last transformer layer's output of mBERT as the representation of linguistic information. In this work, we explore the complementary property of lower layers to the last transformer layer of mBERT. A feature aggregation module based on an attention mechanism is proposed to fuse the information contained in different layers of mBERT. The experiments are conducted on four zero-shot cross-lingual transfer datasets, and the proposed method obtains performance improvements on key multilingual benchmark tasks XNLI (+1.5 %), PAWS-X (+2.4 %), NER (+1.2 F1), and POS (+1.5 F1). Through the analysis of the experimental results, we prove that the layers before the last layer of mBERT can provide extra useful information for cross-lingual downstream tasks and explore the interpretability of mBERT empirically.
USTC-NELSLIP at SemEval-2022 Task 11: Gazetteer-Adapted Integration Network for Multilingual Complex Named Entity Recognition
Mar 07, 2022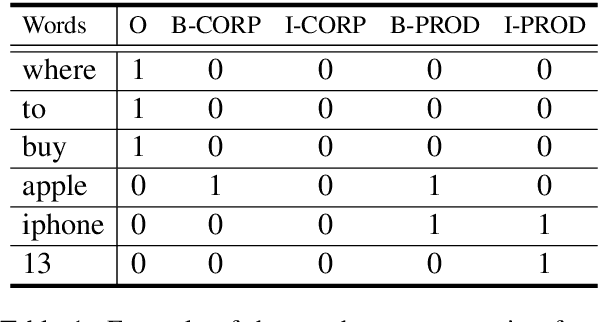

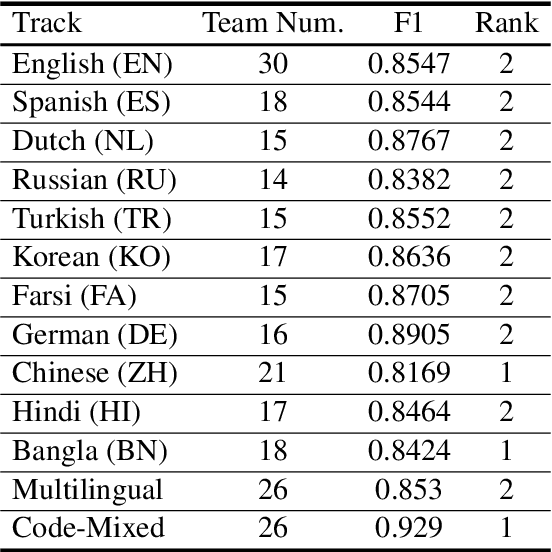
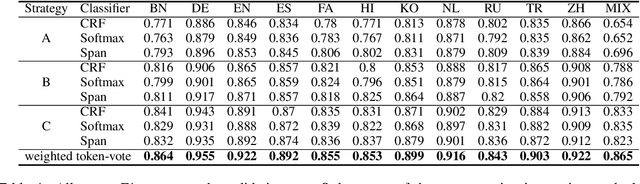
This paper describes the system developed by the USTC-NELSLIP team for SemEval-2022 Task 11 Multilingual Complex Named Entity Recognition (MultiCoNER). We propose a gazetteer-adapted integration network (GAIN) to improve the performance of language models for recognizing complex named entities. The method first adapts the representations of gazetteer networks to those of language models by minimizing the KL divergence between them. After adaptation, these two networks are then integrated for backend supervised named entity recognition (NER) training. The proposed method is applied to several state-of-the-art Transformer-based NER models with a gazetteer built from Wikidata, and shows great generalization ability across them. The final predictions are derived from an ensemble of these trained models. Experimental results and detailed analysis verify the effectiveness of the proposed method. The official results show that our system ranked 1st on three tracks (Chinese, Code-mixed and Bangla) and 2nd on the other ten tracks in this task.