 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiplicative Orthogonal Sequential Editing for Language Models
Jan 11, 2026Knowledge editing aims to efficiently modify the internal knowledge of large language models (LLMs) without compromising their other capabilities. The prevailing editing paradigm, which appends an update matrix to the original parameter matrix, has been shown by some studies to damage key numerical stability indicators (such as condition number and norm), thereby reducing editing performance and general abilities, especially in sequential editing scenario. Although subsequent methods have made some improvements, they remain within the additive framework and have not fundamentally addressed this limitation. To solve this problem, we analyze it from both statistical and mathematical perspectives and conclude that multiplying the original matrix by an orthogonal matrix does not change the numerical stability of the matrix. Inspired by this, different from the previous additive editing paradigm, a multiplicative editing paradigm termed Multiplicative Orthogonal Sequential Editing (MOSE) is proposed. Specifically, we first derive the matrix update in the multiplicative form, the new knowledge is then incorporated into an orthogonal matrix, which is multiplied by the original parameter matrix. In this way, the numerical stability of the edited matrix is unchanged, thereby maintaining editing performance and general abilities. We compared MOSE with several current knowledge editing methods, systematically evaluating their impact on both editing performance and the general abilities across three different LLMs. Experimental results show that MOSE effectively limits deviations in the edited parameter matrix and maintains its numerical stability. Compared to current methods, MOSE achieves a 12.08% improvement in sequential editing performance, while retaining 95.73% of general abilities across downstream tasks. The code is available at https://github.com/famoustourist/MOSE.
Explore to Evolve: Scaling Evolved Aggregation Logic via Proactive Online Exploration for Deep Research Agents
Oct 16, 2025Deep research web agents not only retrieve information from diverse sources such as web environments, files, and multimodal inputs, but more importantly, they need to rigorously analyze and aggregate knowledge for insightful research. However, existing open-source deep research agents predominantly focus on enhancing information-seeking capabilities of web agents to locate specific information, while overlooking the essential need for information aggregation, which would limit their ability to support in-depth research. We propose an Explore to Evolve paradigm to scalably construct verifiable training data for web agents. Begins with proactive online exploration, an agent sources grounded information by exploring the real web. Using the collected evidence, the agent then self-evolves an aggregation program by selecting, composing, and refining operations from 12 high-level logical types to synthesize a verifiable QA pair. This evolution from high-level guidance to concrete operations allowed us to scalably produce WebAggregatorQA, a dataset of 10K samples across 50K websites and 11 domains. Based on an open-source agent framework, SmolAgents, we collect supervised fine-tuning trajectories to develop a series of foundation models, WebAggregator. WebAggregator-8B matches the performance of GPT-4.1, while the 32B variant surpasses GPT-4.1 by more than 10% on GAIA-text and closely approaches Claude-3.7-sonnet. Moreover, given the limited availability of benchmarks that evaluate web agents' information aggregation abilities, we construct a human-annotated evaluation split of WebAggregatorQA as a challenging test set. On this benchmark, Claude-3.7-sonnet only achieves 28%, and GPT-4.1 scores 25.8%. Even when agents manage to retrieve all references, they still struggle on WebAggregatorQA, highlighting the need to strengthen the information aggregation capabilities of web agent foundations.
Perturbation-Restrained Sequential Model Editing
May 27, 2024



Model editing is an emerging field that focuses on updating the knowledge embedded within large language models (LLMs) without extensive retraining. However, current model editing methods significantly compromise the general abilities of LLMs as the number of edits increases, and this trade-off poses a substantial challenge to the continual learning of LLMs. In this paper, we first theoretically analyze that the factor affecting the general abilities in sequential model editing lies in the condition number of the edited matrix. The condition number of a matrix represents its numerical sensitivity, and therefore can be used to indicate the extent to which the original knowledge associations stored in LLMs are perturbed after editing. Subsequently, statistical findings demonstrate that the value of this factor becomes larger as the number of edits increases, thereby exacerbating the deterioration of general abilities. To this end, a framework termed Perturbation Restraint on Upper bouNd for Editing (PRUNE) is proposed, which applies the condition number restraints in sequential editing. These restraints can lower the upper bound on perturbation to edited models, thus preserving the general abilities. Systematically, we conduct experiments employing three popular editing methods on three LLMs across four representative downstream tasks. Evaluation results show that PRUNE can preserve considerable general abilities while maintaining the editing performance effectively in sequential model editing. The code and data are available at https://github.com/mjy1111/PRUNE.
Neighboring Perturbations of Knowledge Editing on Large Language Models
Jan 31, 2024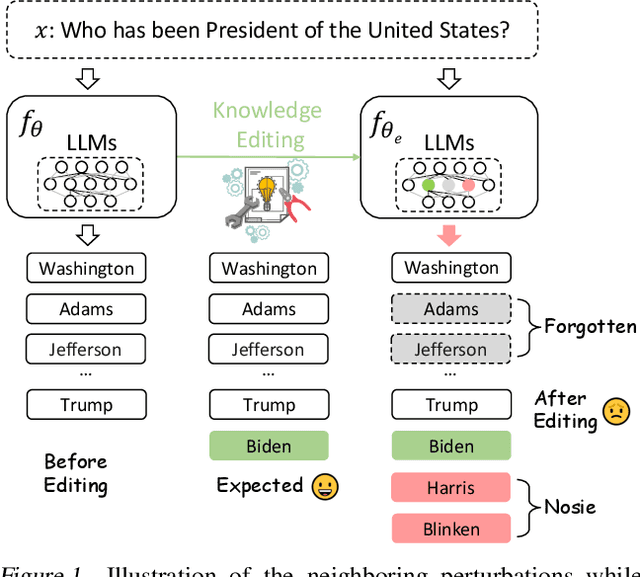

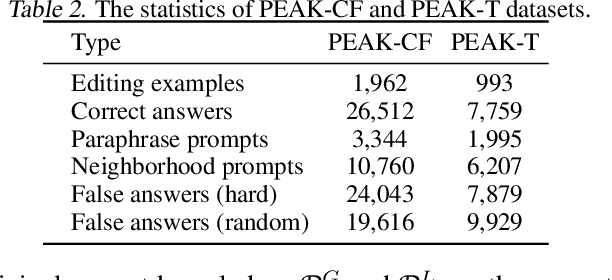
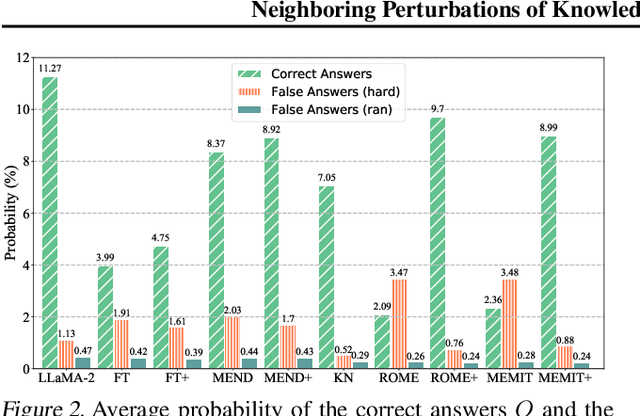
Despite their exceptional capabilities, large language models (LLMs) are prone to generating unintended text due to false or outdated knowledge. Given the resource-intensive nature of retraining LLMs, there has been a notable increase in the development of knowledge editing. However, current approaches and evaluations rarely explore the perturbation of editing on neighboring knowledge. This paper studies whether updating new knowledge to LLMs perturbs the neighboring knowledge encapsulated within them. Specifically, we seek to figure out whether appending a new answer into an answer list to a factual question leads to catastrophic forgetting of original correct answers in this list, as well as unintentional inclusion of incorrect answers. A metric of additivity is introduced and a benchmark dubbed as Perturbation Evaluation of Appending Knowledge (PEAK) is constructed to evaluate the degree of perturbation to neighboring knowledge when appending new knowledge. Besides, a plug-and-play framework termed Appending via Preservation and Prevention (APP) is proposed to mitigate the neighboring perturbation by maintaining the integrity of the answer list. Experiments demonstrate the effectiveness of APP coupling with four editing methods on three LLMs.
Model Editing Can Hurt General Abilities of Large Language Models
Jan 09, 2024



Recent advances in large language models (LLMs) have opened up new paradigms for accessing the knowledge stored in their parameters. One critical challenge that has emerged is the presence of hallucinations in LLM outputs due to false or outdated knowledge. Since retraining LLMs with updated information is resource-intensive, there has been a growing interest in model editing. However, many model editing methods, while effective in various scenarios, tend to overemphasize aspects such as efficacy, generalization, and locality in editing performance, often overlooking potential side effects on the general abilities of LLMs. In this paper, we raise concerns that the improvement of model factuality may come at the cost of a significant degradation of these general abilities, which is not conducive to the sustainable development of LLMs. Systematically, we analyze side effects by evaluating four popular editing methods on two LLMs across eight representative task categories. Extensive empirical research reveals that model editing does improve model factuality but at the expense of substantially impairing general abilities. Therefore, we advocate for more research efforts to minimize the loss of general abilities acquired during LLM pre-training and to ultimately preserve them during model editing.
Untying the Reversal Curse via Bidirectional Language Model Editing
Oct 16, 2023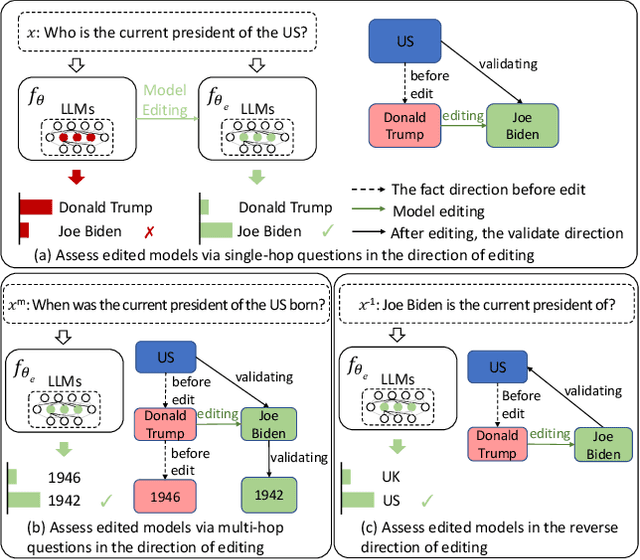

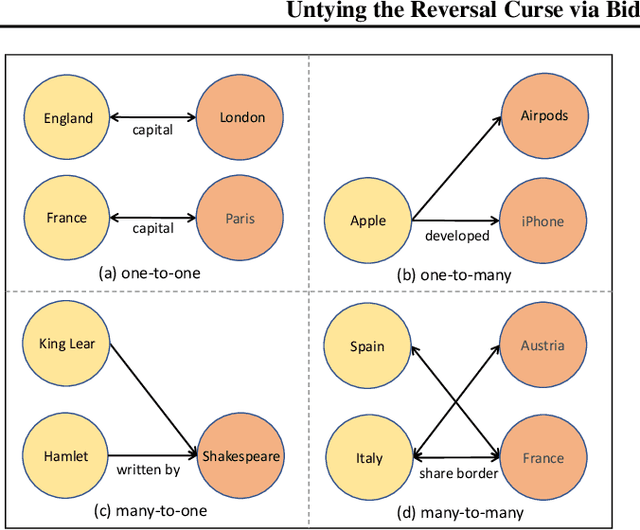
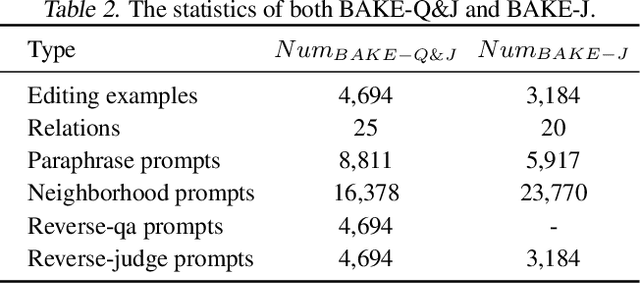
Recent studies have demonstrated that large language models (LLMs) store massive factual knowledge within their parameters. But existing LLMs are prone to hallucinate unintended text due to false or outdated knowledge. Since retraining LLMs is resource intensive, there has been a growing interest in the concept of model editing. Despite the emergence of benchmarks and approaches, these unidirectional editing and evaluation have failed to explore the reversal curse. Intuitively, if "The capital of France is" is edited to be a counterfact "London" within a model, then it should be able to naturally reason and recall the reverse fact, i.e., "London is the capital of" followed by "France" instead of "England". In this paper, we study bidirectional language model editing, aiming to provide rigorous model editing evaluation to assess if edited LLMs can recall the editing knowledge bidirectionally. A new evaluation metric of reversibility is introduced, and a benchmark dubbed as Bidirectional Assessment for Knowledge Editing (BAKE) is constructed to evaluate the reversibility of edited models in recalling knowledge in the reverse direction of editing. We surprisingly observe that while current editing methods and LLMs can effectively recall editing facts in the direction of editing, they suffer serious deficiencies when evaluated in the reverse direction. To mitigate the reversal curse, a method named Bidirectionally Inversible Relationship moDeling (BIRD) is proposed. A set of editing objectives that incorporate bidirectional relationships between subject and object into the updated model weights are designed. Experiments show that BIRD improves the performance of four representative LLMs of different sizes via question answering and judgement.
SHINE: Syntax-augmented Hierarchical Interactive Encoder for Zero-shot Cross-lingual Information Extraction
May 21, 2023Zero-shot cross-lingual information extraction(IE) aims at constructing an IE model for some low-resource target languages, given annotations exclusively in some rich-resource languages. Recent studies based on language-universal features have shown their effectiveness and are attracting increasing attention. However, prior work has neither explored the potential of establishing interactions between language-universal features and contextual representations nor incorporated features that can effectively model constituent span attributes and relationships between multiple spans. In this study, a syntax-augmented hierarchical interactive encoder (SHINE) is proposed to transfer cross-lingual IE knowledge. The proposed encoder is capable of interactively capturing complementary information between features and contextual information, to derive language-agnostic representations for various IE tasks. Concretely, a multi-level interaction network is designed to hierarchically interact the complementary information to strengthen domain adaptability. Besides, in addition to the well-studied syntax features of part-of-speech and dependency relation, a new syntax feature of constituency structure is introduced to model the constituent span information which is crucial for IE. Experiments across seven languages on three IE tasks and four benchmarks verify the effectiveness and generalization ability of the proposed method.
USTC-NELSLIP at SemEval-2023 Task 2: Statistical Construction and Dual Adaptation of Gazetteer for Multilingual Complex NER
May 04, 2023This paper describes the system developed by the USTC-NELSLIP team for SemEval-2023 Task 2 Multilingual Complex Named Entity Recognition (MultiCoNER II). A method named Statistical Construction and Dual Adaptation of Gazetteer (SCDAG) is proposed for Multilingual Complex NER. The method first utilizes a statistics-based approach to construct a gazetteer. Secondly, the representations of gazetteer networks and language models are adapted by minimizing the KL divergence between them at both the sentence-level and entity-level. Finally, these two networks are then integrated for supervised named entity recognition (NER) training. The proposed method is applied to XLM-R with a gazetteer built from Wikidata, and shows great generalization ability across different tracks. Experimental results and detailed analysis verify the effectiveness of the proposed method. The official results show that our system ranked 1st on one track (Hindi) in this task.
WIDER & CLOSER: Mixture of Short-channel Distillers for Zero-shot Cross-lingual Named Entity Recognition
Dec 07, 2022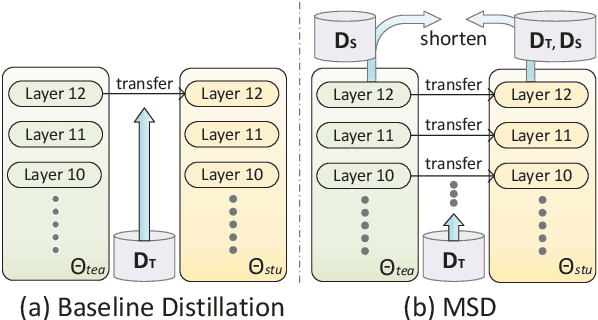
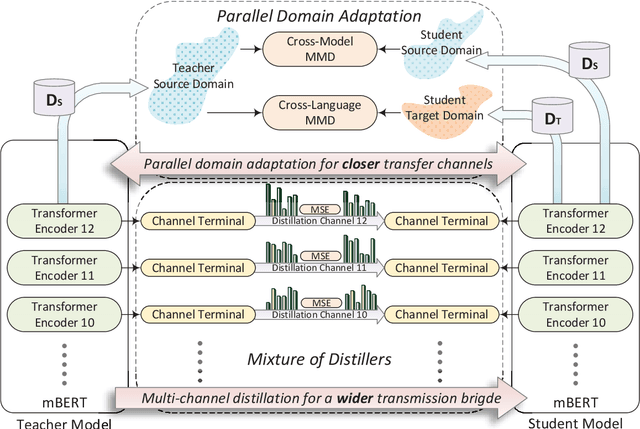
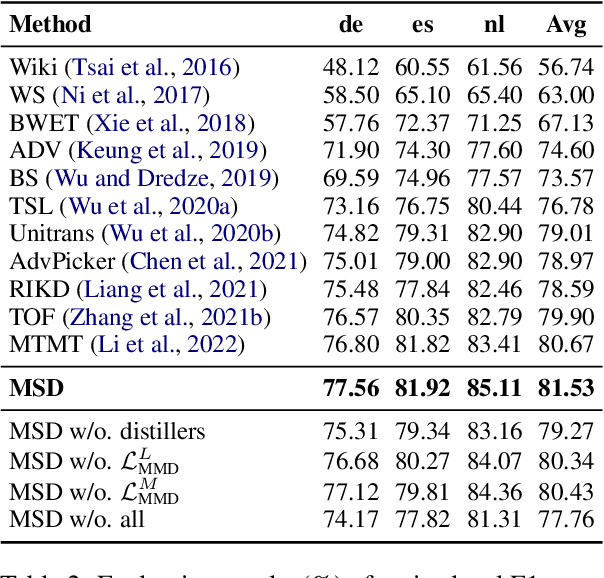
Zero-shot cross-lingual named entity recognition (NER) aims at transferring knowledge from annotated and rich-resource data in source languages to unlabeled and lean-resource data in target languages. Existing mainstream methods based on the teacher-student distillation framework ignore the rich and complementary information lying in the intermediate layers of pre-trained language models, and domain-invariant information is easily lost during transfer. In this study, a mixture of short-channel distillers (MSD) method is proposed to fully interact the rich hierarchical information in the teacher model and to transfer knowledge to the student model sufficiently and efficiently. Concretely, a multi-channel distillation framework is designed for sufficient information transfer by aggregating multiple distillers as a mixture. Besides, an unsupervised method adopting parallel domain adaptation is proposed to shorten the channels between the teacher and student models to preserve domain-invariant features. Experiments on four datasets across nine languages demonstrate that the proposed method achieves new state-of-the-art performance on zero-shot cross-lingual NER and shows great generalization and compatibility across languages and fields.
USTC-NELSLIP at SemEval-2022 Task 11: Gazetteer-Adapted Integration Network for Multilingual Complex Named Entity Recognition
Mar 07, 2022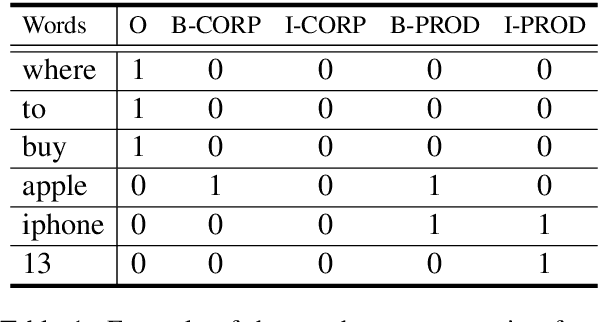

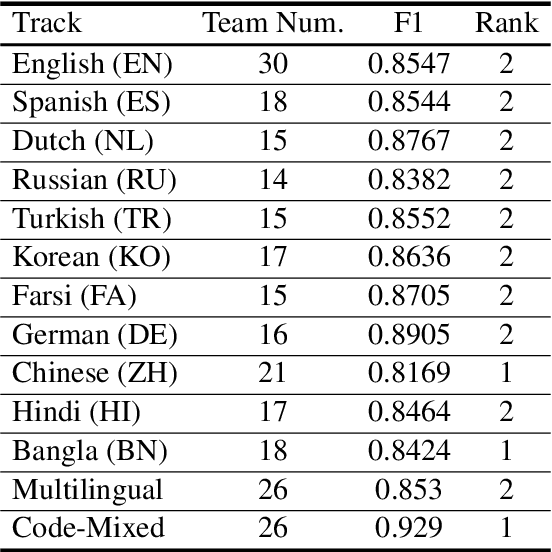
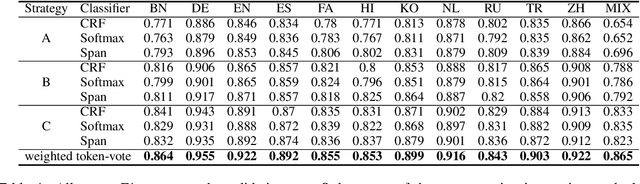
This paper describes the system developed by the USTC-NELSLIP team for SemEval-2022 Task 11 Multilingual Complex Named Entity Recognition (MultiCoNER). We propose a gazetteer-adapted integration network (GAIN) to improve the performance of language models for recognizing complex named entities. The method first adapts the representations of gazetteer networks to those of language models by minimizing the KL divergence between them. After adaptation, these two networks are then integrated for backend supervised named entity recognition (NER) training. The proposed method is applied to several state-of-the-art Transformer-based NER models with a gazetteer built from Wikidata, and shows great generalization ability across them. The final predictions are derived from an ensemble of these trained models. Experimental results and detailed analysis verify the effectiveness of the proposed method. The official results show that our system ranked 1st on three tracks (Chinese, Code-mixed and Bangla) and 2nd on the other ten tracks in this task.