 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCE-GOCD: Central Entity-Guided Graph Optimization for Community Detection to Augment LLM Scientific Question Answering
Jan 29, 2026Large Language Models (LLMs) are increasingly used for question answering over scientific research papers. Existing retrieval augmentation methods often rely on isolated text chunks or concepts, but overlook deeper semantic connections between papers. This impairs the LLM's comprehension of scientific literature, hindering the comprehensiveness and specificity of its responses. To address this, we propose Central Entity-Guided Graph Optimization for Community Detection (CE-GOCD), a method that augments LLMs' scientific question answering by explicitly modeling and leveraging semantic substructures within academic knowledge graphs. Our approach operates by: (1) leveraging paper titles as central entities for targeted subgraph retrieval, (2) enhancing implicit semantic discovery via subgraph pruning and completion, and (3) applying community detection to distill coherent paper groups with shared themes. We evaluated the proposed method on three NLP literature-based question-answering datasets, and the results demonstrate its superiority over other retrieval-augmented baseline approaches, confirming the effectiveness of our framework.
Graph Reasoning Paradigm: Structured and Symbolic Reasoning with Topology-Aware Reinforcement Learning for Large Language Models
Jan 19, 2026Long Chain-of-Thought (LCoT), achieved by Reinforcement Learning with Verifiable Rewards (RLVR), has proven effective in enhancing the reasoning capabilities of Large Language Models (LLMs). However, reasoning in current LLMs is primarily generated as plain text, where performing semantic evaluation on such unstructured data creates a computational bottleneck during training. Despite RLVR-based optimization, existing methods still suffer from coarse-grained supervision, reward hacking, high training costs, and poor generalization. To address these issues, we propose the Graph Reasoning Paradigm (GRP), which realizes structured and symbolic reasoning, implemented via graph-structured representations with step-level cognitive labels. Building upon GRP, we further design Process-Aware Stratified Clipping Group Relative Policy Optimization (PASC-GRPO), which leverages structured evaluation to replace semantic evaluation, achieves process-aware verification through graph-structured outcome rewards, and mitigates reward hacking via stratified clipping advantage estimation. Experiments demonstrate significant improvements across mathematical reasoning and code generation tasks. Data, models, and code will be released later.
Evaluating LLMs Across Multi-Cognitive Levels: From Medical Knowledge Mastery to Scenario-Based Problem Solving
Jun 10, 2025Large language models (LLMs) have demonstrated remarkable performance on various medical benchmarks, but their capabilities across different cognitive levels remain underexplored. Inspired by Bloom's Taxonomy, we propose a multi-cognitive-level evaluation framework for assessing LLMs in the medical domain in this study. The framework integrates existing medical datasets and introduces tasks targeting three cognitive levels: preliminary knowledge grasp, comprehensive knowledge application, and scenario-based problem solving. Using this framework, we systematically evaluate state-of-the-art general and medical LLMs from six prominent families: Llama, Qwen, Gemma, Phi, GPT, and DeepSeek. Our findings reveal a significant performance decline as cognitive complexity increases across evaluated models, with model size playing a more critical role in performance at higher cognitive levels. Our study highlights the need to enhance LLMs' medical capabilities at higher cognitive levels and provides insights for developing LLMs suited to real-world medical applications.
Retrieval Augmented Generation Evaluation in the Era of Large Language Models: A Comprehensive Survey
Apr 21, 2025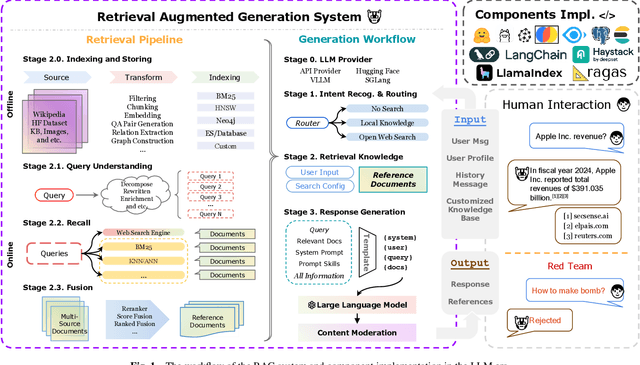
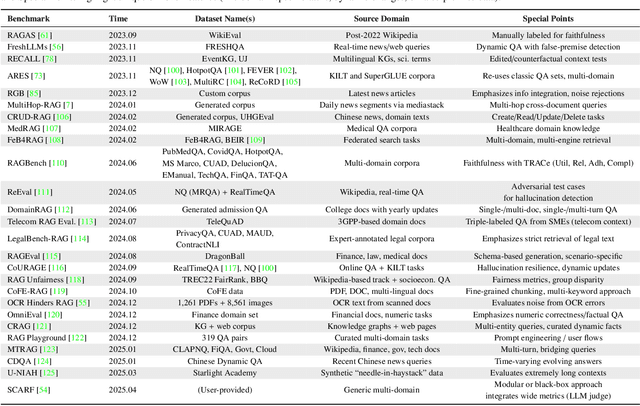

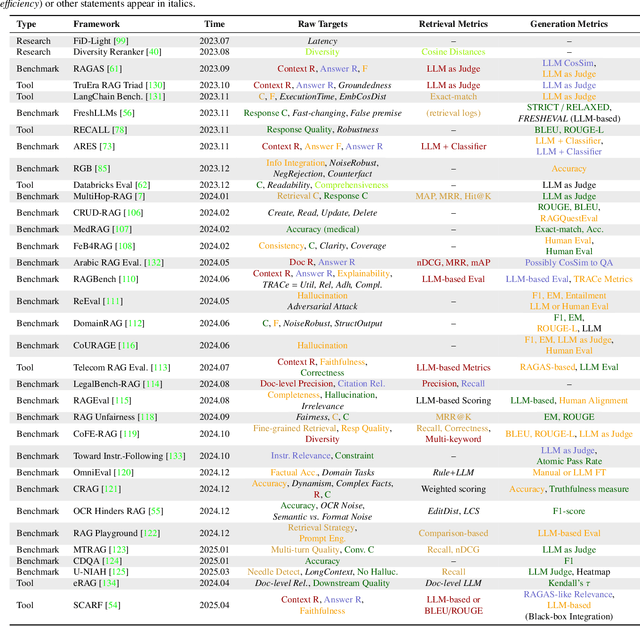
Recent advancements in Retrieval-Augmented Generation (RAG) have revolutionized natural language processing by integrating Large Language Models (LLMs) with external information retrieval, enabling accurate, up-to-date, and verifiable text generation across diverse applications. However, evaluating RAG systems presents unique challenges due to their hybrid architecture that combines retrieval and generation components, as well as their dependence on dynamic knowledge sources in the LLM era. In response, this paper provides a comprehensive survey of RAG evaluation methods and frameworks, systematically reviewing traditional and emerging evaluation approaches, for system performance, factual accuracy, safety, and computational efficiency in the LLM era. We also compile and categorize the RAG-specific datasets and evaluation frameworks, conducting a meta-analysis of evaluation practices in high-impact RAG research. To the best of our knowledge, this work represents the most comprehensive survey for RAG evaluation, bridging traditional and LLM-driven methods, and serves as a critical resource for advancing RAG development.
From Hypothesis to Publication: A Comprehensive Survey of AI-Driven Research Support Systems
Mar 03, 2025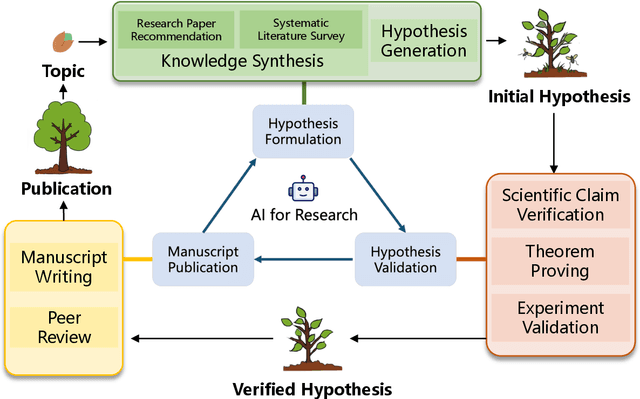
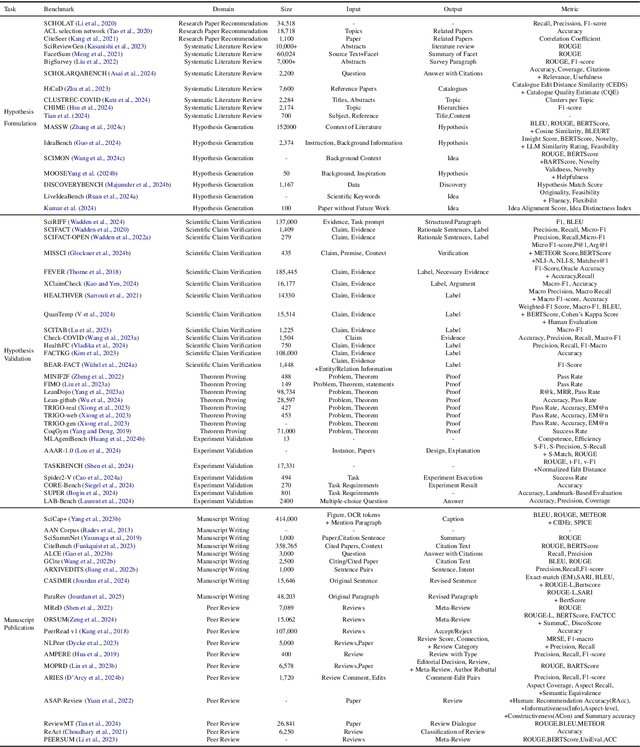

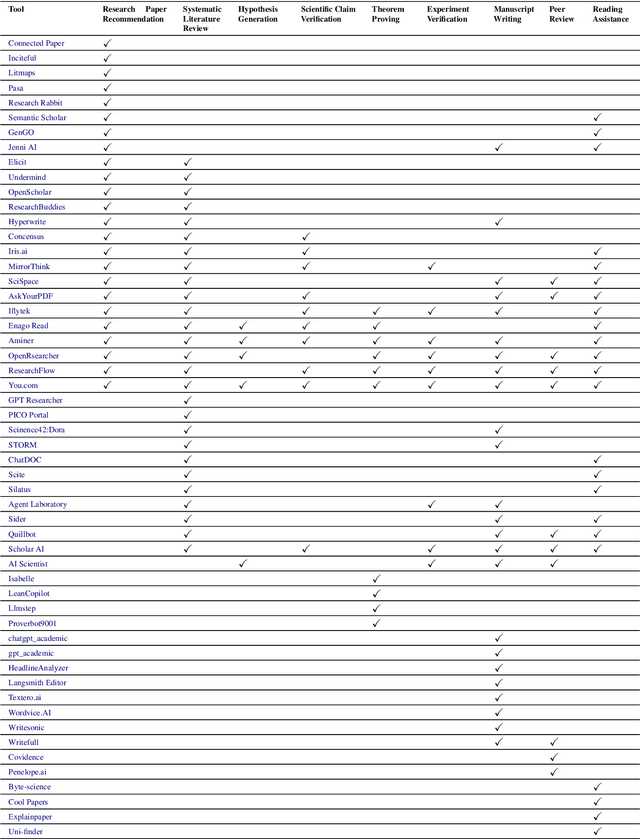
Research is a fundamental process driving the advancement of human civilization, yet it demands substantial time and effort from researchers. In recent years, the rapid development of artificial intelligence (AI) technologies has inspired researchers to explore how AI can accelerate and enhance research. To monitor relevant advancements, this paper presents a systematic review of the progress in this domain. Specifically, we organize the relevant studies into three main categories: hypothesis formulation, hypothesis validation, and manuscript publication. Hypothesis formulation involves knowledge synthesis and hypothesis generation. Hypothesis validation includes the verification of scientific claims, theorem proving, and experiment validation. Manuscript publication encompasses manuscript writing and the peer review process. Furthermore, we identify and discuss the current challenges faced in these areas, as well as potential future directions for research. Finally, we also offer a comprehensive overview of existing benchmarks and tools across various domains that support the integration of AI into the research process. We hope this paper serves as an introduction for beginners and fosters future research. Resources have been made publicly available at https://github.com/zkzhou126/AI-for-Research.
ChemEval: A Comprehensive Multi-Level Chemical Evaluation for Large Language Models
Sep 21, 2024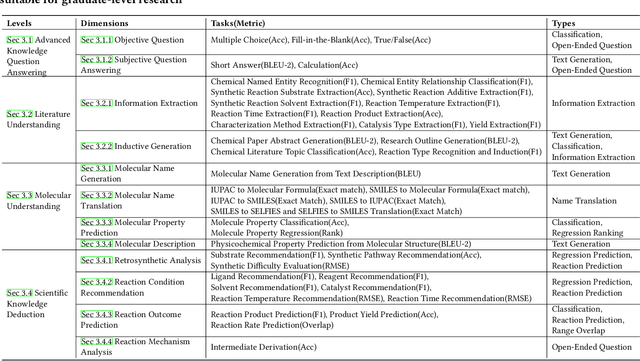
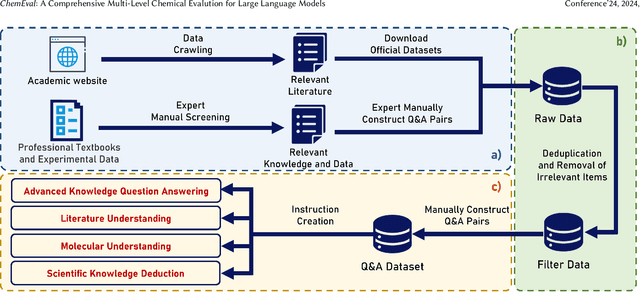


There is a growing interest in the role that LLMs play in chemistry which lead to an increased focus on the development of LLMs benchmarks tailored to chemical domains to assess the performance of LLMs across a spectrum of chemical tasks varying in type and complexity. However, existing benchmarks in this domain fail to adequately meet the specific requirements of chemical research professionals. To this end, we propose \textbf{\textit{ChemEval}}, which provides a comprehensive assessment of the capabilities of LLMs across a wide range of chemical domain tasks. Specifically, ChemEval identified 4 crucial progressive levels in chemistry, assessing 12 dimensions of LLMs across 42 distinct chemical tasks which are informed by open-source data and the data meticulously crafted by chemical experts, ensuring that the tasks have practical value and can effectively evaluate the capabilities of LLMs. In the experiment, we evaluate 12 mainstream LLMs on ChemEval under zero-shot and few-shot learning contexts, which included carefully selected demonstration examples and carefully designed prompts. The results show that while general LLMs like GPT-4 and Claude-3.5 excel in literature understanding and instruction following, they fall short in tasks demanding advanced chemical knowledge. Conversely, specialized LLMs exhibit enhanced chemical competencies, albeit with reduced literary comprehension. This suggests that LLMs have significant potential for enhancement when tackling sophisticated tasks in the field of chemistry. We believe our work will facilitate the exploration of their potential to drive progress in chemistry. Our benchmark and analysis will be available at {\color{blue} \url{https://github.com/USTC-StarTeam/ChemEval}}.
SparkRA: A Retrieval-Augmented Knowledge Service System Based on Spark Large Language Model
Aug 13, 2024
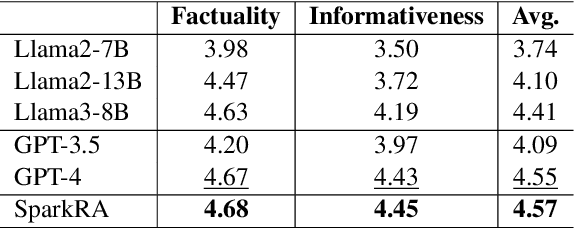

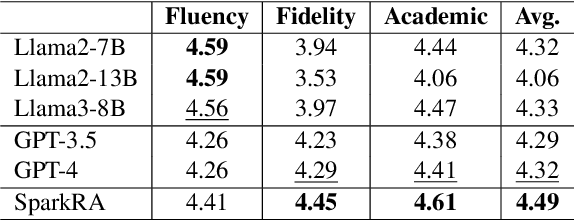
Large language models (LLMs) have shown remarkable achievements across various language tasks.To enhance the performance of LLMs in scientific literature services, we developed the scientific literature LLM (SciLit-LLM) through pre-training and supervised fine-tuning on scientific literature, building upon the iFLYTEK Spark LLM. Furthermore, we present a knowledge service system Spark Research Assistant (SparkRA) based on our SciLit-LLM. SparkRA is accessible online and provides three primary functions: literature investigation, paper reading, and academic writing. As of July 30, 2024, SparkRA has garnered over 50,000 registered users, with a total usage count exceeding 1.3 million.
JiuZhang 2.0: A Unified Chinese Pre-trained Language Model for Multi-task Mathematical Problem Solving
Jun 19, 2023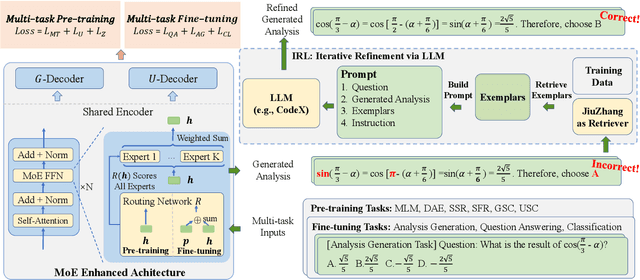
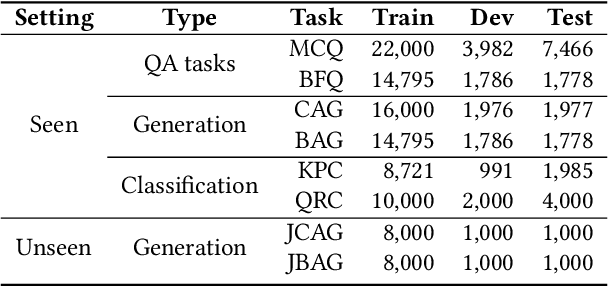
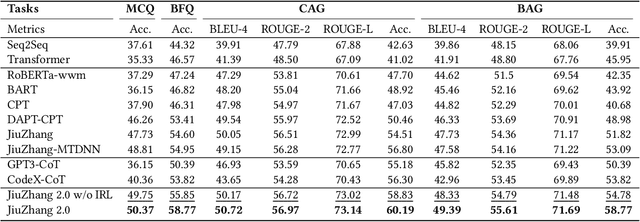
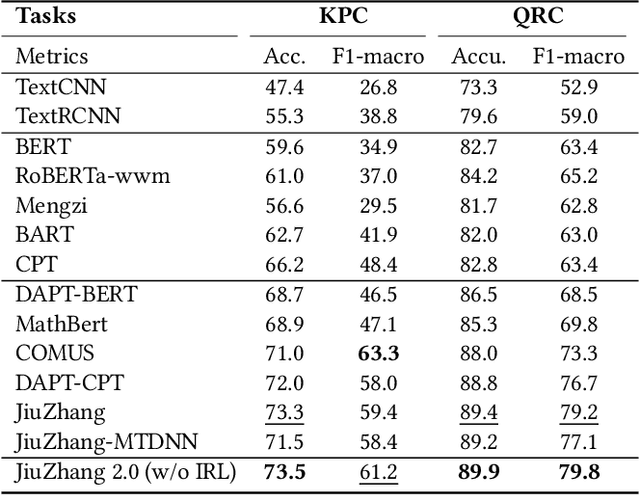
Although pre-trained language models~(PLMs) have recently advanced the research progress in mathematical reasoning, they are not specially designed as a capable multi-task solver, suffering from high cost for multi-task deployment (\eg a model copy for a task) and inferior performance on complex mathematical problems in practical applications. To address these issues, in this paper, we propose \textbf{JiuZhang~2.0}, a unified Chinese PLM specially for multi-task mathematical problem solving. Our idea is to maintain a moderate-sized model and employ the \emph{cross-task knowledge sharing} to improve the model capacity in a multi-task setting. Specially, we construct a Mixture-of-Experts~(MoE) architecture for modeling mathematical text, so as to capture the common mathematical knowledge across tasks. For optimizing the MoE architecture, we design \emph{multi-task continual pre-training} and \emph{multi-task fine-tuning} strategies for multi-task adaptation. These training strategies can effectively decompose the knowledge from the task data and establish the cross-task sharing via expert networks. In order to further improve the general capacity of solving different complex tasks, we leverage large language models~(LLMs) as complementary models to iteratively refine the generated solution by our PLM, via in-context learning. Extensive experiments have demonstrated the effectiveness of our model.
MADNet: Maximizing Addressee Deduction Expectation for Multi-Party Conversation Generation
May 22, 2023Modeling multi-party conversations (MPCs) with graph neural networks has been proven effective at capturing complicated and graphical information flows. However, existing methods rely heavily on the necessary addressee labels and can only be applied to an ideal setting where each utterance must be tagged with an addressee label. To study the scarcity of addressee labels which is a common issue in MPCs, we propose MADNet that maximizes addressee deduction expectation in heterogeneous graph neural networks for MPC generation. Given an MPC with a few addressee labels missing, existing methods fail to build a consecutively connected conversation graph, but only a few separate conversation fragments instead. To ensure message passing between these conversation fragments, four additional types of latent edges are designed to complete a fully-connected graph. Besides, to optimize the edge-type-dependent message passing for those utterances without addressee labels, an Expectation-Maximization-based method that iteratively generates silver addressee labels (E step), and optimizes the quality of generated responses (M step), is designed. Experimental results on two Ubuntu IRC channel benchmarks show that MADNet outperforms various baseline models on the task of MPC generation, especially under the more common and challenging setting where part of addressee labels are missing.
SHINE: Syntax-augmented Hierarchical Interactive Encoder for Zero-shot Cross-lingual Information Extraction
May 21, 2023Zero-shot cross-lingual information extraction(IE) aims at constructing an IE model for some low-resource target languages, given annotations exclusively in some rich-resource languages. Recent studies based on language-universal features have shown their effectiveness and are attracting increasing attention. However, prior work has neither explored the potential of establishing interactions between language-universal features and contextual representations nor incorporated features that can effectively model constituent span attributes and relationships between multiple spans. In this study, a syntax-augmented hierarchical interactive encoder (SHINE) is proposed to transfer cross-lingual IE knowledge. The proposed encoder is capable of interactively capturing complementary information between features and contextual information, to derive language-agnostic representations for various IE tasks. Concretely, a multi-level interaction network is designed to hierarchically interact the complementary information to strengthen domain adaptability. Besides, in addition to the well-studied syntax features of part-of-speech and dependency relation, a new syntax feature of constituency structure is introduced to model the constituent span information which is crucial for IE. Experiments across seven languages on three IE tasks and four benchmarks verify the effectiveness and generalization ability of the proposed method.