 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSportsSum2.0: Generating High-Quality Sports News from Live Text Commentary
Oct 12, 2021
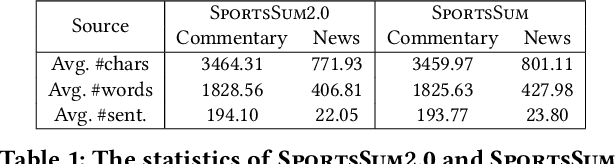
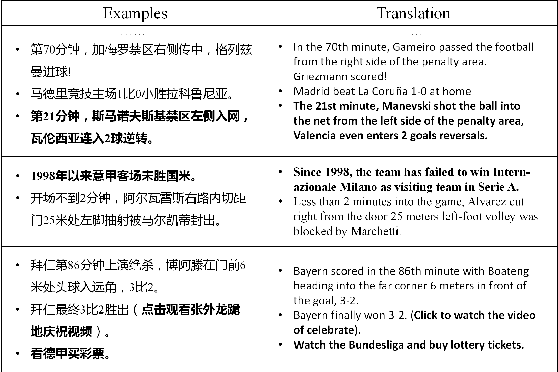

Sports game summarization aims to generate news articles from live text commentaries. A recent state-of-the-art work, SportsSum, not only constructs a large benchmark dataset, but also proposes a two-step framework. Despite its great contributions, the work has three main drawbacks: 1) the noise existed in SportsSum dataset degrades the summarization performance; 2) the neglect of lexical overlap between news and commentaries results in low-quality pseudo-labeling algorithm; 3) the usage of directly concatenating rewritten sentences to form news limits its practicability. In this paper, we publish a new benchmark dataset SportsSum2.0, together with a modified summarization framework. In particular, to obtain a clean dataset, we employ crowd workers to manually clean the original dataset. Moreover, the degree of lexical overlap is incorporated into the generation of pseudo labels. Further, we introduce a reranker-enhanced summarizer to take into account the fluency and expressiveness of the summarized news. Extensive experiments show that our model outperforms the state-of-the-art baseline.
Multi-Modal Chorus Recognition for Improving Song Search
Jun 27, 2021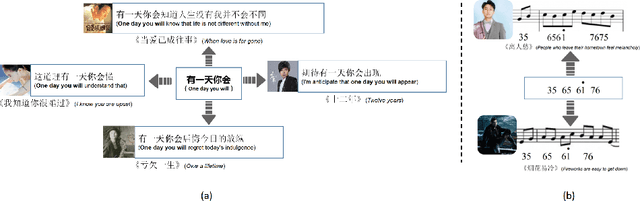
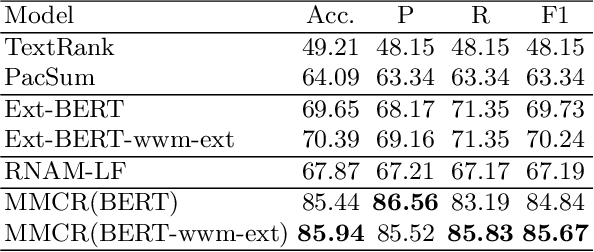
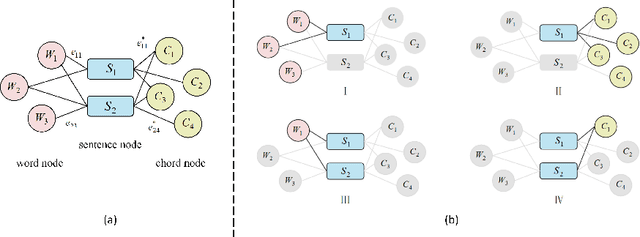

We discuss a novel task, Chorus Recognition, which could potentially benefit downstream tasks such as song search and music summarization. Different from the existing tasks such as music summarization or lyrics summarization relying on single-modal information, this paper models chorus recognition as a multi-modal one by utilizing both the lyrics and the tune information of songs. We propose a multi-modal Chorus Recognition model that considers diverse features. Besides, we also create and publish the first Chorus Recognition dataset containing 627 songs for public use. Our empirical study performed on the dataset demonstrates that our approach outperforms several baselines in chorus recognition. In addition, our approach also helps to improve the accuracy of its downstream task - song search by more than 10.6%.