 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Dynamic Clustering: Capturing Patterns from Historical Cluster Evolution
Mar 07, 2022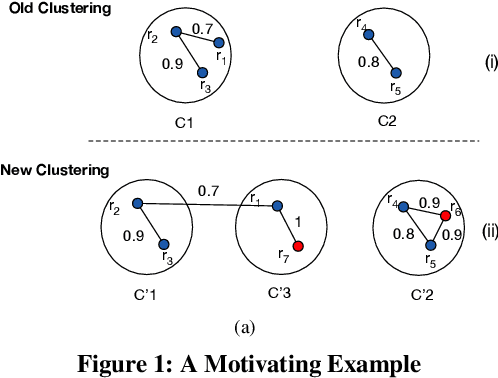

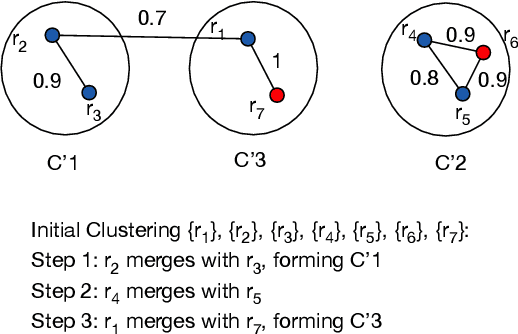
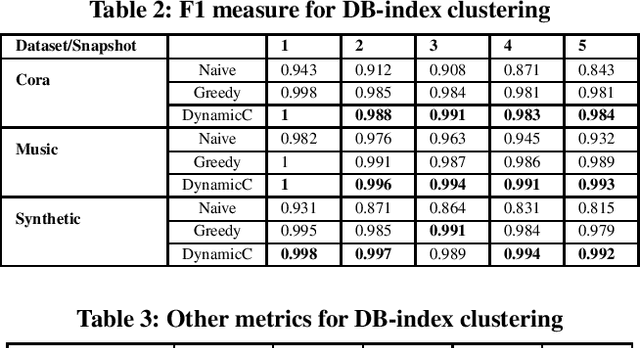
Clustering aims to group unlabeled objects based on similarity inherent among them into clusters. It is important for many tasks such as anomaly detection, database sharding, record linkage, and others. Some clustering methods are taken as batch algorithms that incur a high overhead as they cluster all the objects in the database from scratch or assume an incremental workload. In practice, database objects are updated, added, and removed from databases continuously which makes previous results stale. Running batch algorithms is infeasible in such scenarios as it would incur a significant overhead if performed continuously. This is particularly the case for high-velocity scenarios such as ones in Internet of Things applications. In this paper, we tackle the problem of clustering in high-velocity dynamic scenarios, where the objects are continuously updated, inserted, and deleted. Specifically, we propose a generally dynamic approach to clustering that utilizes previous clustering results. Our system, DynamicC, uses a machine learning model that is augmented with an existing batch algorithm. The DynamicC model trains by observing the clustering decisions made by the batch algorithm. After training, the DynamicC model is usedin cooperation with the batch algorithm to achieve both accurate and fast clustering decisions. The experimental results on four real-world and one synthetic datasets show that our approach has a better performance compared to the state-of-the-art method while achieving similarly accurate clustering results to the baseline batch algorithm.
Multi-Modal Chorus Recognition for Improving Song Search
Jun 27, 2021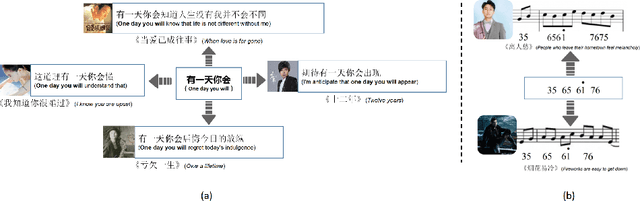
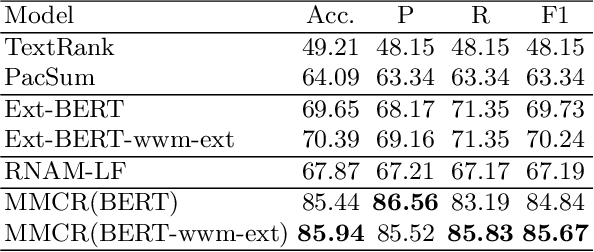
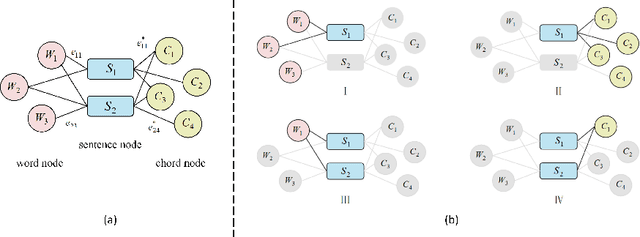

We discuss a novel task, Chorus Recognition, which could potentially benefit downstream tasks such as song search and music summarization. Different from the existing tasks such as music summarization or lyrics summarization relying on single-modal information, this paper models chorus recognition as a multi-modal one by utilizing both the lyrics and the tune information of songs. We propose a multi-modal Chorus Recognition model that considers diverse features. Besides, we also create and publish the first Chorus Recognition dataset containing 627 songs for public use. Our empirical study performed on the dataset demonstrates that our approach outperforms several baselines in chorus recognition. In addition, our approach also helps to improve the accuracy of its downstream task - song search by more than 10.6%.