 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Dynamic Clustering: Capturing Patterns from Historical Cluster Evolution
Mar 07, 2022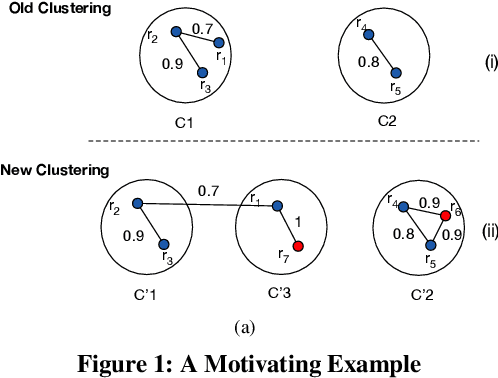

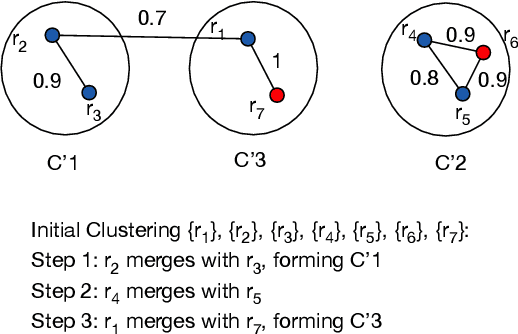
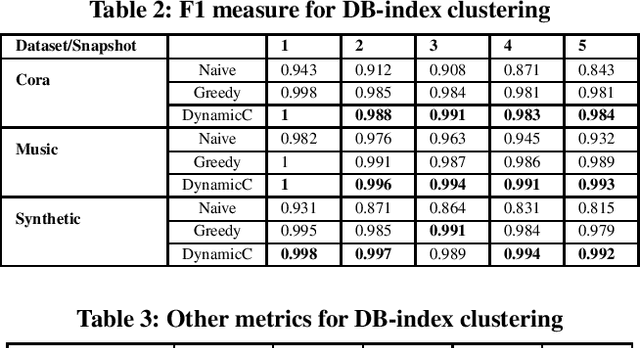
Clustering aims to group unlabeled objects based on similarity inherent among them into clusters. It is important for many tasks such as anomaly detection, database sharding, record linkage, and others. Some clustering methods are taken as batch algorithms that incur a high overhead as they cluster all the objects in the database from scratch or assume an incremental workload. In practice, database objects are updated, added, and removed from databases continuously which makes previous results stale. Running batch algorithms is infeasible in such scenarios as it would incur a significant overhead if performed continuously. This is particularly the case for high-velocity scenarios such as ones in Internet of Things applications. In this paper, we tackle the problem of clustering in high-velocity dynamic scenarios, where the objects are continuously updated, inserted, and deleted. Specifically, we propose a generally dynamic approach to clustering that utilizes previous clustering results. Our system, DynamicC, uses a machine learning model that is augmented with an existing batch algorithm. The DynamicC model trains by observing the clustering decisions made by the batch algorithm. After training, the DynamicC model is usedin cooperation with the batch algorithm to achieve both accurate and fast clustering decisions. The experimental results on four real-world and one synthetic datasets show that our approach has a better performance compared to the state-of-the-art method while achieving similarly accurate clustering results to the baseline batch algorithm.
Croesus: Multi-Stage Processing and Transactions for Video-Analytics in Edge-Cloud Systems
Dec 31, 2021
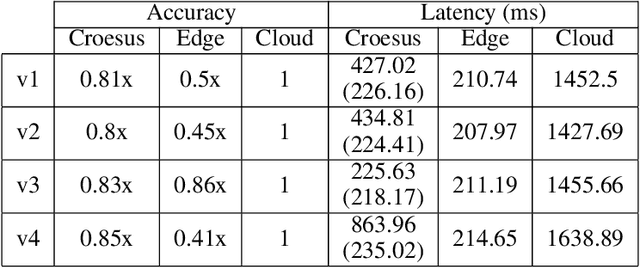


Emerging edge applications require both a fast response latency and complex processing. This is infeasible without expensive hardware that can process complex operations -- such as object detection -- within a short time. Many approach this problem by addressing the complexity of the models -- via model compression, pruning and quantization -- or compressing the input. In this paper, we propose a different perspective when addressing the performance challenges. Croesus is a multi-stage approach to edge-cloud systems that provides the ability to find the balance between accuracy and performance. Croesus consists of two stages (that can be generalized to multiple stages): an initial and a final stage. The initial stage performs the computation in real-time using approximate/best-effort computation at the edge. The final stage performs the full computation at the cloud, and uses the results to correct any errors made at the initial stage. In this paper, we demonstrate the implications of such an approach on a video analytics use-case and show how multi-stage processing yields a better balance between accuracy and performance. Moreover, we study the safety of multi-stage transactions via two proposals: multi-stage serializability (MS-SR) and multi-stage invariant confluence with Apologies (MS-IA).
A Survey of Open Source User Activity Traces with Applications to User Mobility Characterization and Modeling
Oct 15, 2021
The current state-of-the-art in user mobility research has extensively relied on open-source mobility traces captured from pedestrian and vehicular activity through a variety of communication technologies as users engage in a wide-range of applications, including connected healthcare, localization, social media, e-commerce, etc. Most of these traces are feature-rich and diverse, not only in the information they provide, but also in how they can be used and leveraged. This diversity poses two main challenges for researchers and practitioners who wish to make use of available mobility datasets. First, it is quite difficult to get a bird's eye view of the available traces without spending considerable time looking them up. Second, once they have found the traces, they still need to figure out whether the traces are adequate to their needs. The purpose of this survey is three-fold. It proposes a taxonomy to classify open-source mobility traces including their mobility mode, data source and collection technology. It then uses the proposed taxonomy to classify existing open-source mobility traces and finally, highlights three case studies using popular publicly available datasets to showcase how our taxonomy can tease out feature sets in traces to help determine their applicability to specific use-cases.
Predict and Write: Using K-Means Clustering to Extend the Lifetime of NVM Storage
Nov 04, 2020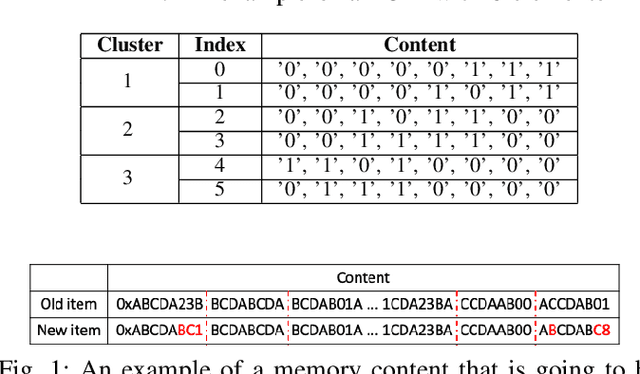
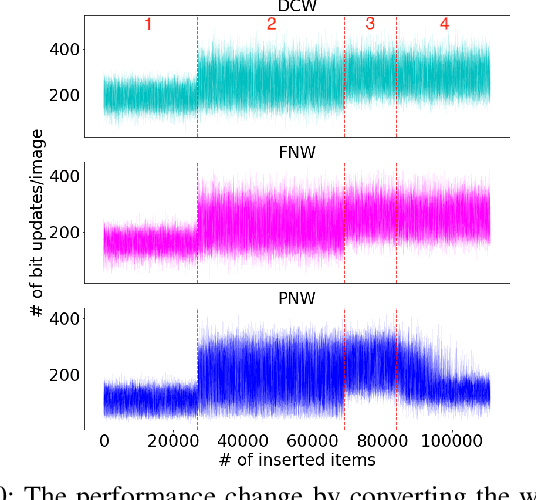
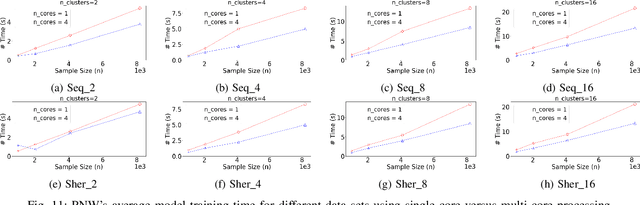
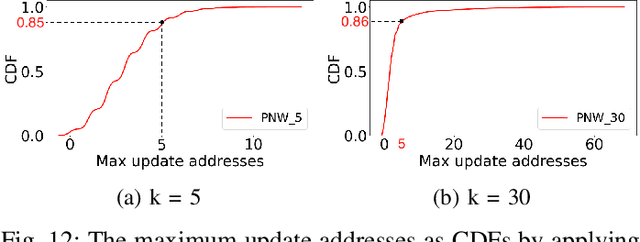
Non-volatile memory (NVM) technologies suffer from limited write endurance. To address this challenge, we propose Predict and Write (PNW), a K/V-store that uses a clustering-based machine learning approach to extend the lifetime of NVMs. PNW decreases the number of bit flips for PUT/UPDATE operations by determining the best memory location an updated value should be written to. PNW leverages the indirection level of K/V-stores to freely choose the target memory location for any given write based on its value. PNW organizes NVM addresses in a dynamic address pool clustered by the similarity of the data values they refer to. We show that, by choosing the right target memory location for a given PUT/UPDATE operation, the number of total bit flips and cache lines can be reduced by up to 85% and 56% over the state of the art.