 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Dynamic Clustering: Capturing Patterns from Historical Cluster Evolution
Mar 07, 2022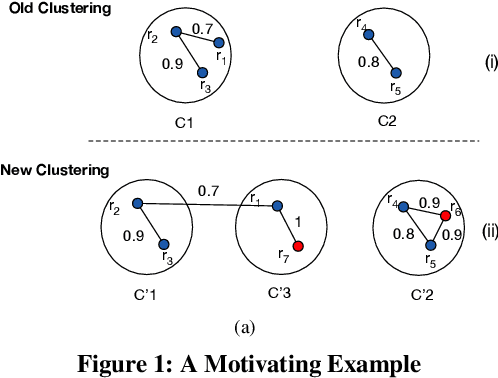

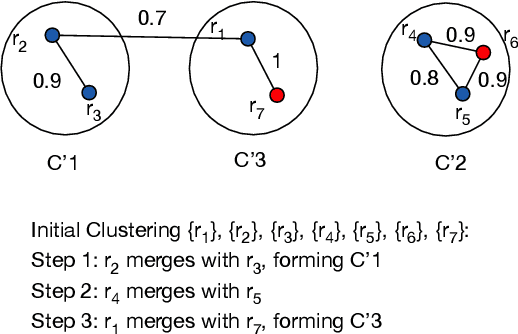
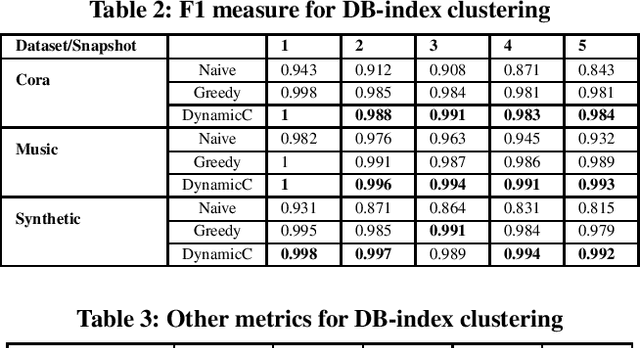
Clustering aims to group unlabeled objects based on similarity inherent among them into clusters. It is important for many tasks such as anomaly detection, database sharding, record linkage, and others. Some clustering methods are taken as batch algorithms that incur a high overhead as they cluster all the objects in the database from scratch or assume an incremental workload. In practice, database objects are updated, added, and removed from databases continuously which makes previous results stale. Running batch algorithms is infeasible in such scenarios as it would incur a significant overhead if performed continuously. This is particularly the case for high-velocity scenarios such as ones in Internet of Things applications. In this paper, we tackle the problem of clustering in high-velocity dynamic scenarios, where the objects are continuously updated, inserted, and deleted. Specifically, we propose a generally dynamic approach to clustering that utilizes previous clustering results. Our system, DynamicC, uses a machine learning model that is augmented with an existing batch algorithm. The DynamicC model trains by observing the clustering decisions made by the batch algorithm. After training, the DynamicC model is usedin cooperation with the batch algorithm to achieve both accurate and fast clustering decisions. The experimental results on four real-world and one synthetic datasets show that our approach has a better performance compared to the state-of-the-art method while achieving similarly accurate clustering results to the baseline batch algorithm.
Predict and Write: Using K-Means Clustering to Extend the Lifetime of NVM Storage
Nov 04, 2020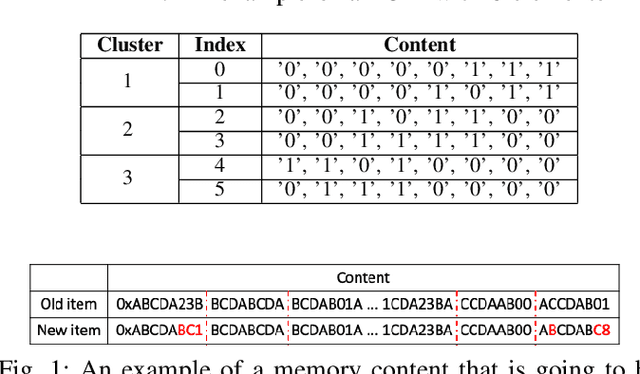
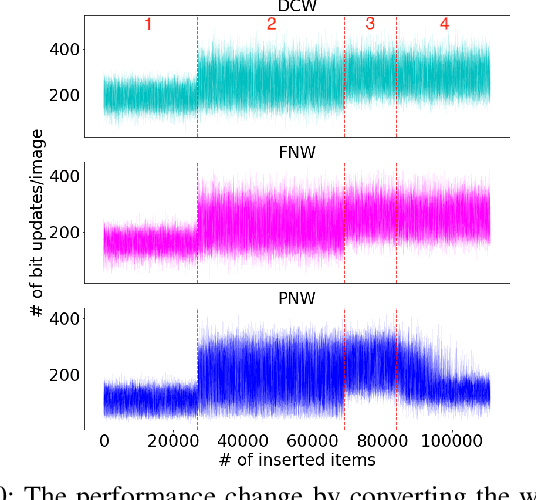
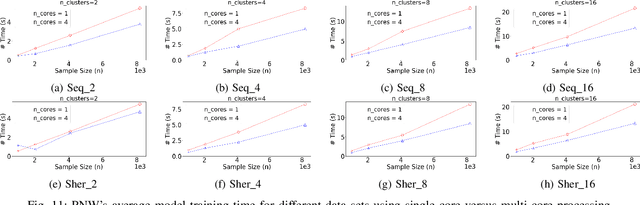
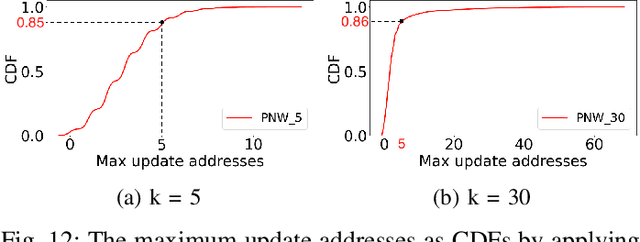
Non-volatile memory (NVM) technologies suffer from limited write endurance. To address this challenge, we propose Predict and Write (PNW), a K/V-store that uses a clustering-based machine learning approach to extend the lifetime of NVMs. PNW decreases the number of bit flips for PUT/UPDATE operations by determining the best memory location an updated value should be written to. PNW leverages the indirection level of K/V-stores to freely choose the target memory location for any given write based on its value. PNW organizes NVM addresses in a dynamic address pool clustered by the similarity of the data values they refer to. We show that, by choosing the right target memory location for a given PUT/UPDATE operation, the number of total bit flips and cache lines can be reduced by up to 85% and 56% over the state of the art.