 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommCP: Efficient Multi-Agent Coordination via LLM-Based Communication with Conformal Prediction
Feb 05, 2026To complete assignments provided by humans in natural language, robots must interpret commands, generate and answer relevant questions for scene understanding, and manipulate target objects. Real-world deployments often require multiple heterogeneous robots with different manipulation capabilities to handle different assignments cooperatively. Beyond the need for specialized manipulation skills, effective information gathering is important in completing these assignments. To address this component of the problem, we formalize the information-gathering process in a fully cooperative setting as an underexplored multi-agent multi-task Embodied Question Answering (MM-EQA) problem, which is a novel extension of canonical Embodied Question Answering (EQA), where effective communication is crucial for coordinating efforts without redundancy. To address this problem, we propose CommCP, a novel LLM-based decentralized communication framework designed for MM-EQA. Our framework employs conformal prediction to calibrate the generated messages, thereby minimizing receiver distractions and enhancing communication reliability. To evaluate our framework, we introduce an MM-EQA benchmark featuring diverse, photo-realistic household scenarios with embodied questions. Experimental results demonstrate that CommCP significantly enhances the task success rate and exploration efficiency over baselines. The experiment videos, code, and dataset are available on our project website: https://comm-cp.github.io.
Lean and Mean: Decoupled Value Policy Optimization with Global Value Guidance
Feb 24, 2025Proximal Policy Optimization (PPO)-based Reinforcement Learning from Human Feedback (RLHF) is essential for aligning large language models (LLMs) with human preferences. It requires joint training of an actor and critic with a pretrained, fixed reward model for guidance. This approach increases computational complexity and instability due to actor-critic interdependence. Additionally, PPO lacks access to true environment rewards in LLM tasks, limiting its adaptability. Under such conditions, pretraining a value model or a reward model becomes equivalent, as both provide fixed supervisory signals without new ground-truth feedback. To address these issues, we propose \textbf{Decoupled Value Policy Optimization (DVPO)}, a lean framework that replaces traditional reward modeling with a pretrained \emph{global value model (GVM)}. The GVM is conditioned on policy trajectories and predicts token-level return-to-go estimates. By decoupling value model from policy training (via frozen GVM-driven RL objectives), DVPO eliminates actor-critic interdependence, reducing GPU memory usage by 40\% and training time by 35\% compared to conventional RLHF. Experiments across benchmarks show DVPO outperforms efficient RLHF methods (e.g., DPO) while matching state-of-the-art PPO in performance.
Evaluating Semantic Variation in Text-to-Image Synthesis: A Causal Perspective
Oct 14, 2024
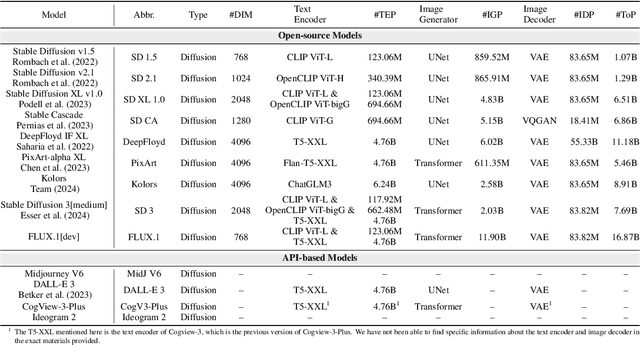
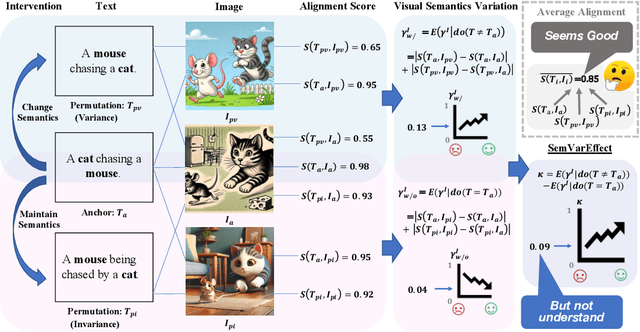
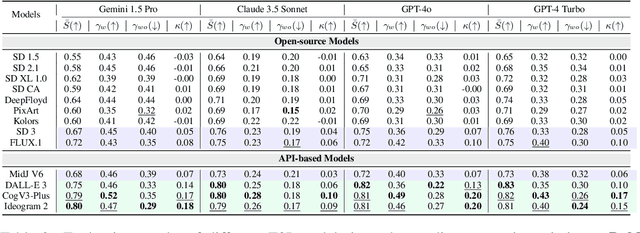
Accurate interpretation and visualization of human instructions are crucial for text-to-image (T2I) synthesis. However, current models struggle to capture semantic variations from word order changes, and existing evaluations, relying on indirect metrics like text-image similarity, fail to reliably assess these challenges. This often obscures poor performance on complex or uncommon linguistic patterns by the focus on frequent word combinations. To address these deficiencies, we propose a novel metric called SemVarEffect and a benchmark named SemVarBench, designed to evaluate the causality between semantic variations in inputs and outputs in T2I synthesis. Semantic variations are achieved through two types of linguistic permutations, while avoiding easily predictable literal variations. Experiments reveal that the CogView-3-Plus and Ideogram 2 performed the best, achieving a score of 0.2/1. Semantic variations in object relations are less understood than attributes, scoring 0.07/1 compared to 0.17-0.19/1. We found that cross-modal alignment in UNet or Transformers plays a crucial role in handling semantic variations, a factor previously overlooked by a focus on textual encoders. Our work establishes an effective evaluation framework that advances the T2I synthesis community's exploration of human instruction understanding.
Incorporating Like-Minded Peers to Overcome Friend Data Sparsity in Session-Based Social Recommendations
Sep 04, 2024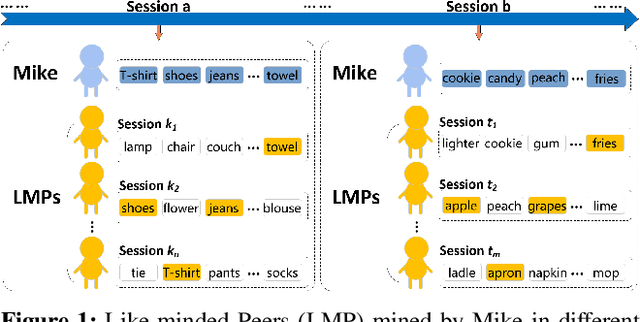
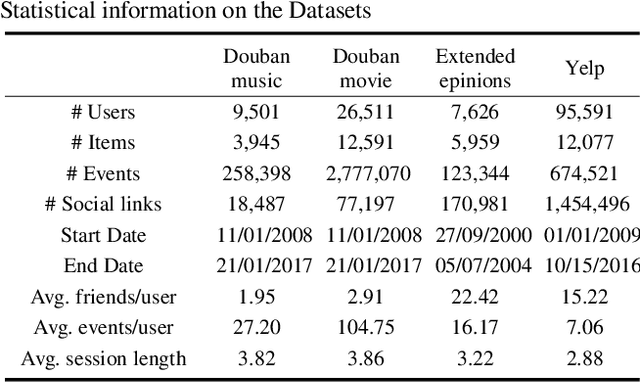
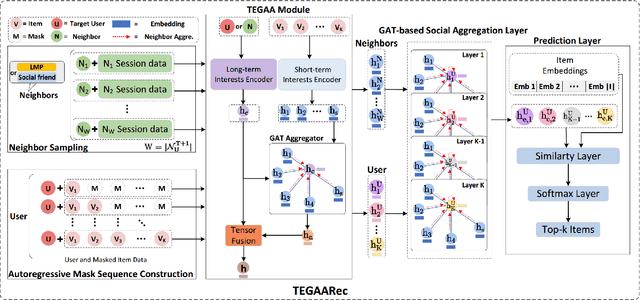

Session-based Social Recommendation (SSR) leverages social relationships within online networks to enhance the performance of Session-based Recommendation (SR). However, existing SSR algorithms often encounter the challenge of ``friend data sparsity''. Moreover, significant discrepancies can exist between the purchase preferences of social network friends and those of the target user, reducing the influence of friends relative to the target user's own preferences. To address these challenges, this paper introduces the concept of ``Like-minded Peers'' (LMP), representing users whose preferences align with the target user's current session based on their historical sessions. This is the first work, to our knowledge, that uses LMP to enhance the modeling of social influence in SSR. This approach not only alleviates the problem of friend data sparsity but also effectively incorporates users with similar preferences to the target user. We propose a novel model named Transformer Encoder with Graph Attention Aggregator Recommendation (TEGAARec), which includes the TEGAA module and the GAT-based social aggregation module. The TEGAA module captures and merges both long-term and short-term interests for target users and LMP users. Concurrently, the GAT-based social aggregation module is designed to aggregate the target users' dynamic interests and social influence in a weighted manner. Extensive experiments on four real-world datasets demonstrate the efficacy and superiority of our proposed model and ablation studies are done to illustrate the contributions of each component in TEGAARec.
XMeCap: Meme Caption Generation with Sub-Image Adaptability
Jul 24, 2024



Humor, deeply rooted in societal meanings and cultural details, poses a unique challenge for machines. While advances have been made in natural language processing, real-world humor often thrives in a multi-modal context, encapsulated distinctively by memes. This paper poses a particular emphasis on the impact of multi-images on meme captioning. After that, we introduce the \textsc{XMeCap} framework, a novel approach that adopts supervised fine-tuning and reinforcement learning based on an innovative reward model, which factors in both global and local similarities between visuals and text. Our results, benchmarked against contemporary models, manifest a marked improvement in caption generation for both single-image and multi-image memes, as well as different meme categories. \textsc{XMeCap} achieves an average evaluation score of 75.85 for single-image memes and 66.32 for multi-image memes, outperforming the best baseline by 3.71\% and 4.82\%, respectively. This research not only establishes a new frontier in meme-related studies but also underscores the potential of machines in understanding and generating humor in a multi-modal setting.
Can Pre-trained Language Models Understand Chinese Humor?
Jul 04, 2024



Humor understanding is an important and challenging research in natural language processing. As the popularity of pre-trained language models (PLMs), some recent work makes preliminary attempts to adopt PLMs for humor recognition and generation. However, these simple attempts do not substantially answer the question: {\em whether PLMs are capable of humor understanding?} This paper is the first work that systematically investigates the humor understanding ability of PLMs. For this purpose, a comprehensive framework with three evaluation steps and four evaluation tasks is designed. We also construct a comprehensive Chinese humor dataset, which can fully meet all the data requirements of the proposed evaluation framework. Our empirical study on the Chinese humor dataset yields some valuable observations, which are of great guiding value for future optimization of PLMs in humor understanding and generation.
Hallucination Detection: Robustly Discerning Reliable Answers in Large Language Models
Jul 04, 2024Large Language Models (LLMs) have gained widespread adoption in various natural language processing tasks, including question answering and dialogue systems. However, a major drawback of LLMs is the issue of hallucination, where they generate unfaithful or inconsistent content that deviates from the input source, leading to severe consequences. In this paper, we propose a robust discriminator named RelD to effectively detect hallucination in LLMs' generated answers. RelD is trained on the constructed RelQA, a bilingual question-answering dialogue dataset along with answers generated by LLMs and a comprehensive set of metrics. Our experimental results demonstrate that the proposed RelD successfully detects hallucination in the answers generated by diverse LLMs. Moreover, it performs well in distinguishing hallucination in LLMs' generated answers from both in-distribution and out-of-distribution datasets. Additionally, we also conduct a thorough analysis of the types of hallucinations that occur and present valuable insights. This research significantly contributes to the detection of reliable answers generated by LLMs and holds noteworthy implications for mitigating hallucination in the future work.
MAPO: Boosting Large Language Model Performance with Model-Adaptive Prompt Optimization
Jul 04, 2024



Prompt engineering, as an efficient and effective way to leverage Large Language Models (LLM), has drawn a lot of attention from the research community. The existing research primarily emphasizes the importance of adapting prompts to specific tasks, rather than specific LLMs. However, a good prompt is not solely defined by its wording, but also binds to the nature of the LLM in question. In this work, we first quantitatively demonstrate that different prompts should be adapted to different LLMs to enhance their capabilities across various downstream tasks in NLP. Then we novelly propose a model-adaptive prompt optimizer (MAPO) method that optimizes the original prompts for each specific LLM in downstream tasks. Extensive experiments indicate that the proposed method can effectively refine prompts for an LLM, leading to significant improvements over various downstream tasks.
Multi-Task Domain Adaptation for Language Grounding with 3D Objects
Jul 03, 2024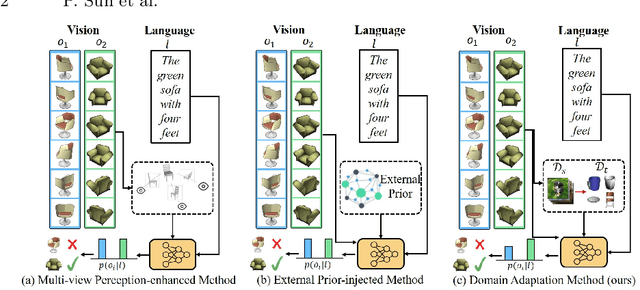
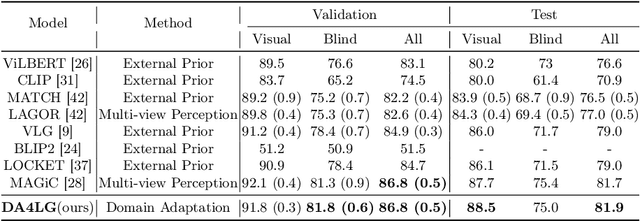
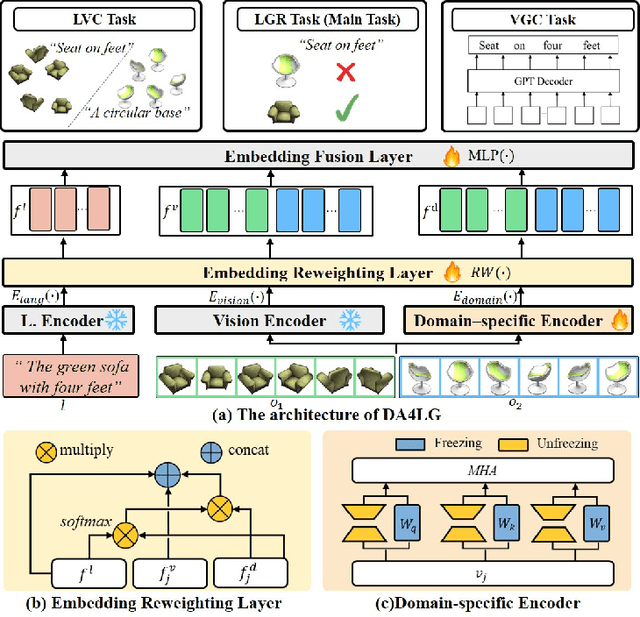
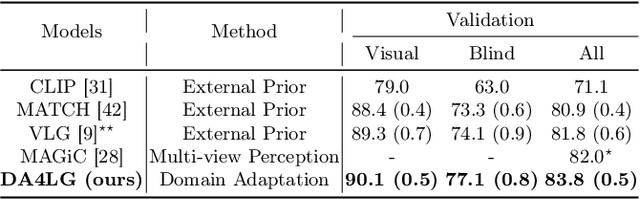
The existing works on object-level language grounding with 3D objects mostly focus on improving performance by utilizing the off-the-shelf pre-trained models to capture features, such as viewpoint selection or geometric priors. However, they have failed to consider exploring the cross-modal representation of language-vision alignment in the cross-domain field. To answer this problem, we propose a novel method called Domain Adaptation for Language Grounding (DA4LG) with 3D objects. Specifically, the proposed DA4LG consists of a visual adapter module with multi-task learning to realize vision-language alignment by comprehensive multimodal feature representation. Experimental results demonstrate that DA4LG competitively performs across visual and non-visual language descriptions, independent of the completeness of observation. DA4LG achieves state-of-the-art performance in the single-view setting and multi-view setting with the accuracy of 83.8% and 86.8% respectively in the language grounding benchmark SNARE. The simulation experiments show the well-practical and generalized performance of DA4LG compared to the existing methods. Our project is available at https://sites.google.com/view/da4lg.
ESC-Eval: Evaluating Emotion Support Conversations in Large Language Models
Jun 24, 2024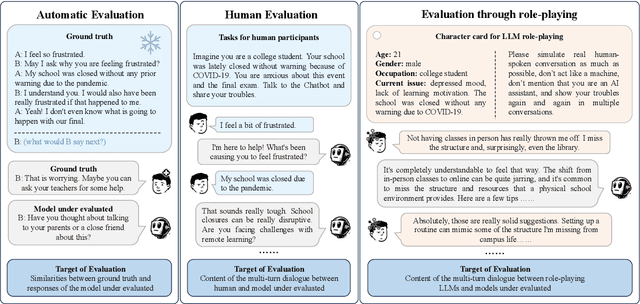
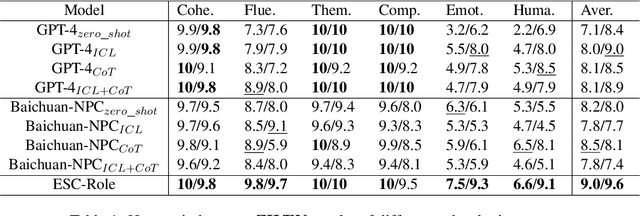
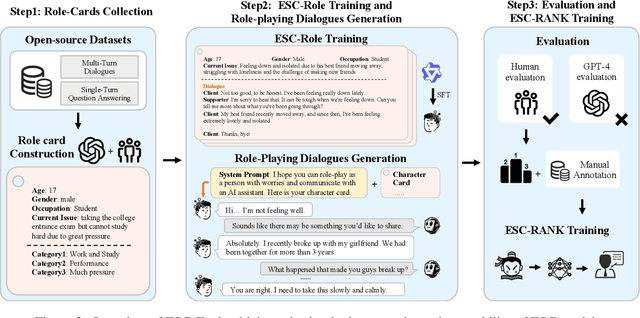
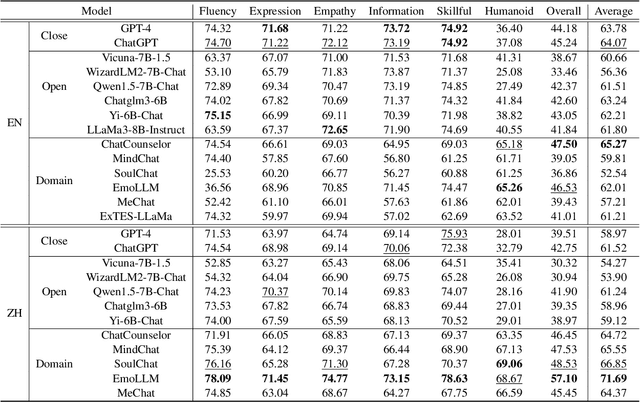
Emotion Support Conversation (ESC) is a crucial application, which aims to reduce human stress, offer emotional guidance, and ultimately enhance human mental and physical well-being. With the advancement of Large Language Models (LLMs), many researchers have employed LLMs as the ESC models. However, the evaluation of these LLM-based ESCs remains uncertain. Inspired by the awesome development of role-playing agents, we propose an ESC Evaluation framework (ESC-Eval), which uses a role-playing agent to interact with ESC models, followed by a manual evaluation of the interactive dialogues. In detail, we first re-organize 2,801 role-playing cards from seven existing datasets to define the roles of the role-playing agent. Second, we train a specific role-playing model called ESC-Role which behaves more like a confused person than GPT-4. Third, through ESC-Role and organized role cards, we systematically conduct experiments using 14 LLMs as the ESC models, including general AI-assistant LLMs (ChatGPT) and ESC-oriented LLMs (ExTES-Llama). We conduct comprehensive human annotations on interactive multi-turn dialogues of different ESC models. The results show that ESC-oriented LLMs exhibit superior ESC abilities compared to general AI-assistant LLMs, but there is still a gap behind human performance. Moreover, to automate the scoring process for future ESC models, we developed ESC-RANK, which trained on the annotated data, achieving a scoring performance surpassing 35 points of GPT-4. Our data and code are available at https://github.com/haidequanbu/ESC-Eval.