 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Semantic Variation in Text-to-Image Synthesis: A Causal Perspective
Oct 14, 2024
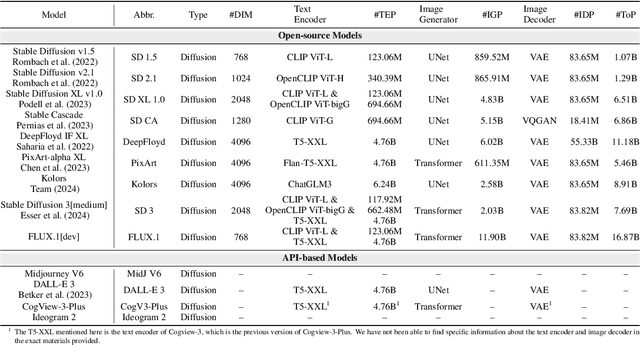
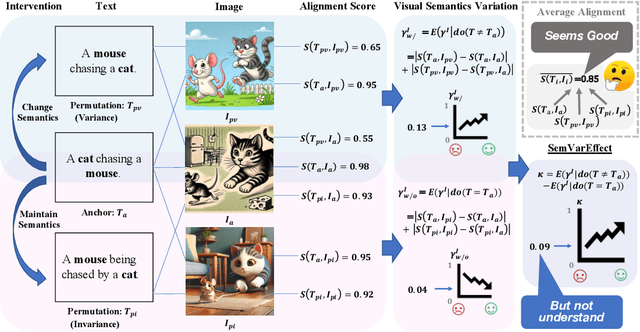
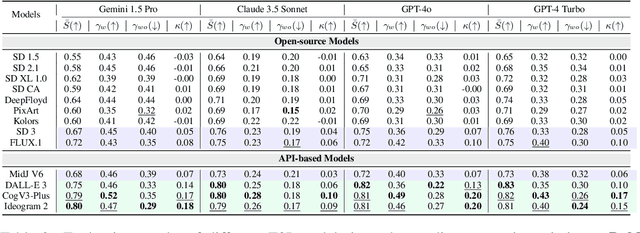
Accurate interpretation and visualization of human instructions are crucial for text-to-image (T2I) synthesis. However, current models struggle to capture semantic variations from word order changes, and existing evaluations, relying on indirect metrics like text-image similarity, fail to reliably assess these challenges. This often obscures poor performance on complex or uncommon linguistic patterns by the focus on frequent word combinations. To address these deficiencies, we propose a novel metric called SemVarEffect and a benchmark named SemVarBench, designed to evaluate the causality between semantic variations in inputs and outputs in T2I synthesis. Semantic variations are achieved through two types of linguistic permutations, while avoiding easily predictable literal variations. Experiments reveal that the CogView-3-Plus and Ideogram 2 performed the best, achieving a score of 0.2/1. Semantic variations in object relations are less understood than attributes, scoring 0.07/1 compared to 0.17-0.19/1. We found that cross-modal alignment in UNet or Transformers plays a crucial role in handling semantic variations, a factor previously overlooked by a focus on textual encoders. Our work establishes an effective evaluation framework that advances the T2I synthesis community's exploration of human instruction understanding.
M2ConceptBase: A Fine-grained Aligned Multi-modal Conceptual Knowledge Base
Dec 16, 2023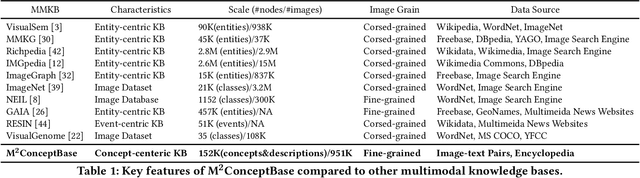
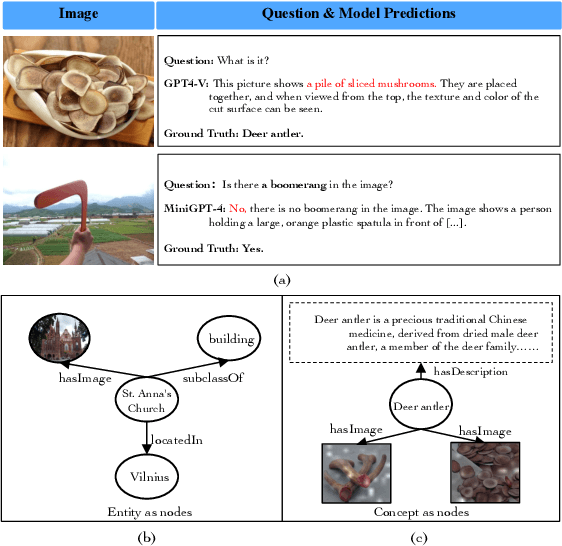
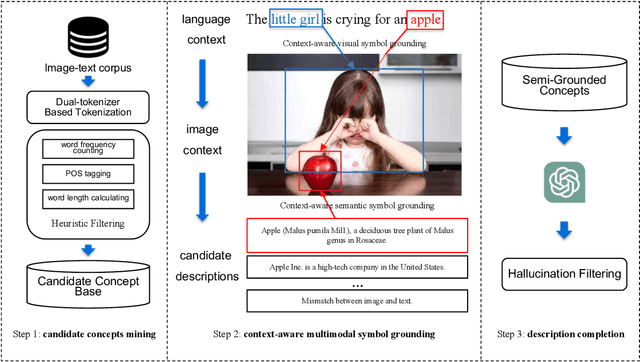

Large multi-modal models (LMMs) have demonstrated promising intelligence owing to the rapid development of pre-training techniques. However, their fine-grained cross-modal alignment ability is constrained by the coarse alignment in image-text pairs. This limitation hinders awareness of fine-grained concepts, resulting in sub-optimal performance. In this paper, we propose a multi-modal conceptual knowledge base, named M2ConceptBase, which aims to provide fine-grained alignment between images and concepts. Specifically, M2ConceptBase models concepts as nodes, associating each with relevant images and detailed text, thereby enhancing LMMs' cross-modal alignment with rich conceptual knowledge. To collect concept-image and concept-description alignments, we propose a context-aware multi-modal symbol grounding approach that considers context information in existing large-scale image-text pairs with respect to each concept. A cutting-edge large language model supplements descriptions for concepts not grounded via our symbol grounding approach. Finally, our M2ConceptBase contains more than 951K images and 152K concepts, each associating with an average of 6.27 images and a single detailed description. We conduct experiments on the OK-VQA task, demonstrating that our M2ConceptBase facilitates the model in achieving state-of-the-art performance. Moreover, we construct a comprehensive benchmark to evaluate the concept understanding of LMMs and show that M2ConceptBase could effectively improve LMMs' concept understanding and cross-modal alignment abilities.
A Contrastive Compositional Benchmark for Text-to-Image Synthesis: A Study with Unified Text-to-Image Fidelity Metrics
Dec 04, 2023Text-to-image (T2I) synthesis has recently achieved significant advancements. However, challenges remain in the model's compositionality, which is the ability to create new combinations from known components. We introduce Winoground-T2I, a benchmark designed to evaluate the compositionality of T2I models. This benchmark includes 11K complex, high-quality contrastive sentence pairs spanning 20 categories. These contrastive sentence pairs with subtle differences enable fine-grained evaluations of T2I synthesis models. Additionally, to address the inconsistency across different metrics, we propose a strategy that evaluates the reliability of various metrics by using comparative sentence pairs. We use Winoground-T2I with a dual objective: to evaluate the performance of T2I models and the metrics used for their evaluation. Finally, we provide insights into the strengths and weaknesses of these metrics and the capabilities of current T2I models in tackling challenges across a range of complex compositional categories. Our benchmark is publicly available at https://github.com/zhuxiangru/Winoground-T2I .
Multi-Modal Knowledge Graph Construction and Application: A Survey
Feb 11, 2022



Recent years have witnessed the resurgence of knowledge engineering which is featured by the fast growth of knowledge graphs. However, most of existing knowledge graphs are represented with pure symbols, which hurts the machine's capability to understand the real world. The multi-modalization of knowledge graphs is an inevitable key step towards the realization of human-level machine intelligence. The results of this endeavor are Multi-modal Knowledge Graphs (MMKGs). In this survey on MMKGs constructed by texts and images, we first give definitions of MMKGs, followed with the preliminaries on multi-modal tasks and techniques. We then systematically review the challenges, progresses and opportunities on the construction and application of MMKGs respectively, with detailed analyses of the strength and weakness of different solutions. We finalize this survey with open research problems relevant to MMKGs.