 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Vision-Language Navigation with Multimodal Event Knowledge from Real-World Indoor Tour Videos
Feb 27, 2026Vision-Language Navigation (VLN) agents often struggle with long-horizon reasoning in unseen environments, particularly when facing ambiguous, coarse-grained instructions. While recent advances use knowledge graph to enhance reasoning, the potential of multimodal event knowledge inspired by human episodic memory remains underexplored. In this work, we propose an event-centric knowledge enhancement strategy for automated process knowledge mining and feature fusion to solve coarse-grained instruction and long-horizon reasoning in VLN task. First, we construct YE-KG, the first large-scale multimodal spatiotemporal knowledge graph, with over 86k nodes and 83k edges, derived from real-world indoor videos. By leveraging multimodal large language models (i.e., LLaVa, GPT4), we extract unstructured video streams into structured semantic-action-effect events to serve as explicit episodic memory. Second, we introduce STE-VLN, which integrates the above graph into VLN models via a Coarse-to-Fine Hierarchical Retrieval mechanism. This allows agents to retrieve causal event sequences and dynamically fuse them with egocentric visual observations. Experiments on REVERIE, R2R, and R2R-CE benchmarks demonstrate the efficiency of our event-centric strategy, outperforming state-of-the-art approaches across diverse action spaces. Our data and code are available on the project website https://sites.google.com/view/y-event-kg/.
Evaluating Semantic Variation in Text-to-Image Synthesis: A Causal Perspective
Oct 14, 2024
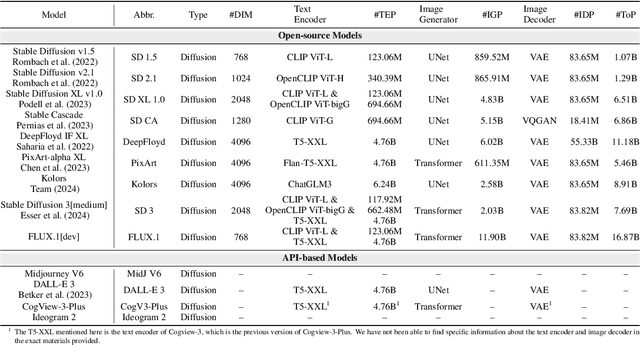
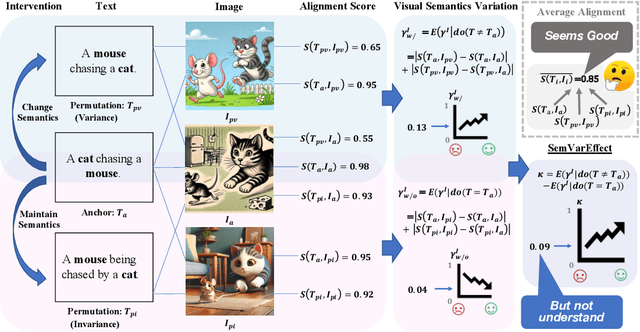
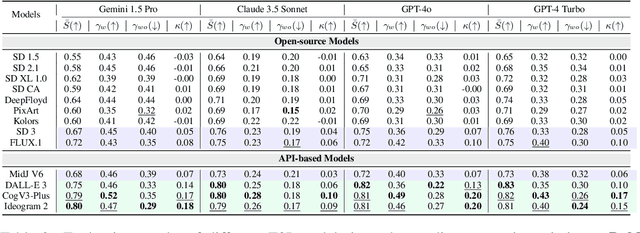
Accurate interpretation and visualization of human instructions are crucial for text-to-image (T2I) synthesis. However, current models struggle to capture semantic variations from word order changes, and existing evaluations, relying on indirect metrics like text-image similarity, fail to reliably assess these challenges. This often obscures poor performance on complex or uncommon linguistic patterns by the focus on frequent word combinations. To address these deficiencies, we propose a novel metric called SemVarEffect and a benchmark named SemVarBench, designed to evaluate the causality between semantic variations in inputs and outputs in T2I synthesis. Semantic variations are achieved through two types of linguistic permutations, while avoiding easily predictable literal variations. Experiments reveal that the CogView-3-Plus and Ideogram 2 performed the best, achieving a score of 0.2/1. Semantic variations in object relations are less understood than attributes, scoring 0.07/1 compared to 0.17-0.19/1. We found that cross-modal alignment in UNet or Transformers plays a crucial role in handling semantic variations, a factor previously overlooked by a focus on textual encoders. Our work establishes an effective evaluation framework that advances the T2I synthesis community's exploration of human instruction understanding.
3D Question Answering for City Scene Understanding
Jul 24, 20243D multimodal question answering (MQA) plays a crucial role in scene understanding by enabling intelligent agents to comprehend their surroundings in 3D environments. While existing research has primarily focused on indoor household tasks and outdoor roadside autonomous driving tasks, there has been limited exploration of city-level scene understanding tasks. Furthermore, existing research faces challenges in understanding city scenes, due to the absence of spatial semantic information and human-environment interaction information at the city level.To address these challenges, we investigate 3D MQA from both dataset and method perspectives. From the dataset perspective, we introduce a novel 3D MQA dataset named City-3DQA for city-level scene understanding, which is the first dataset to incorporate scene semantic and human-environment interactive tasks within the city. From the method perspective, we propose a Scene graph enhanced City-level Understanding method (Sg-CityU), which utilizes the scene graph to introduce the spatial semantic. A new benchmark is reported and our proposed Sg-CityU achieves accuracy of 63.94 % and 63.76 % in different settings of City-3DQA. Compared to indoor 3D MQA methods and zero-shot using advanced large language models (LLMs), Sg-CityU demonstrates state-of-the-art (SOTA) performance in robustness and generalization.
Multi-Task Domain Adaptation for Language Grounding with 3D Objects
Jul 03, 2024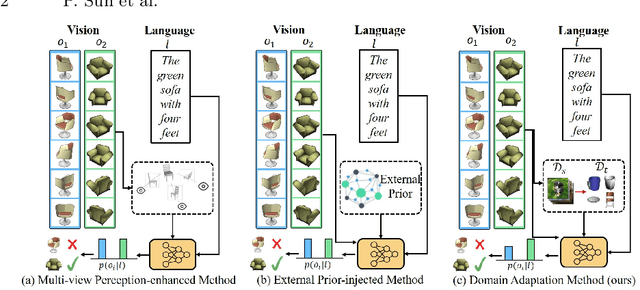
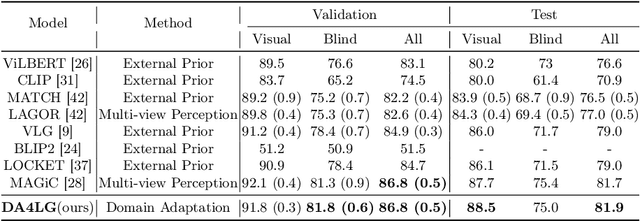
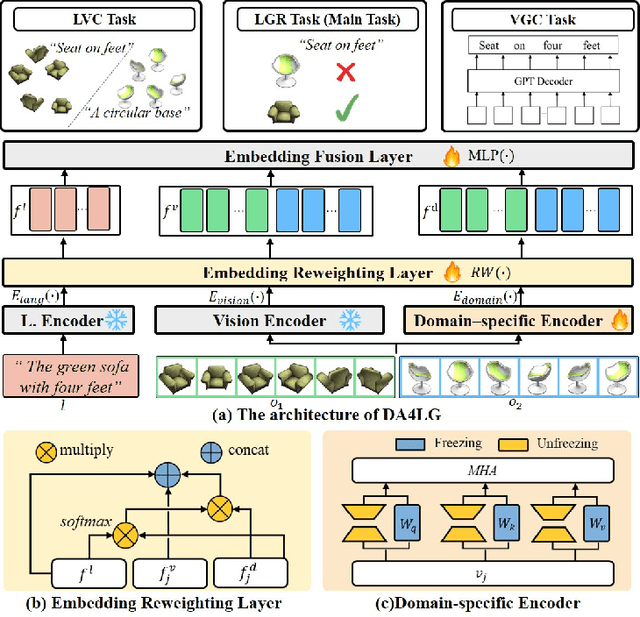
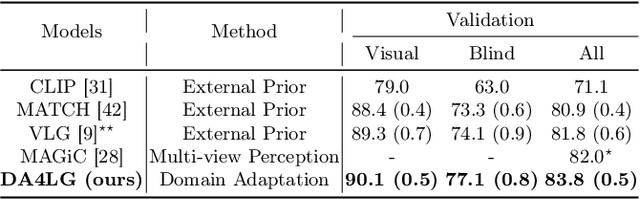
The existing works on object-level language grounding with 3D objects mostly focus on improving performance by utilizing the off-the-shelf pre-trained models to capture features, such as viewpoint selection or geometric priors. However, they have failed to consider exploring the cross-modal representation of language-vision alignment in the cross-domain field. To answer this problem, we propose a novel method called Domain Adaptation for Language Grounding (DA4LG) with 3D objects. Specifically, the proposed DA4LG consists of a visual adapter module with multi-task learning to realize vision-language alignment by comprehensive multimodal feature representation. Experimental results demonstrate that DA4LG competitively performs across visual and non-visual language descriptions, independent of the completeness of observation. DA4LG achieves state-of-the-art performance in the single-view setting and multi-view setting with the accuracy of 83.8% and 86.8% respectively in the language grounding benchmark SNARE. The simulation experiments show the well-practical and generalized performance of DA4LG compared to the existing methods. Our project is available at https://sites.google.com/view/da4lg.
Flickr30K-CFQ: A Compact and Fragmented Query Dataset for Text-image Retrieval
Apr 01, 2024With the explosive growth of multi-modal information on the Internet, unimodal search cannot satisfy the requirement of Internet applications. Text-image retrieval research is needed to realize high-quality and efficient retrieval between different modalities. Existing text-image retrieval research is mostly based on general vision-language datasets (e.g. MS-COCO, Flickr30K), in which the query utterance is rigid and unnatural (i.e. verbosity and formality). To overcome the shortcoming, we construct a new Compact and Fragmented Query challenge dataset (named Flickr30K-CFQ) to model text-image retrieval task considering multiple query content and style, including compact and fine-grained entity-relation corpus. We propose a novel query-enhanced text-image retrieval method using prompt engineering based on LLM. Experiments show that our proposed Flickr30-CFQ reveals the insufficiency of existing vision-language datasets in realistic text-image tasks. Our LLM-based Query-enhanced method applied on different existing text-image retrieval models improves query understanding performance both on public dataset and our challenge set Flickr30-CFQ with over 0.9% and 2.4% respectively. Our project can be available anonymously in https://sites.google.com/view/Flickr30K-cfq.
Learning 6-DoF Fine-grained Grasp Detection Based on Part Affordance Grounding
Jan 27, 2023Robotic grasping is a fundamental ability for a robot to interact with the environment. Current methods focus on how to obtain a stable and reliable grasping pose in object wise, while little work has been studied on part (shape)-wise grasping which is related to fine-grained grasping and robotic affordance. Parts can be seen as atomic elements to compose an object, which contains rich semantic knowledge and a strong correlation with affordance. However, lacking a large part-wise 3D robotic dataset limits the development of part representation learning and downstream application. In this paper, we propose a new large Language-guided SHape grAsPing datasEt (named Lang-SHAPE) to learn 3D part-wise affordance and grasping ability. We design a novel two-stage fine-grained robotic grasping network (named PIONEER), including a novel 3D part language grounding model, and a part-aware grasp pose detection model. To evaluate the effectiveness, we perform multi-level difficulty part language grounding grasping experiments and deploy our proposed model on a real robot. Results show our method achieves satisfactory performance and efficiency in reference identification, affordance inference, and 3D part-aware grasping. Our dataset and code are available on our project website https://sites.google.com/view/lang-shape
Human-in-the-loop Robotic Grasping using BERT Scene Representation
Sep 28, 2022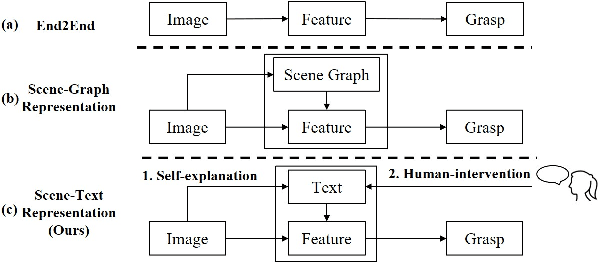
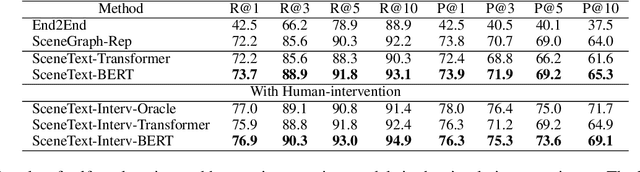
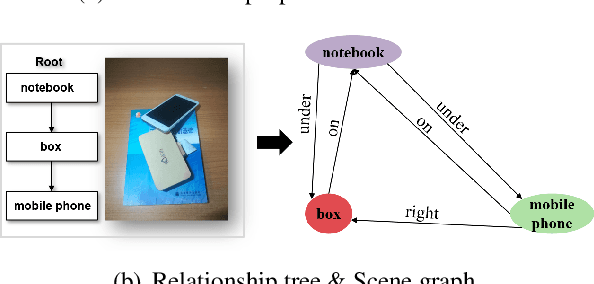
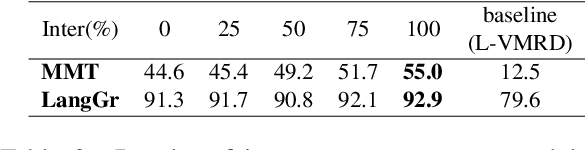
Current NLP techniques have been greatly applied in different domains. In this paper, we propose a human-in-the-loop framework for robotic grasping in cluttered scenes, investigating a language interface to the grasping process, which allows the user to intervene by natural language commands. This framework is constructed on a state-of-the-art rasping baseline, where we substitute a scene-graph representation with a text representation of the scene using BERT. Experiments on both simulation and physical robot show that the proposed method outperforms conventional object-agnostic and scene-graph based methods in the literature. In addition, we find that with human intervention, performance can be significantly improved.
Multimodal Aggregation Approach for Memory Vision-Voice Indoor Navigation with Meta-Learning
Sep 01, 2020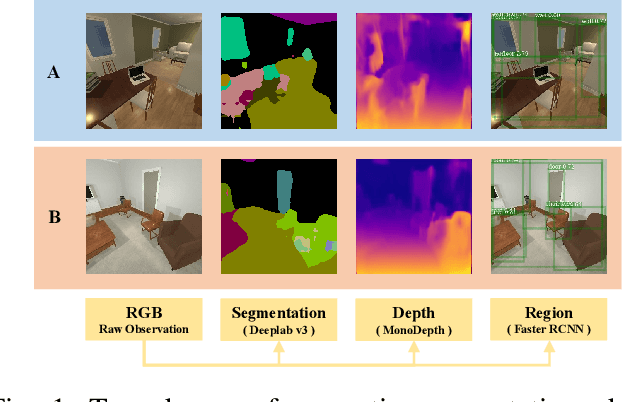
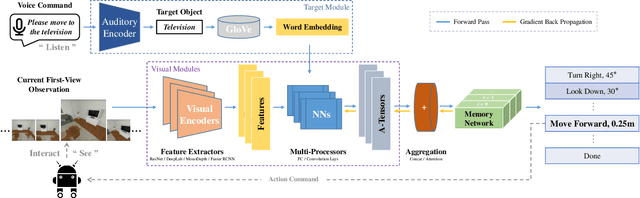
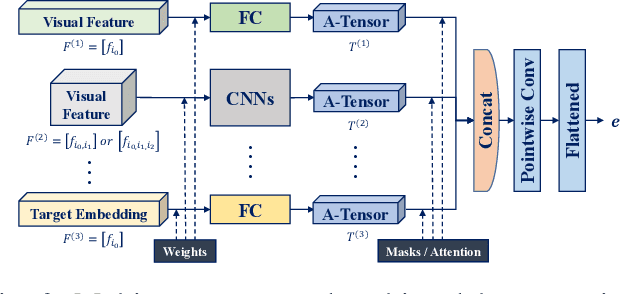
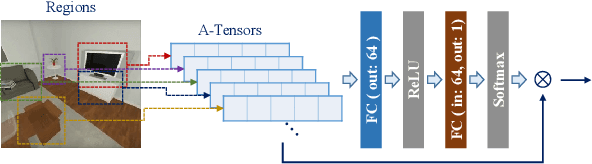
Vision and voice are two vital keys for agents' interaction and learning. In this paper, we present a novel indoor navigation model called Memory Vision-Voice Indoor Navigation (MVV-IN), which receives voice commands and analyzes multimodal information of visual observation in order to enhance robots' environment understanding. We make use of single RGB images taken by a first-view monocular camera. We also apply a self-attention mechanism to keep the agent focusing on key areas. Memory is important for the agent to avoid repeating certain tasks unnecessarily and in order for it to adapt adequately to new scenes, therefore, we make use of meta-learning. We have experimented with various functional features extracted from visual observation. Comparative experiments prove that our methods outperform state-of-the-art baselines.
Deep Robotic Prediction with hierarchical RGB-D Fusion
Sep 17, 2019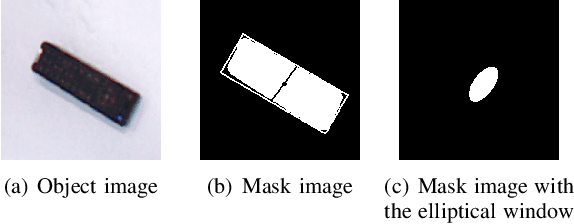
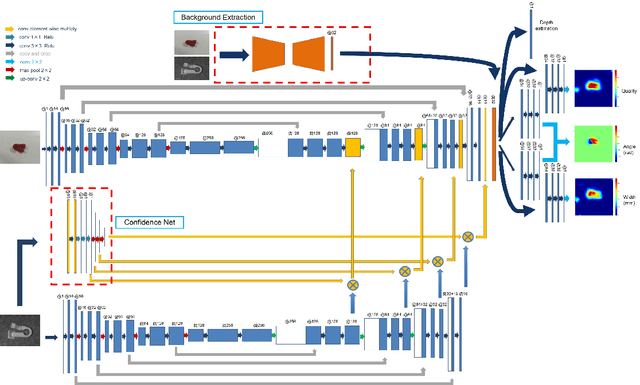


Robotic arm grasping is a fundamental operation in robotic control task goals. Most current methods for robotic grasping focus on RGB-D policy in the table surface scenario or 3D point cloud analysis and inference in the 3D space. Comparing to these methods, we propose a novel real-time multimodal hierarchical encoder-decoder neural network that fuses RGB and depth data to realize robotic humanoid grasping in 3D space with only partial observation. The quantification of raw depth data's uncertainty and depth estimation fusing RGB is considered. We develop a general labeling method to label ground-truth on common RGB-D datasets. We evaluate the effectiveness and performance of our method on a physical robot setup and our method achieves over 90\% success rate in both table surface and 3D space scenarios.