 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Quantum-Classical Spatiotemporal Forecasting for 3D Cloud Fields
Mar 31, 2026Accurate forecasting of three-dimensional (3D) cloud fields is important for atmospheric analysis and short-range numerical weather prediction, yet it remains challenging because cloud evolution involves cross-layer interactions, nonlocal dependencies, and multiscale spatiotemporal dynamics. Existing spatiotemporal prediction models based on convolutions, recurrence, or attention often rely on locality-biased representations and therefore struggle to preserve fine cloud structures in volumetric forecasting tasks. To address this issue, we propose QENO, a hybrid quantum-inspired spatiotemporal forecasting framework for 3D cloud fields. The proposed architecture consists of four components: a classical spatiotemporal encoder for compact latent representation, a topology-aware quantum enhancement block for modeling nonlocal couplings in latent space, a dynamic fusion temporal unit for integrating measurement-derived quantum features with recurrent memory, and a decoder for reconstructing future cloud volumes. Experiments on CMA-MESO 3D cloud fields show that QENO consistently outperforms representative baselines, including ConvLSTM, PredRNN++, Earthformer, TAU, and SimVP variants, in terms of MSE, MAE, RMSE, SSIM, and threshold-based detection metrics. In particular, QENO achieves an MSE of 0.2038, an RMSE of 0.4514, and an SSIM of 0.6291, while also maintaining a compact parameter budget. These results indicate that topology-aware hybrid quantum-classical feature modeling is a promising direction for 3D cloud structure forecasting and atmospheric Earth observation data analysis.
LGEST: Dynamic Spatial-Spectral Expert Routing for Hyperspectral Image Classification
Mar 25, 2026Deep learning methods, including Convolutional Neural Networks, Transformers and Mamba, have achieved remarkable success in hyperspectral image (HSI) classification. Nevertheless, existing methods exhibit inflexible integration of local-global representations, inadequate handling of spectral-spatial scale disparities across heterogeneous bands, and susceptibility to the Hughes phenomenon under high-dimensional sample heterogeneity. To address these challenges, we propose Local-Global Expert Spatial-Spectral Transformer (LGEST), a novel framework that synergistically combines three key innovations. The LGEST first employs a Deep Spatial-Spectral Autoencoder (DSAE) to generate compact yet discriminative embeddings through hierarchical nonlinear compression, preserving 3D neighborhood coherence while mitigating information loss in high-dimensional spaces. Secondly, a Cross-Interactive Mixed Expert Feature Pyramid (CIEM-FPN) leverages cross-attention mechanisms and residual mixture-of-experts layers to dynamically fuse multi-scale features, adaptively weighting spectral discriminability and spatial saliency through learnable gating functions. Finally, a Local-Global Expert System (LGES) processes decomposed features via sparsely activated expert pairs: convolutional sub-experts capture fine-grained textures, while transformer sub-experts model long-range contextual dependencies, with a routing controller dynamically selecting experts based on real-time feature saliency. Extensive experiments on four benchmark datasets demonstrate that LGEST consistently outperforms state-of-the-art methods.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
SGMAGNet: A Baseline Model for 3D Cloud Phase Structure Reconstruction on a New Passive Active Satellite Benchmark
Sep 19, 2025Cloud phase profiles are critical for numerical weather prediction (NWP), as they directly affect radiative transfer and precipitation processes. In this study, we present a benchmark dataset and a baseline framework for transforming multimodal satellite observations into detailed 3D cloud phase structures, aiming toward operational cloud phase profile retrieval and future integration with NWP systems to improve cloud microphysics parameterization. The multimodal observations consist of (1) high--spatiotemporal--resolution, multi-band visible (VIS) and thermal infrared (TIR) imagery from geostationary satellites, and (2) accurate vertical cloud phase profiles from spaceborne lidar (CALIOP\slash CALIPSO) and radar (CPR\slash CloudSat). The dataset consists of synchronized image--profile pairs across diverse cloud regimes, defining a supervised learning task: given VIS/TIR patches, predict the corresponding 3D cloud phase structure. We adopt SGMAGNet as the main model and compare it with several baseline architectures, including UNet variants and SegNet, all designed to capture multi-scale spatial patterns. Model performance is evaluated using standard classification metrics, including Precision, Recall, F1-score, and IoU. The results demonstrate that SGMAGNet achieves superior performance in cloud phase reconstruction, particularly in complex multi-layer and boundary transition regions. Quantitatively, SGMAGNet attains a Precision of 0.922, Recall of 0.858, F1-score of 0.763, and an IoU of 0.617, significantly outperforming all baselines across these key metrics.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
RSRWKV: A Linear-Complexity 2D Attention Mechanism for Efficient Remote Sensing Vision Task
Mar 26, 2025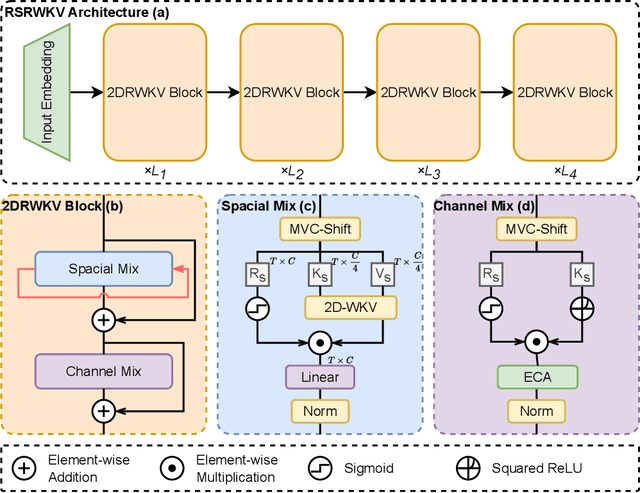



High-resolution remote sensing analysis faces challenges in global context modeling due to scene complexity and scale diversity. While CNNs excel at local feature extraction via parameter sharing, their fixed receptive fields fundamentally restrict long-range dependency modeling. Vision Transformers (ViTs) effectively capture global semantic relationships through self-attention mechanisms but suffer from quadratic computational complexity relative to image resolution, creating critical efficiency bottlenecks for high-resolution imagery. The RWKV model's linear-complexity sequence modeling achieves breakthroughs in NLP but exhibits anisotropic limitations in vision tasks due to its 1D scanning mechanism. To address these challenges, we propose RSRWKV, featuring a novel 2D-WKV scanning mechanism that bridges sequential processing and 2D spatial reasoning while maintaining linear complexity. This enables isotropic context aggregation across multiple directions. The MVC-Shift module enhances multi-scale receptive field coverage, while the ECA module strengthens cross-channel feature interaction and semantic saliency modeling. Experimental results demonstrate RSRWKV's superior performance over CNN and Transformer baselines in classification, detection, and segmentation tasks on NWPU RESISC45, VHR-10.v2, and GLH-Water datasets, offering a scalable solution for high-resolution remote sensing analysis.
DCT-Mamba3D: Spectral Decorrelation and Spatial-Spectral Feature Extraction for Hyperspectral Image Classification
Feb 04, 2025



Hyperspectral image classification presents challenges due to spectral redundancy and complex spatial-spectral dependencies. This paper proposes a novel framework, DCT-Mamba3D, for hyperspectral image classification. DCT-Mamba3D incorporates: (1) a 3D spectral-spatial decorrelation module that applies 3D discrete cosine transform basis functions to reduce both spectral and spatial redundancy, enhancing feature clarity across dimensions; (2) a 3D-Mamba module that leverages a bidirectional state-space model to capture intricate spatial-spectral dependencies; and (3) a global residual enhancement module that stabilizes feature representation, improving robustness and convergence. Extensive experiments on benchmark datasets show that our DCT-Mamba3D outperforms the state-of-the-art methods in challenging scenarios such as the same object in different spectra and different objects in the same spectra.
3D Question Answering for City Scene Understanding
Jul 24, 20243D multimodal question answering (MQA) plays a crucial role in scene understanding by enabling intelligent agents to comprehend their surroundings in 3D environments. While existing research has primarily focused on indoor household tasks and outdoor roadside autonomous driving tasks, there has been limited exploration of city-level scene understanding tasks. Furthermore, existing research faces challenges in understanding city scenes, due to the absence of spatial semantic information and human-environment interaction information at the city level.To address these challenges, we investigate 3D MQA from both dataset and method perspectives. From the dataset perspective, we introduce a novel 3D MQA dataset named City-3DQA for city-level scene understanding, which is the first dataset to incorporate scene semantic and human-environment interactive tasks within the city. From the method perspective, we propose a Scene graph enhanced City-level Understanding method (Sg-CityU), which utilizes the scene graph to introduce the spatial semantic. A new benchmark is reported and our proposed Sg-CityU achieves accuracy of 63.94 % and 63.76 % in different settings of City-3DQA. Compared to indoor 3D MQA methods and zero-shot using advanced large language models (LLMs), Sg-CityU demonstrates state-of-the-art (SOTA) performance in robustness and generalization.
Multi-Task Domain Adaptation for Language Grounding with 3D Objects
Jul 03, 2024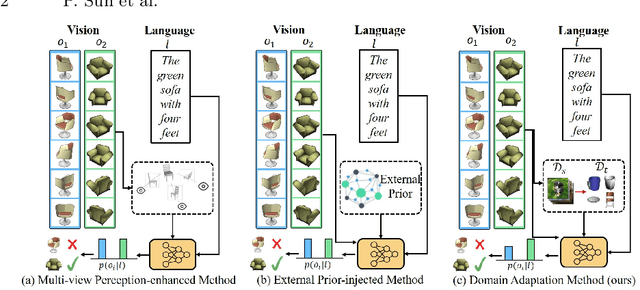
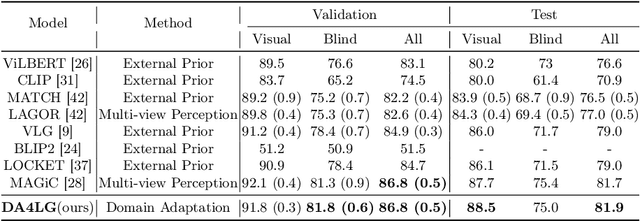
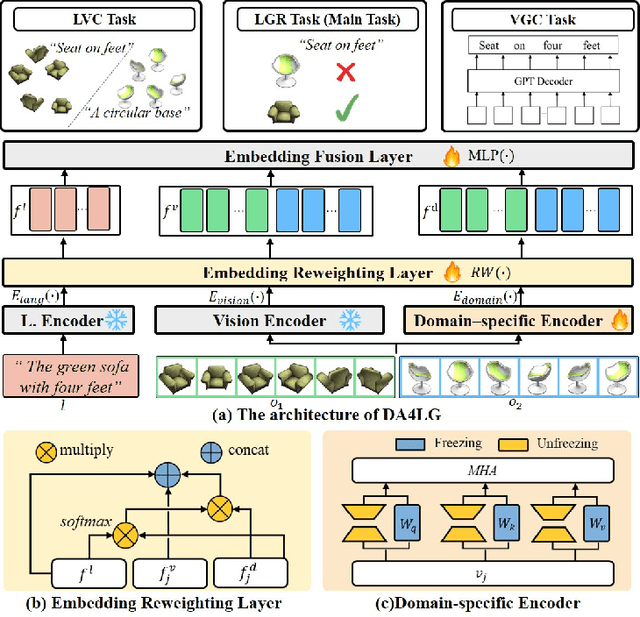
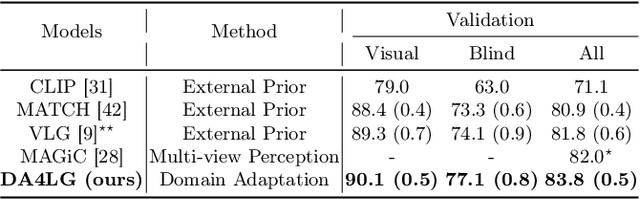
The existing works on object-level language grounding with 3D objects mostly focus on improving performance by utilizing the off-the-shelf pre-trained models to capture features, such as viewpoint selection or geometric priors. However, they have failed to consider exploring the cross-modal representation of language-vision alignment in the cross-domain field. To answer this problem, we propose a novel method called Domain Adaptation for Language Grounding (DA4LG) with 3D objects. Specifically, the proposed DA4LG consists of a visual adapter module with multi-task learning to realize vision-language alignment by comprehensive multimodal feature representation. Experimental results demonstrate that DA4LG competitively performs across visual and non-visual language descriptions, independent of the completeness of observation. DA4LG achieves state-of-the-art performance in the single-view setting and multi-view setting with the accuracy of 83.8% and 86.8% respectively in the language grounding benchmark SNARE. The simulation experiments show the well-practical and generalized performance of DA4LG compared to the existing methods. Our project is available at https://sites.google.com/view/da4lg.
FPS-Net: A Convolutional Fusion Network for Large-Scale LiDAR Point Cloud Segmentation
Mar 01, 2021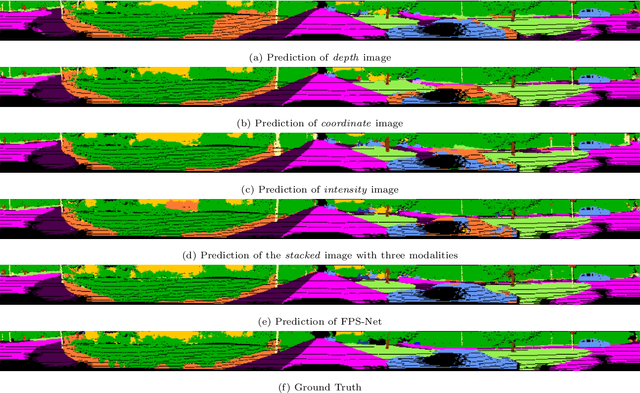


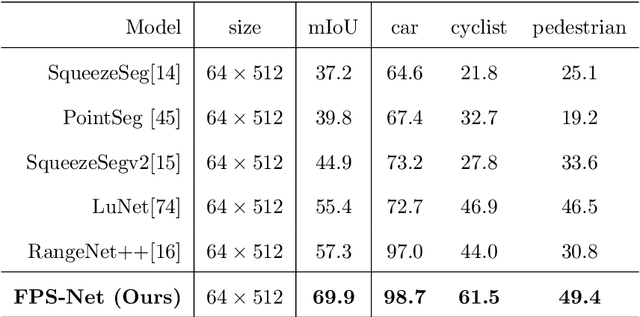
Scene understanding based on LiDAR point cloud is an essential task for autonomous cars to drive safely, which often employs spherical projection to map 3D point cloud into multi-channel 2D images for semantic segmentation. Most existing methods simply stack different point attributes/modalities (e.g. coordinates, intensity, depth, etc.) as image channels to increase information capacity, but ignore distinct characteristics of point attributes in different image channels. We design FPS-Net, a convolutional fusion network that exploits the uniqueness and discrepancy among the projected image channels for optimal point cloud segmentation. FPS-Net adopts an encoder-decoder structure. Instead of simply stacking multiple channel images as a single input, we group them into different modalities to first learn modality-specific features separately and then map the learned features into a common high-dimensional feature space for pixel-level fusion and learning. Specifically, we design a residual dense block with multiple receptive fields as a building block in the encoder which preserves detailed information in each modality and learns hierarchical modality-specific and fused features effectively. In the FPS-Net decoder, we use a recurrent convolution block likewise to hierarchically decode fused features into output space for pixel-level classification. Extensive experiments conducted on two widely adopted point cloud datasets show that FPS-Net achieves superior semantic segmentation as compared with state-of-the-art projection-based methods. In addition, the proposed modality fusion idea is compatible with typical projection-based methods and can be incorporated into them with consistent performance improvements.