 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbdominal Undulation with Compliant Mechanism Improves Flight Performance of Biomimetic Robotic Butterfly
Mar 09, 2025



Abdominal Undulation with Compliant Mechanism Improves Flight Performance of Biomimetic Robotic ButterflThis paper presents the design, modeling, and experimental validation of a biomimetic robotic butterfly (BRB) that integrates a compliant mechanism to achieve coupled wing-abdomen motion. Drawing inspiration from the natural f light dynamics of butterflies, a theoretical model is developed to investigate the impact of abdominal undulation on flight performance. To validate the model, motion capture experi ments are conducted on three configurations: a BRB without an abdomen, with a fixed abdomen, and with an undulating abdomen. The results demonstrate that abdominal undulation enhances lift generation, extends flight duration, and stabilizes pitch oscillations, thereby improving overall flight performance. These findings underscore the significance of wing-abdomen interaction in flapping-wing aerial vehicles (FWAVs) and lay the groundwork for future advancements in energy-efficient biomimetic flight designs.
3D Question Answering for City Scene Understanding
Jul 24, 20243D multimodal question answering (MQA) plays a crucial role in scene understanding by enabling intelligent agents to comprehend their surroundings in 3D environments. While existing research has primarily focused on indoor household tasks and outdoor roadside autonomous driving tasks, there has been limited exploration of city-level scene understanding tasks. Furthermore, existing research faces challenges in understanding city scenes, due to the absence of spatial semantic information and human-environment interaction information at the city level.To address these challenges, we investigate 3D MQA from both dataset and method perspectives. From the dataset perspective, we introduce a novel 3D MQA dataset named City-3DQA for city-level scene understanding, which is the first dataset to incorporate scene semantic and human-environment interactive tasks within the city. From the method perspective, we propose a Scene graph enhanced City-level Understanding method (Sg-CityU), which utilizes the scene graph to introduce the spatial semantic. A new benchmark is reported and our proposed Sg-CityU achieves accuracy of 63.94 % and 63.76 % in different settings of City-3DQA. Compared to indoor 3D MQA methods and zero-shot using advanced large language models (LLMs), Sg-CityU demonstrates state-of-the-art (SOTA) performance in robustness and generalization.
Multi-Task Domain Adaptation for Language Grounding with 3D Objects
Jul 03, 2024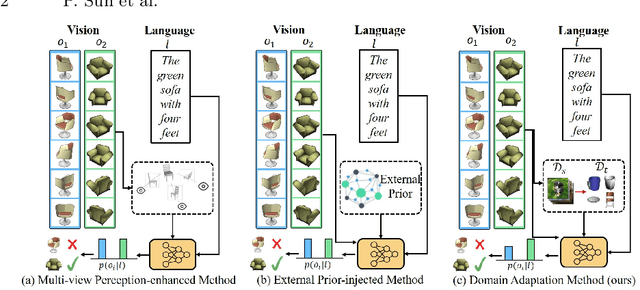
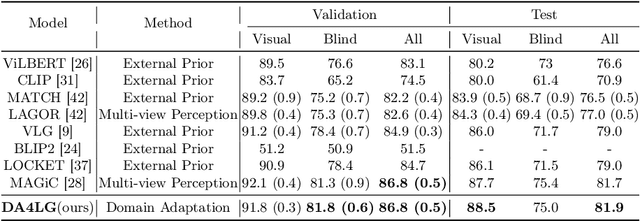
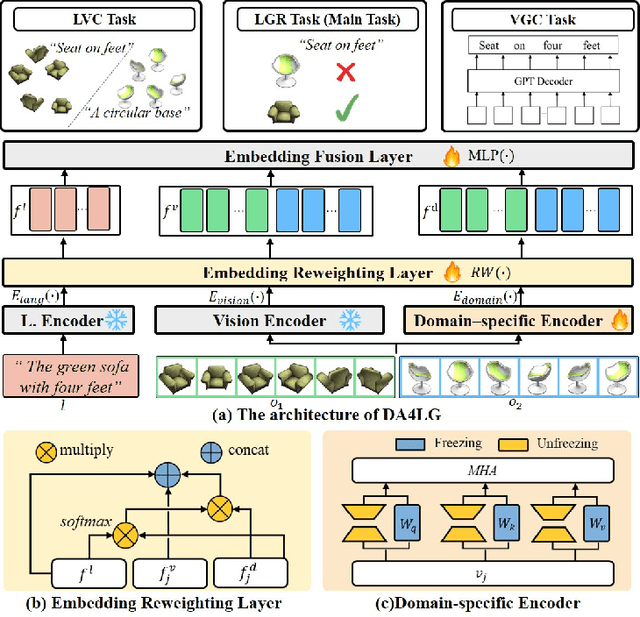
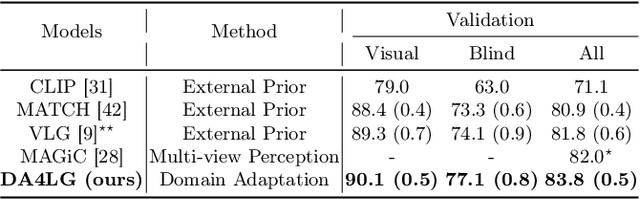
The existing works on object-level language grounding with 3D objects mostly focus on improving performance by utilizing the off-the-shelf pre-trained models to capture features, such as viewpoint selection or geometric priors. However, they have failed to consider exploring the cross-modal representation of language-vision alignment in the cross-domain field. To answer this problem, we propose a novel method called Domain Adaptation for Language Grounding (DA4LG) with 3D objects. Specifically, the proposed DA4LG consists of a visual adapter module with multi-task learning to realize vision-language alignment by comprehensive multimodal feature representation. Experimental results demonstrate that DA4LG competitively performs across visual and non-visual language descriptions, independent of the completeness of observation. DA4LG achieves state-of-the-art performance in the single-view setting and multi-view setting with the accuracy of 83.8% and 86.8% respectively in the language grounding benchmark SNARE. The simulation experiments show the well-practical and generalized performance of DA4LG compared to the existing methods. Our project is available at https://sites.google.com/view/da4lg.
Flickr30K-CFQ: A Compact and Fragmented Query Dataset for Text-image Retrieval
Apr 01, 2024With the explosive growth of multi-modal information on the Internet, unimodal search cannot satisfy the requirement of Internet applications. Text-image retrieval research is needed to realize high-quality and efficient retrieval between different modalities. Existing text-image retrieval research is mostly based on general vision-language datasets (e.g. MS-COCO, Flickr30K), in which the query utterance is rigid and unnatural (i.e. verbosity and formality). To overcome the shortcoming, we construct a new Compact and Fragmented Query challenge dataset (named Flickr30K-CFQ) to model text-image retrieval task considering multiple query content and style, including compact and fine-grained entity-relation corpus. We propose a novel query-enhanced text-image retrieval method using prompt engineering based on LLM. Experiments show that our proposed Flickr30-CFQ reveals the insufficiency of existing vision-language datasets in realistic text-image tasks. Our LLM-based Query-enhanced method applied on different existing text-image retrieval models improves query understanding performance both on public dataset and our challenge set Flickr30-CFQ with over 0.9% and 2.4% respectively. Our project can be available anonymously in https://sites.google.com/view/Flickr30K-cfq.
Minimum Snap Trajectory Generation and Control for an Under-actuated Flapping Wing Aerial Vehicle
Nov 02, 2023Minimum Snap Trajectory Generation and Control for an Under-actuated Flapping Wing Aerial VehicleThis paper presents both the trajectory generation and tracking control strategies for an underactuated flapping wing aerial vehicle (FWAV). First, the FWAV dynamics is analyzed in a practical perspective. Then, based on these analyses, we demonstrate the differential flatness of the FWAV system, and develop a general-purpose trajectory generation strategy. Subsequently, the trajectory tracking controller is developed with the help of robust control and switch control techniques. After that, the overall system asymptotic stability is guaranteed by Lyapunov stability analysis. To make the controller applicable in real flight, we also provide several instructions. Finally, a series of experiment results manifest the successful implementation of the proposed trajectory generation strategy and tracking control strategy. This work firstly achieves the closed-loop integration of trajectory generation and control for real 3-dimensional flight of an underactuated FWAV to a practical level.
Towards Practical Autonomous Flight Simulation for Flapping Wing Biomimetic Robots with Experimental Validation
Mar 08, 2023



Tried-and-true flapping wing robot simulation is essential in developing flapping wing mechanisms and algorithms. This paper presents a novel application-oriented flapping wing platform, highly compatible with various mechanical designs and adaptable to different robotic tasks. First, the blade element theory and the quasi-steady model are put forward to compute the flapping wing aerodynamics based on wing kinematics. Translational lift, translational drag, rotational lift, and added mass force are all considered in the computation. Then we use the proposed simulation platform to investigate the passive wing rotation and the wing-tail interaction phenomena of a particular flapping-wing robot. With the help of the simulation tool and a novel statistic based on dynamic differences from the averaged system, several behaviors display their essence by investigating the flapping wing robot dynamic characteristics. After that, the attitude tracking control problem and the positional trajectory tracking problem are both overcome by robust control techniques. Further comparison simulations reveal that the proposed control algorithms compared with other existing ones show apparent superiority. What is more, with the same control algorithm and parameters tuned in simulation, we conduct real flight experiments on a self-made flapping wing robot, and obtain similar results from the proposed simulation platform. In contrast to existing simulation tools, the proposed one is compatible with most existing flapping wing robots, and can inherently drill into each subtle behavior in corresponding applications by observing aerodynamic forces and torques on each blade element.
Multi-Modal Fusion in Contact-Rich Precise Tasks via Hierarchical Policy Learning
Feb 17, 2022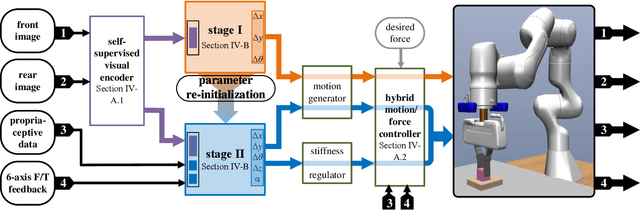

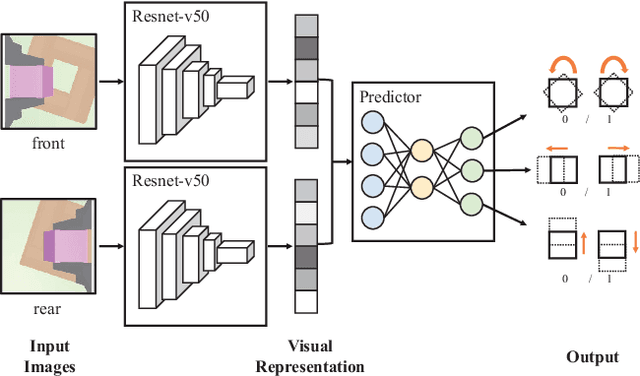
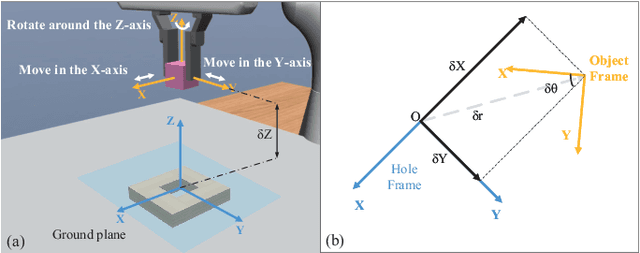
Combined visual and force feedback play an essential role in contact-rich robotic manipulation tasks. Current methods focus on developing the feedback control around a single modality while underrating the synergy of the sensors. Fusing different sensor modalities is necessary but remains challenging. A key challenge is to achieve an effective multi-modal and generalized control scheme to novel objects with precision. This paper proposes a practical multi-modal sensor fusion mechanism using hierarchical policy learning. To begin with, we use a self-supervised encoder that extracts multi-view visual features and a hybrid motion/force controller that regulates force behaviors. Next, the multi-modality fusion is simplified by hierarchical integration of the vision, force, and proprioceptive data in the reinforcement learning (RL) algorithm. Moreover, with hierarchical policy learning, the control scheme can exploit the visual feedback limits and explore the contribution of individual modality in precise tasks. Experiments indicate that robots with the control scheme could assemble objects with 0.25mm clearance in simulation. The system could be generalized to widely varied initial configurations and new shapes. Experiments validate that the simulated system can be robustly transferred to reality without fine-tuning.